Hallucinate at the Last in Long Response Generation: A Case Study on Long Document Summarization
作者: Joonho Yang, Seunghyun Yoon, Hwan Chang, Byeongjeong Kim, Hwanhee Lee
分类: cs.CL
发布日期: 2025-05-21 (更新: 2026-01-13)
备注: 26 tables, 7 figures
💡 一句话要点
揭示长文本生成中幻觉的位置偏见:集中于末尾,并探索缓解方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 幻觉问题 位置偏见 长文档摘要 大型语言模型
📋 核心要点
- 现有长文本生成模型在生成长响应时,存在幻觉问题,尤其是在长文档摘要等任务中,模型容易生成与源文档不符的内容。
- 该研究发现幻觉并非均匀分布,而是集中在生成文本的后半部分,这可能与长序列上的注意力和解码动态有关。
- 论文探索了缓解这种位置幻觉的方法,旨在提高长输出结论部分的忠实性,从而提升长文本生成质量。
📝 摘要(中文)
大型语言模型(LLMs)在文本生成能力方面取得了显著进展,包括摘要生成等任务,通常能产生连贯流畅的输出。然而,由于幻觉的产生,对源材料的忠实性仍然是一个重大挑战。虽然大量的研究集中在检测和减少这些不准确之处,但较少关注生成的文本中幻觉的位置分布,尤其是在长输出中。本文以长文档摘要为案例,研究了基于LLM的长响应生成中幻觉发生的位置。在长上下文感知的长响应生成的具有挑战性的环境中,我们发现了一个一致且令人担忧的现象:幻觉倾向于不成比例地集中在生成的长响应的后半部分。为了理解这种偏差,我们探讨了与长序列上的注意力和解码动态相关的潜在影响因素。此外,我们研究了减轻这种位置幻觉的方法,旨在提高长输出结论部分的忠实性。
🔬 方法详解
问题定义:论文旨在解决长文本生成任务中,特别是长文档摘要任务中,大型语言模型(LLMs)产生的幻觉问题。现有方法虽然致力于检测和减少幻觉,但忽略了幻觉在生成文本中的位置分布,尤其是在长文本输出的末尾部分,幻觉现象更为严重。这种位置偏见导致长文本摘要的结尾部分可信度降低。
核心思路:论文的核心思路是深入分析长文本生成过程中幻觉的位置分布,发现幻觉集中在生成文本末尾的现象,并探究其潜在原因,例如注意力机制在长序列上的衰减以及解码过程中的误差累积。基于对原因的理解,设计相应的缓解策略,提高生成文本末尾部分的忠实性。
技术框架:该研究主要通过实验分析来揭示幻觉的位置分布规律。首先,使用LLM生成长文档摘要。然后,通过某种幻觉检测方法(论文中未明确指出具体方法,属于未知信息)标注生成文本中的幻觉。最后,统计幻觉在生成文本不同位置的分布情况,验证幻觉集中在末尾的假设。此外,论文还探索了缓解策略,但具体的技术框架和模块未在摘要中详细描述。
关键创新:该研究最重要的创新点在于发现了长文本生成中幻觉的位置偏见,即幻觉集中在生成文本的末尾。这一发现挑战了以往对幻觉的认知,为后续研究提供了新的视角。以往的研究主要关注如何检测和减少幻觉,而忽略了幻觉的位置分布。
关键设计:论文的关键设计在于实验分析方法,通过统计幻觉在生成文本不同位置的分布情况,验证了幻觉的位置偏见。虽然摘要中没有给出具体的参数设置、损失函数或网络结构等技术细节,但可以推断,缓解策略的设计可能涉及到对注意力机制的改进,或者对解码过程的约束,以减少末尾部分的误差累积。(具体细节未知)
🖼️ 关键图片
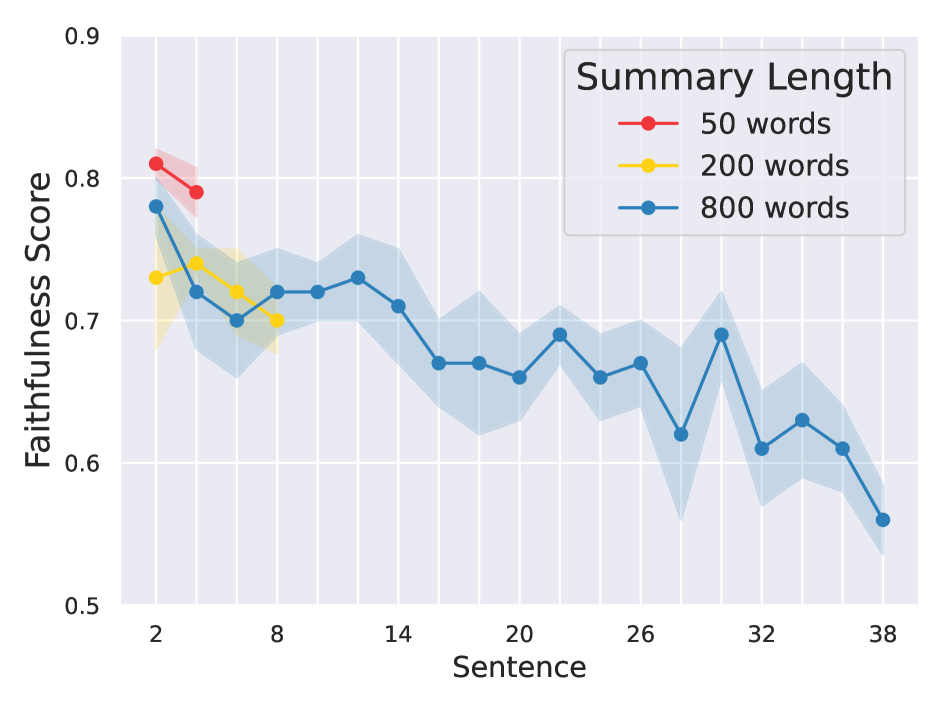
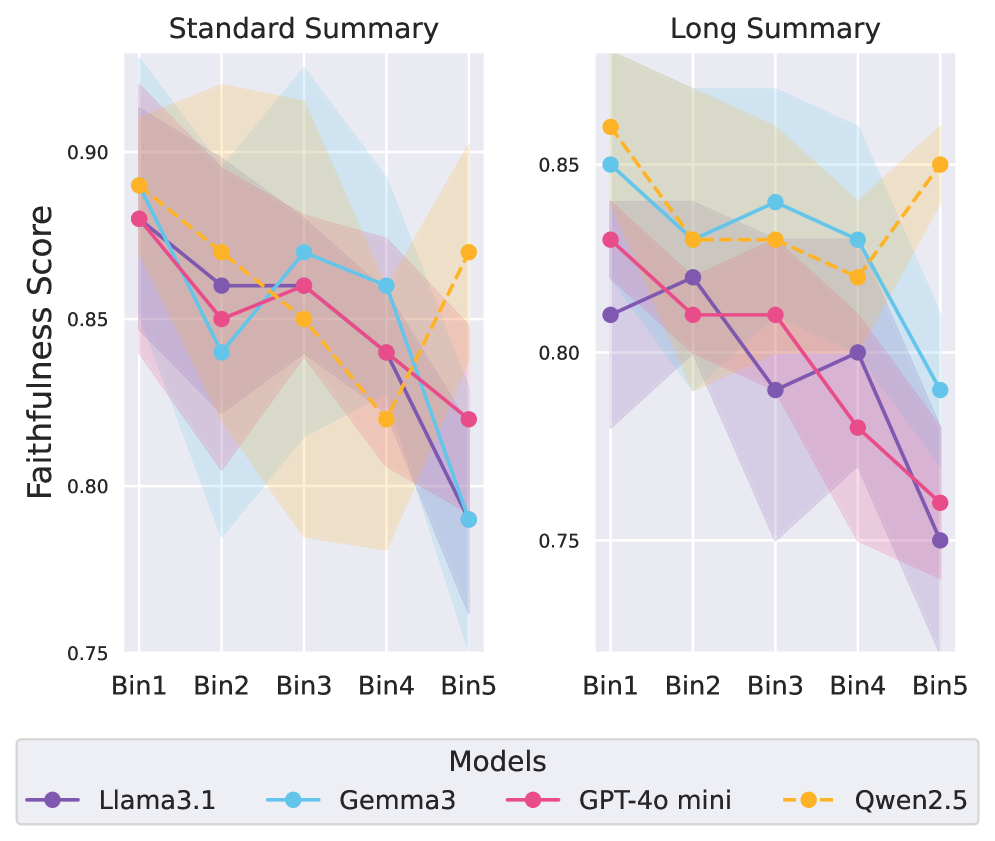
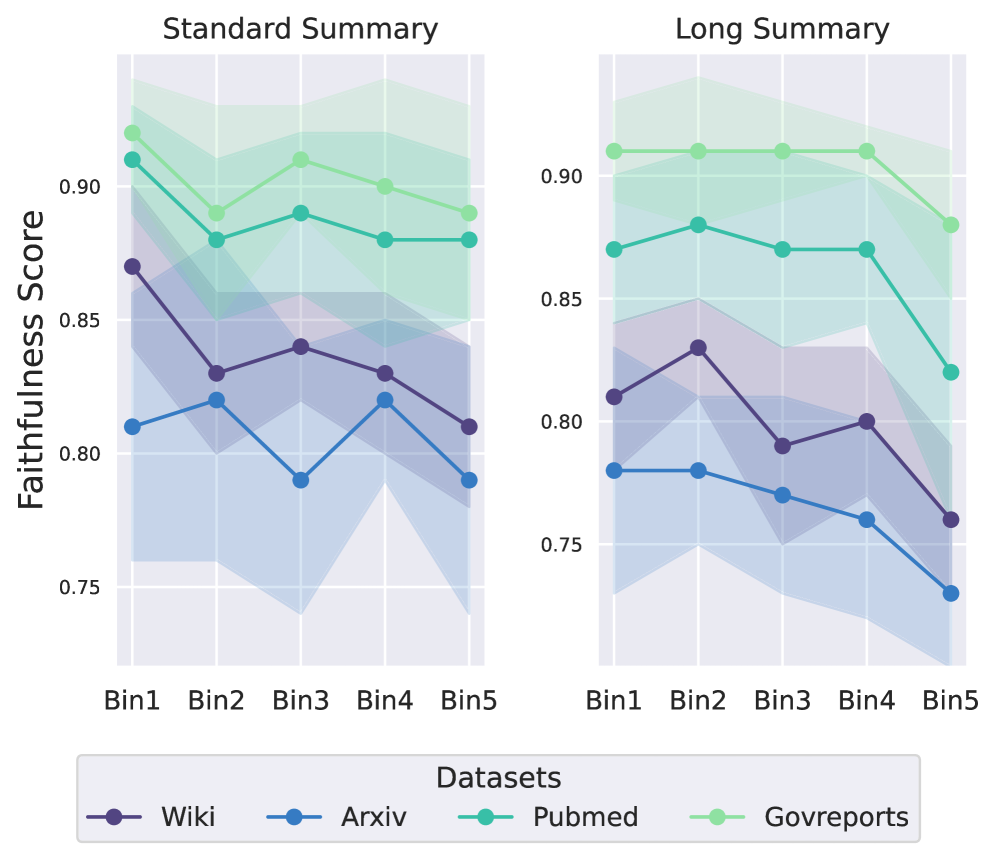
📊 实验亮点
该研究的主要发现是,在长文档摘要任务中,基于LLM生成的长文本响应中,幻觉不成比例地集中在文本的后半部分。虽然摘要中没有提供具体的性能数据和提升幅度,但这一发现为后续研究提供了重要的指导,并为缓解长文本生成中的幻觉问题提供了新的思路。
🎯 应用场景
该研究成果可应用于各种长文本生成场景,例如长文档摘要、报告生成、小说创作等。通过减少长文本末尾部分的幻觉,可以提高生成文本的质量和可信度,提升用户体验。此外,该研究也为LLM的改进提供了新的方向,即在训练过程中更加关注长文本末尾部分的生成质量。
📄 摘要(原文)
Large Language Models (LLMs) have significantly advanced text generation capabilities, including tasks like summarization, often producing coherent and fluent outputs. However, faithfulness to source material remains a significant challenge due to the generation of hallucinations. While extensive research focuses on detecting and reducing these inaccuracies, less attention has been paid to the positional distribution of hallucination within generated text, particularly in long outputs. In this work, we investigate where hallucinations occur in LLM-based long response generation, using long document summarization as a key case study. Focusing on the challenging setting of long context-aware long response generation, we find a consistent and concerning phenomenon: hallucinations tend to concentrate disproportionately in the latter parts of the generated long response. To understand this bias, we explore potential contributing factors related to the dynamics of attention and decoding over long sequences. Furthermore, we investigate methods to mitigate this positional hallucination, aiming to improve faithfulness specifically in the concluding segments of long outputs.