FlowKV: Enhancing Multi-Turn Conversational Coherence in LLMs via Isolated Key-Value Cache Management
作者: Xiang Liu, Hong Chen, Xuming Hu, Xiaowen Chu
分类: cs.CL
发布日期: 2025-05-21 (更新: 2025-10-08)
备注: NeurIPS 2025 Workshop on Multi-Turn Interactions in Large Language Models
💡 一句话要点
FlowKV:通过隔离的键值缓存管理增强LLM中的多轮对话连贯性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多轮对话 键值缓存 缓存管理 上下文连贯性
📋 核心要点
- 现有LLM在多轮对话中,KV缓存随对话历史线性增长,导致计算成本高昂,且现有驱逐策略易造成信息丢失。
- FlowKV提出一种多轮隔离机制,保留过去轮次的压缩KV缓存,仅对最新轮次的新KV对进行压缩,避免重复压缩。
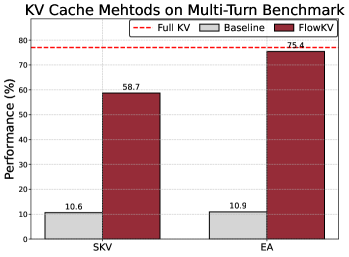
- 实验表明,FlowKV在指令遵循准确性和用户偏好保留方面显著优于基线策略,提升幅度高达75.40%。
📝 摘要(中文)
大型语言模型(LLM)越来越多地部署在多轮对话应用中,而键值(KV)缓存的管理是一个重要的瓶颈。KV缓存随着对话历史线性增长,带来了巨大的计算成本,并且现有的驱逐策略通常会通过重复压缩早期的对话上下文来降低性能,导致信息丢失和上下文遗忘。本文介绍了一种新颖的KV缓存管理多轮隔离机制FlowKV,它可以应用于任何KV缓存压缩方法而无需训练。FlowKV的核心创新是一种多轮隔离机制,可以保留来自过去轮次的累积压缩KV缓存。然后,压缩策略性地仅应用于最新完成轮次的新生成的KV对,从而有效地防止了旧上下文的重新压缩,从而减轻了灾难性遗忘。我们的结果表明,FlowKV在保持指令遵循准确性和用户偏好保留方面始终且显着地优于基线策略,提升幅度从10.90%到75.40%,尤其是在后期的对话轮次中。
🔬 方法详解
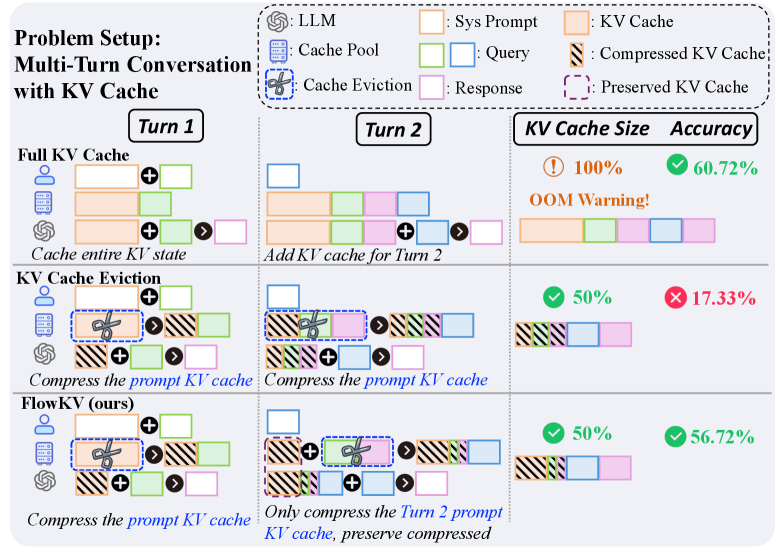
问题定义:在多轮对话场景下,大型语言模型(LLM)的KV缓存管理面临挑战。随着对话轮数的增加,KV缓存线性增长,导致计算和存储成本显著增加。现有的KV缓存压缩和驱逐策略,例如直接压缩整个KV缓存,容易导致早期对话上下文的重复压缩,从而造成信息丢失和上下文遗忘,降低了对话的连贯性和质量。
核心思路:FlowKV的核心思路是通过多轮隔离机制,将不同轮次的KV缓存进行隔离管理。具体来说,FlowKV保留之前轮次的累积压缩KV缓存,只对当前轮次新生成的KV对进行压缩。这样可以避免对早期上下文的重复压缩,从而减轻灾难性遗忘,保持对话的连贯性。
技术框架:FlowKV可以与现有的KV缓存压缩方法结合使用。其整体流程如下:1)接收到新的对话轮次输入;2)生成当前轮次的KV对;3)使用压缩方法压缩当前轮次的KV对;4)将压缩后的KV对与之前轮次的累积压缩KV缓存合并,形成新的累积压缩KV缓存;5)将新的累积压缩KV缓存用于后续的对话轮次。
关键创新:FlowKV的关键创新在于其多轮隔离机制。与现有方法不同,FlowKV不是对整个KV缓存进行统一压缩,而是将不同轮次的KV缓存进行隔离管理,只对当前轮次的新KV对进行压缩。这种方法可以有效地避免对早期上下文的重复压缩,从而减轻灾难性遗忘。
关键设计:FlowKV的设计关键在于如何有效地隔离不同轮次的KV缓存。具体实现上,FlowKV维护一个累积压缩KV缓存,用于存储之前轮次的压缩KV缓存。在每一轮对话中,FlowKV只对当前轮次新生成的KV对进行压缩,然后将压缩后的KV对与累积压缩KV缓存合并。这种设计可以有效地隔离不同轮次的KV缓存,避免对早期上下文的重复压缩。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FlowKV在保持指令遵循准确性和用户偏好保留方面显著优于基线策略。具体来说,FlowKV在某些任务上实现了高达75.40%的性能提升。实验还表明,FlowKV在对话的后期轮次中表现尤为出色,这表明FlowKV可以有效地减轻灾难性遗忘,保持对话的连贯性。
🎯 应用场景
FlowKV适用于各种需要保持多轮对话连贯性的应用场景,例如智能客服、聊天机器人、虚拟助手等。通过提高对话的连贯性和质量,FlowKV可以提升用户体验,并为LLM在实际应用中的部署提供更有效的KV缓存管理方案。该研究对于推动LLM在对话系统中的应用具有重要意义。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed in multi-turn conversational applications, where the management of the Key-Value (KV) Cache presents a significant bottleneck. The linear growth of the KV Cache with dialogue history imposes substantial computational costs, and existing eviction strategies often degrade performance by repeatedly compressing early conversational context, leading to information loss and context forgetting. This paper introduces FlowKV, a novel \textbf{multi-turn isolation mechanism} for KV Cache management, which can be applied to any KV Cache compression method without training. FlowKV's core innovation is a multi-turn isolation mechanism that preserves the accumulated compressed KV cache from past turns. Compression is then strategically applied only to the newly generated KV pairs of the latest completed turn, effectively preventing the re-compression of older context and thereby mitigating catastrophic forgetting. Our results demonstrate that FlowKV consistently and significantly outperforms baseline strategies in maintaining instruction-following accuracy and user preference retention from 10.90\% to 75.40\%, particularly in later conversational turns.