When Less Language is More: Language-Reasoning Disentanglement Makes LLMs Better Multilingual Reasoners
作者: Weixiang Zhao, Jiahe Guo, Yang Deng, Tongtong Wu, Wenxuan Zhang, Yulin Hu, Xingyu Sui, Yanyan Zhao, Wanxiang Che, Bing Qin, Tat-Seng Chua, Ting Liu
分类: cs.CL
发布日期: 2025-05-21 (更新: 2025-12-11)
备注: NeurIPS 2025 Camera-ready
💡 一句话要点
提出语言-推理解耦方法,提升大语言模型的多语言推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言推理 语言模型 因果干预 表示解耦 跨语言泛化
📋 核心要点
- 现有LLM在多语言推理上表现不佳,尤其是在低资源语言上,这限制了其跨语言应用。
- 该研究提出解耦LLM中的语言和推理表示,通过消融语言特定信息来提升推理能力。
- 实验表明,该方法在多种语言和模型上均有效,且计算开销小,优于或可比于微调方法。
📝 摘要(中文)
多语言推理对于大型语言模型(LLMs)来说仍然是一个重要的挑战,其性能不成比例地偏向于高资源语言。受认知神经科学的启发,该研究假设LLMs以可分离的组件形式编码推理和语言,这些组件可以被解耦以增强多语言推理。为了评估这一点,该研究通过在推理时消融特定于语言的表示来进行因果干预。在涵盖11种类型多样的语言的10个开放权重LLM上的实验表明,这种特定于语言的消融始终能提高多语言推理性能。分层分析进一步证实,语言和推理表示可以在整个模型中有效地解耦,从而提高多语言推理能力,同时保留顶层语言特征对于维持语言保真度至关重要。与监督微调或强化学习等后训练方法相比,该研究的免训练语言-推理解耦以最小的计算开销实现了可比或优越的结果。这些发现揭示了LLMs中多语言推理的内部机制,并提出了一种轻量级且可解释的策略来改进跨语言泛化。
🔬 方法详解
问题定义:大型语言模型在多语言推理任务中表现不平衡,高资源语言性能远超低资源语言。现有方法如微调等计算成本高昂,且可能引入新的偏差。因此,如何提升LLM在多语言环境下的推理能力,同时降低计算成本,是本文要解决的核心问题。
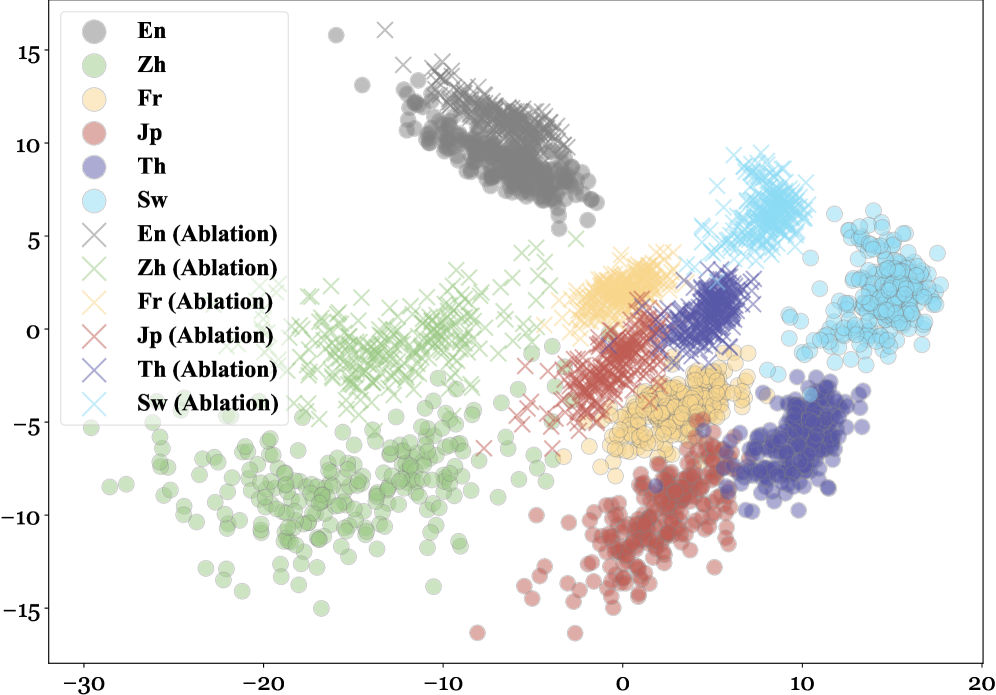
核心思路:借鉴认知神经科学的发现,认为人类的推理能力与语言处理相对独立。论文假设LLM内部也存在可分离的语言和推理表示,通过干预语言表示,可以提升模型的推理能力。核心在于找到并消融模型中特定于语言的表示,从而迫使模型更多地依赖通用的推理能力。
技术框架:该研究采用因果干预的方法,具体来说,是在推理阶段对LLM的中间层进行语言特定表示的消融。首先,确定模型中哪些层包含更多的语言信息。然后,在这些层中,通过某种方式(例如,设置激活值为零)来移除或减少语言相关的信息。最后,评估模型在多语言推理任务上的表现。整个过程无需训练,属于一种“免训练”的方法。
关键创新:该研究的关键创新在于提出了语言-推理解耦的思路,并将其应用于提升LLM的多语言推理能力。与传统的微调方法不同,该方法不需要额外的训练数据和计算资源,而是通过对模型内部表示进行干预来实现性能提升。这种方法具有轻量级、可解释性强的优点。
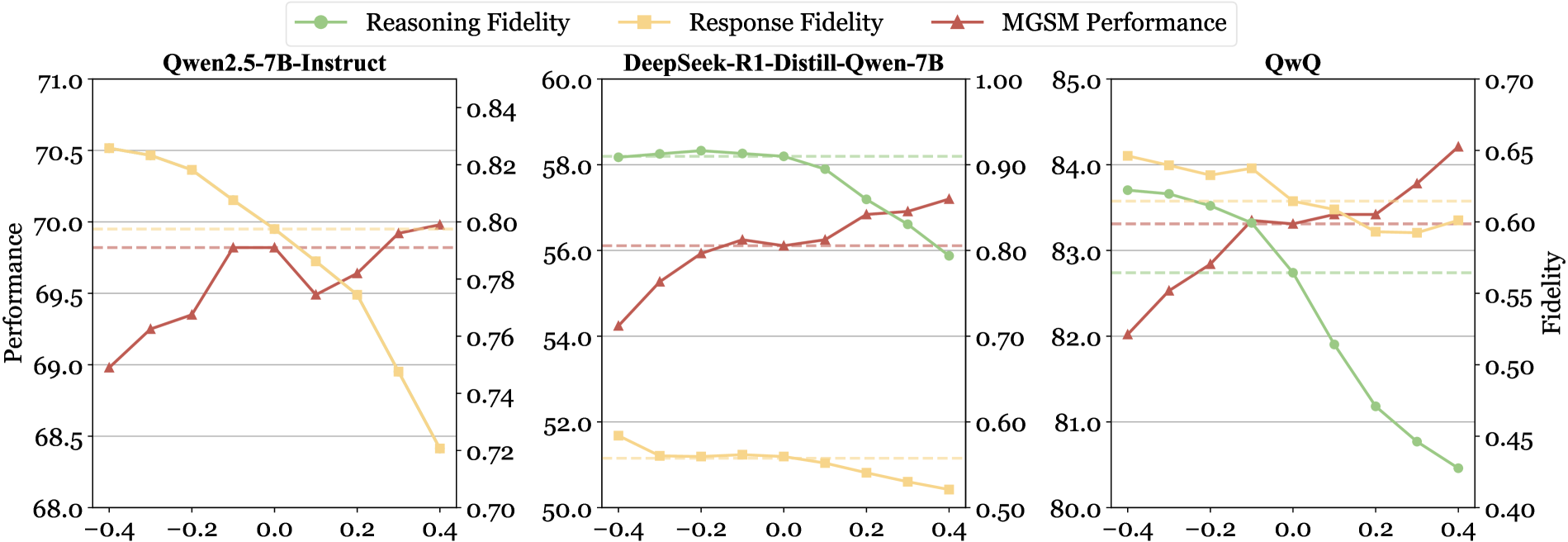
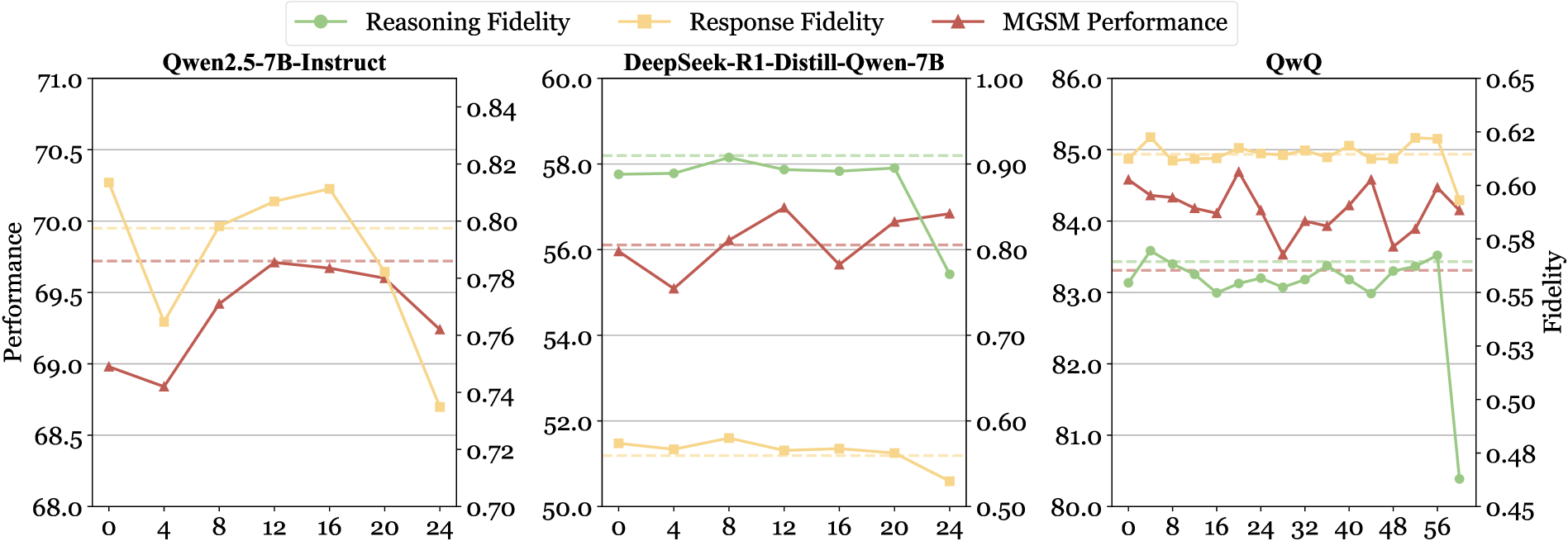
关键设计:论文的关键设计在于如何有效地消融语言特定表示。具体来说,研究者通过分析不同层对语言和推理任务的贡献,确定需要干预的层。然后,采用简单的激活值置零方法来移除语言信息。此外,研究还发现,保留顶层的语言特征对于保持语言的流畅性至关重要。具体的参数设置和网络结构取决于所使用的LLM。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该研究提出的语言-推理解耦方法能够显著提升LLM在多语言推理任务上的性能。在10个开放权重LLM和11种语言上的实验表明,该方法始终能提高多语言推理性能。与监督微调或强化学习等后训练方法相比,该方法以最小的计算开销实现了可比或优越的结果。
🎯 应用场景
该研究成果可应用于各种需要多语言推理的场景,例如跨语言信息检索、机器翻译、多语言问答系统等。通过提升LLM在低资源语言上的推理能力,可以促进语言资源的公平分配,并为全球用户提供更优质的AI服务。此外,该方法还可以作为一种通用的模型优化策略,应用于其他多语言任务。
📄 摘要(原文)
Multilingual reasoning remains a significant challenge for large language models (LLMs), with performance disproportionately favoring high-resource languages. Drawing inspiration from cognitive neuroscience, which suggests that human reasoning functions largely independently of language processing, we hypothesize that LLMs similarly encode reasoning and language as separable components that can be disentangled to enhance multilingual reasoning. To evaluate this, we perform a causal intervention by ablating language-specific representations at inference time. Experiments on 10 open-weight LLMs spanning 11 typologically diverse languages show that this language-specific ablation consistently boosts multilingual reasoning performance. Layer-wise analyses further confirm that language and reasoning representations can be effectively disentangled throughout the model, yielding improved multilingual reasoning capabilities, while preserving top-layer language features remains essential for maintaining linguistic fidelity. Compared to post-training methods such as supervised fine-tuning or reinforcement learning, our training-free language-reasoning disentanglement achieves comparable or superior results with minimal computational overhead. These findings shed light on the internal mechanisms underlying multilingual reasoning in LLMs and suggest a lightweight and interpretable strategy for improving cross-lingual generalization.