Mechanistic evaluation of Transformers and state space models
作者: Aryaman Arora, Neil Rathi, Nikil Roashan Selvam, Róbert Csordás, Dan Jurafsky, Christopher Potts
分类: cs.CL, cs.AI
发布日期: 2025-05-21 (更新: 2025-06-07)
备注: 9 page main text, 6 pages appendix
💡 一句话要点
通过因果干预,揭示Transformer和状态空间模型在关联回忆任务中的机制差异
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型 状态空间模型 Transformer 因果干预 机制性评估
📋 核心要点
- 现有语言模型在关联回忆等任务上表现差异大,缺乏对模型内部机制的深入理解。
- 论文通过因果干预,分析Transformer和状态空间模型在关联回忆任务中的信息存储和处理方式。
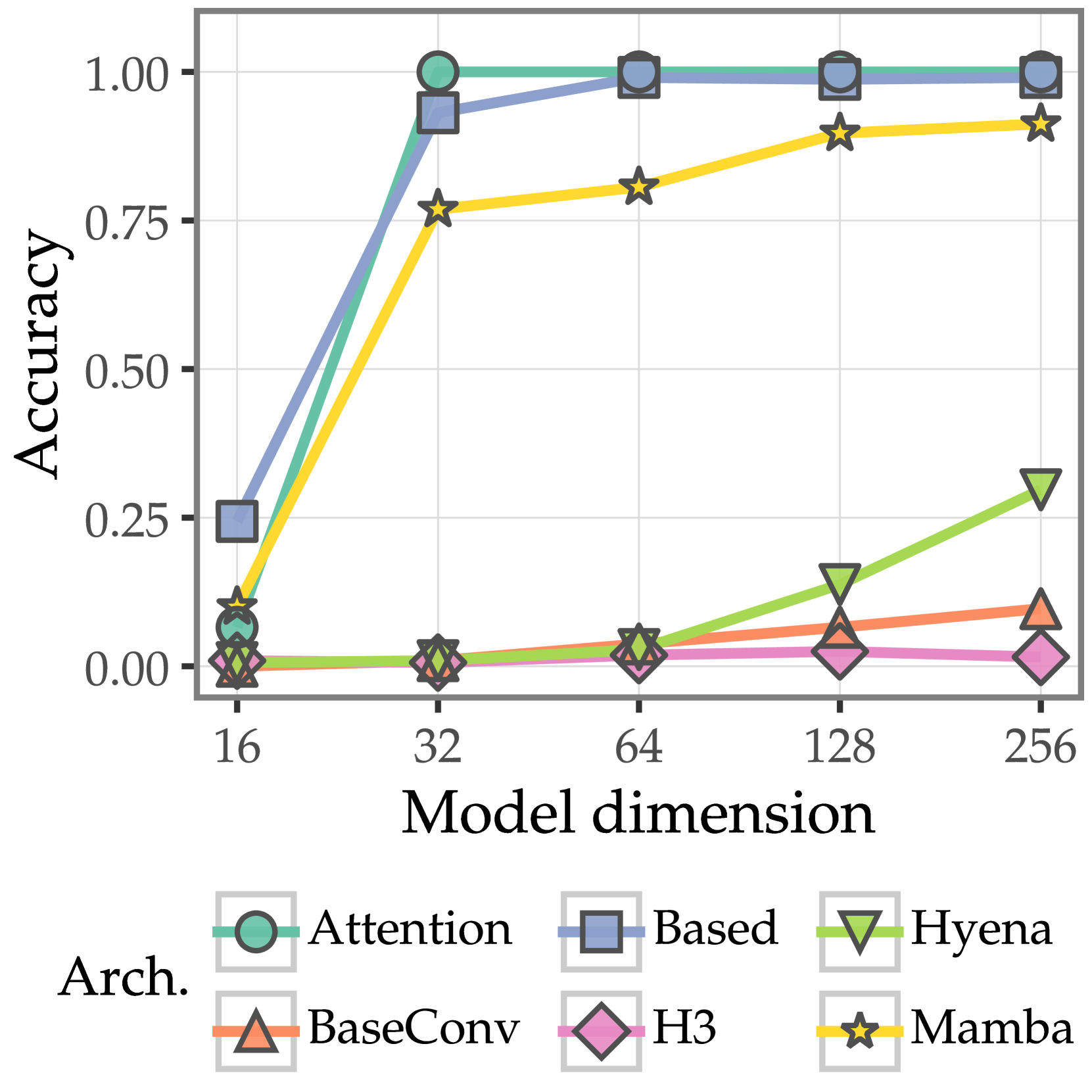
- 实验表明,Transformer通过归纳头存储键值对,而SSM仅在最后状态计算关联,Mamba因卷积结构表现较好。
📝 摘要(中文)
状态空间模型(SSMs)在语言建模领域,有望成为Transformer的一种高效且高性能的替代方案,但在回忆上下文中的基本信息时,表现出不稳定的性能。虽然在诸如关联回忆(AR)之类的合成任务上的表现可以指出这种缺陷,但行为指标几乎没有提供关于为什么某些架构失败而另一些架构成功的原因的机制层面的信息。为了解决这个问题,我们对AR进行了实验,发现只有Transformer和基于Transformer的SSM模型完全成功,Mamba紧随其后,而其他SSM(H3, Hyena)则失败了。然后,我们使用因果干预来解释原因。我们发现Transformer和基于Transformer的模型学会使用归纳头在上下文中存储键值关联。相比之下,SSM仅在最后状态计算这些关联,只有Mamba由于其短卷积组件而成功。为了扩展和加深这些发现,我们引入了关联树调用(ATR),这是一个类似于AR的基于PCFG归纳的合成任务。ATR将类似语言的层次结构引入到AR设置中。我们发现所有架构都学习了与AR相同的机制,并且相同的三个模型成功地完成了任务。这些结果表明,具有相似准确性的架构可能仍然存在实质性差异,从而推动了机制评估的采用。
🔬 方法详解
问题定义:论文旨在解决现有语言模型,特别是Transformer和状态空间模型(SSMs),在关联回忆(AR)等任务上表现差异大的问题。现有方法缺乏对这些模型内部机制的深入理解,仅仅依靠行为指标无法解释模型成功或失败的原因。因此,需要一种机制性的评估方法来理解不同架构的优缺点。
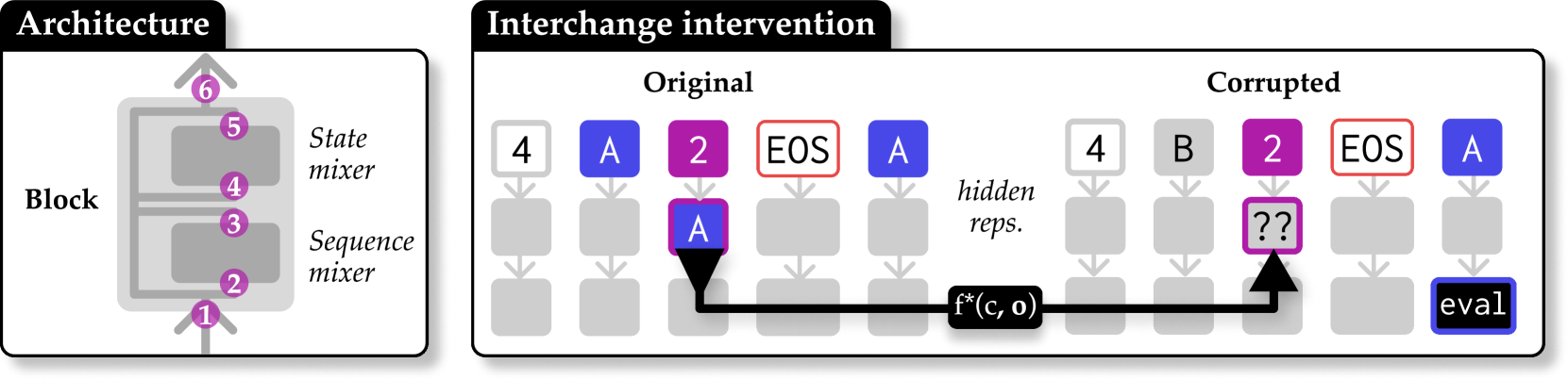
核心思路:论文的核心思路是通过设计合成任务(AR和ATR)并结合因果干预,来探究不同架构(Transformer, H3, Hyena, Mamba等)在处理关联信息时的内部机制。通过观察和干预模型内部的特定组件(如Transformer的归纳头),来理解信息是如何被存储、处理和检索的。
技术框架:论文的技术框架主要包括以下几个步骤: 1. 设计合成任务:设计AR和ATR任务,用于评估模型在关联回忆和层次化关联回忆方面的能力。 2. 模型训练与评估:训练不同的Transformer和SSM架构,并在AR和ATR任务上评估其性能。 3. 因果干预:对模型内部的关键组件进行因果干预,例如屏蔽Transformer的归纳头,观察对模型性能的影响。 4. 机制分析:分析因果干预的结果,推断不同架构在处理关联信息时的内部机制。
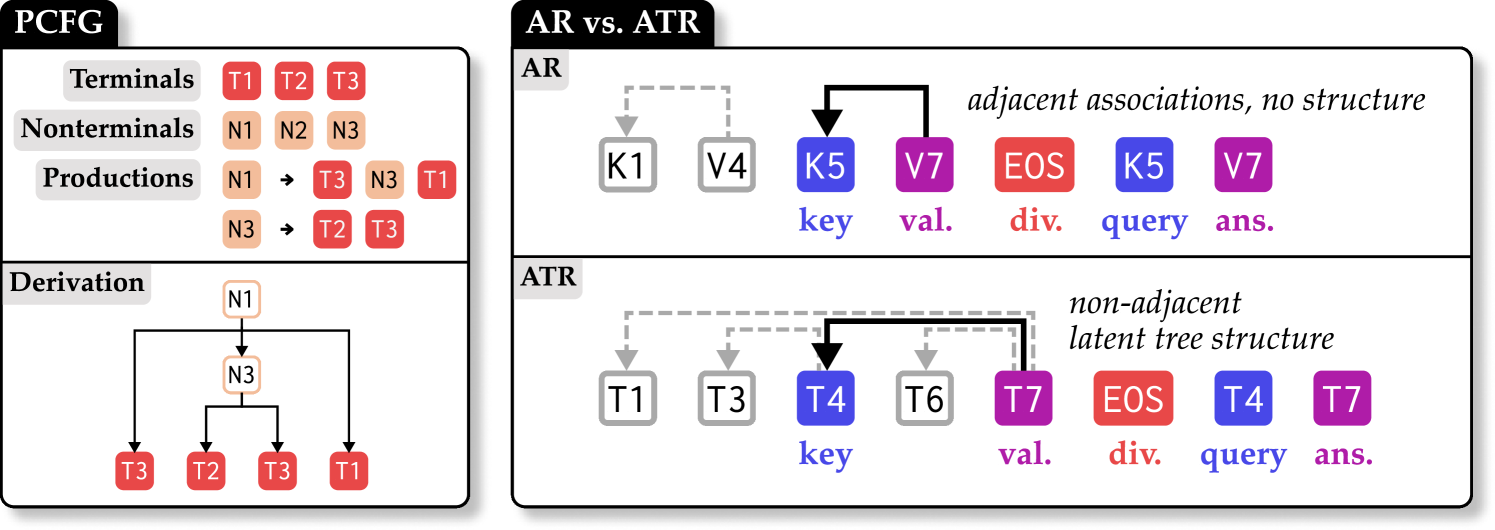
关键创新:论文的关键创新在于: 1. 机制性评估方法:提出了一种通过因果干预来理解模型内部机制的评估方法,超越了传统的行为指标评估。 2. 关联树调用(ATR)任务:设计了一种新的合成任务ATR,将语言的层次结构引入到关联回忆任务中,更贴近真实语言场景。 3. 揭示了Transformer和SSM的机制差异:发现Transformer通过归纳头在上下文中存储键值对,而SSM仅在最后状态计算这些关联。
关键设计: * Associative Recall (AR)任务:模型需要根据上下文中的键值对,回忆与特定键相关联的值。 * Associative Treecall (ATR)任务:在AR的基础上引入层次结构,模型需要根据树状结构的上下文回忆信息。 * 因果干预:通过屏蔽Transformer的归纳头,观察模型在AR和ATR任务上的性能变化。 * 模型选择:选择了Transformer, H3, Hyena, Mamba等多种具有代表性的架构进行对比。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Transformer和基于Transformer的SSM模型(如Based)在AR和ATR任务上表现出色,而其他SSM模型(如H3和Hyena)则表现不佳。Mamba在AR任务中表现接近Transformer,但在ATR任务中略逊一筹。通过因果干预,发现Transformer通过归纳头存储键值对,这是其在关联回忆任务中成功的关键。
🎯 应用场景
该研究成果可应用于语言模型的设计和优化,帮助研究人员更好地理解和改进模型的记忆能力和推理能力。通过机制性评估,可以设计出更高效、更可靠的语言模型,应用于机器翻译、文本生成、对话系统等领域。此外,该方法也适用于其他类型的神经网络,促进AI模型的可解释性和可控性。
📄 摘要(原文)
State space models (SSMs) for language modelling promise an efficient and performant alternative to quadratic-attention Transformers, yet show variable performance on recalling basic information from the context. While performance on synthetic tasks like Associative Recall (AR) can point to this deficiency, behavioural metrics provide little information as to why--on a mechanistic level--certain architectures fail and others succeed. To address this, we conduct experiments on AR and find that only Transformers and Based SSM models fully succeed at AR, with Mamba a close third, whereas the other SSMs (H3, Hyena) fail. We then use causal interventions to explain why. We find that Transformers and Based learn to store key-value associations in-context using induction heads. By contrast, the SSMs compute these associations only at the last state, with only Mamba succeeding because of its short convolution component. To extend and deepen these findings, we introduce Associative Treecall (ATR), a synthetic task similar to AR based on PCFG induction. ATR introduces language-like hierarchical structure into the AR setting. We find that all architectures learn the same mechanism as they did for AR, and the same three models succeed at the task. These results reveal that architectures with similar accuracy may still have substantive differences, motivating the adoption of mechanistic evaluations.