Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
作者: Hyungjoo Chae, Sunghwan Kim, Junhee Cho, Seungone Kim, Seungjun Moon, Gyeom Hwangbo, Dongha Lim, Minjin Kim, Yeonjun Hwang, Minju Gwak, Dongwook Choi, Minseok Kang, Gwanhoon Im, ByeongUng Cho, Hyojun Kim, Jun Hee Han, Taeyoon Kwon, Minju Kim, Beong-woo Kwak, Dongjin Kang, Jinyoung Yeo
分类: cs.CL
发布日期: 2025-05-21 (更新: 2025-11-25)
备注: NeurIPS 2025 Spotlight
💡 一句话要点
Web-Shepherd:提出用于增强Web代理的流程奖励模型,解决Web导航任务缺乏专用奖励模型的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web导航 流程奖励模型 强化学习 Web代理 奖励模型
📋 核心要点
- 现有Web导航任务缺乏专用奖励模型,导致训练和测试效率低下,且依赖昂贵的多模态大语言模型。
- Web-Shepherd提出一种流程奖励模型(PRM),通过步进式评估Web导航轨迹,降低成本并提高效率。
- 实验表明,Web-Shepherd在准确率和成本效益方面优于GPT-4o等模型,并在WebArena-lite上取得了显著性能提升。
📝 摘要(中文)
Web导航是一个独特的领域,可以自动化许多重复的现实生活任务,并且具有挑战性,因为它需要超越典型的多模态大型语言模型(MLLM)任务的长程序列决策。然而,直到现在,一直缺乏可用于训练和测试的Web导航专用奖励模型。尽管速度和成本效益非常重要,但先前的工作已将MLLM用作奖励模型,这对实际部署构成了重大限制。为了解决这个问题,在这项工作中,我们提出了第一个流程奖励模型(PRM),称为Web-Shepherd,它可以评估Web导航轨迹的步进级别。为此,我们首先构建了WebPRM Collection,这是一个大规模数据集,包含40K步进级别的偏好对和涵盖各种领域和难度级别的带注释的清单。接下来,我们还介绍了WebRewardBench,这是第一个用于评估PRM的元评估基准。在我们的实验中,我们观察到,与在WebRewardBench上使用GPT-4o相比,我们的Web-Shepherd实现了大约30分的更高准确率。此外,通过使用GPT-4o-mini作为策略和Web-Shepherd作为验证器在WebArena-lite上进行测试时,与使用GPT-4o-mini作为验证器相比,我们实现了高10.9分的性能,成本降低了10。我们的模型、数据集和代码可在LINK公开获得。
🔬 方法详解
问题定义:Web导航任务需要长程序列决策,现有方法依赖于多模态大型语言模型(MLLM)作为奖励模型,计算成本高昂,速度慢,难以实际部署。缺乏专门为Web导航设计的、高效的奖励模型是主要痛点。
核心思路:论文的核心思路是设计一个流程奖励模型(PRM),Web-Shepherd,它能够以步进的方式评估Web导航轨迹。通过分解复杂的导航任务为一系列步骤,并对每个步骤进行评估,可以更精确地指导Web代理的学习过程,同时降低计算成本。
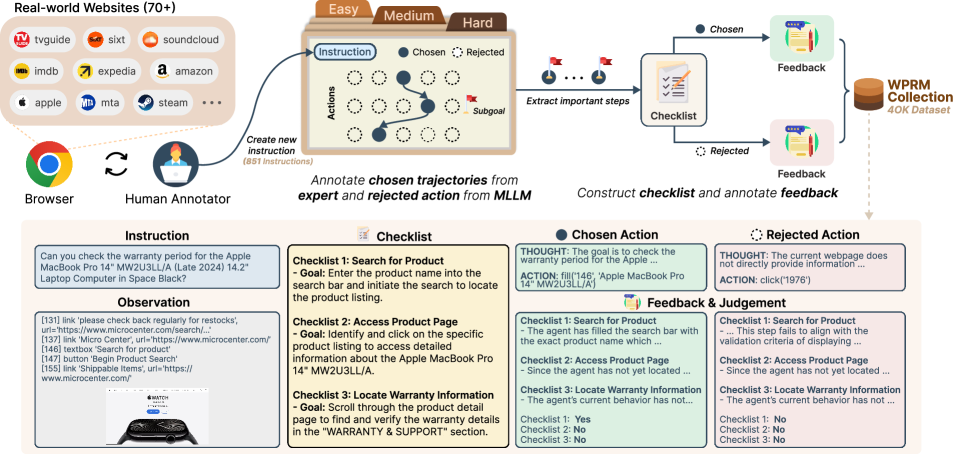
技术框架:Web-Shepherd的整体框架包括以下几个关键部分:1) WebPRM Collection:一个大规模的步进级别偏好数据集,用于训练奖励模型。2) WebRewardBench:一个元评估基准,用于评估不同的PRM。3) Web-Shepherd模型本身:一个用于评估Web导航轨迹的PRM。该模型接收Web代理的动作序列和相应的环境状态作为输入,输出每个步骤的奖励值。
关键创新:最重要的技术创新在于提出了流程奖励模型(PRM)的概念,并将其应用于Web导航任务。与传统的端到端奖励模型相比,PRM能够提供更细粒度的反馈,从而更有效地指导Web代理的学习。此外,WebPRM Collection和WebRewardBench的构建也为该领域的研究提供了宝贵的数据资源和评估工具。
关键设计:WebPRM Collection包含40K步进级别的偏好对,这些偏好对由人工标注,涵盖了各种领域和难度级别。WebRewardBench包含一系列评估任务,用于评估PRM的准确率、效率和泛化能力。Web-Shepherd模型的具体网络结构未知,但可以推测其可能采用了Transformer或其他序列模型,以捕捉Web导航轨迹中的依赖关系。损失函数的设计目标是使模型能够准确预测人工标注的偏好。
🖼️ 关键图片


📊 实验亮点
Web-Shepherd在WebRewardBench上比GPT-4o的准确率高出约30个百分点。在WebArena-lite上,使用GPT-4o-mini作为策略,Web-Shepherd作为验证器,相比于使用GPT-4o-mini作为验证器,性能提升了10.9分,且成本降低了10倍。这些结果表明Web-Shepherd在准确率和成本效益方面具有显著优势。
🎯 应用场景
Web-Shepherd具有广泛的应用前景,可用于自动化各种Web任务,例如在线购物、数据抓取、信息检索等。通过提供高效的奖励信号,它可以显著提升Web代理的性能和效率,降低人工干预的需求,并最终实现更智能、更自主的Web自动化。
📄 摘要(原文)
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.