Traveling Across Languages: Benchmarking Cross-Lingual Consistency in Multimodal LLMs
作者: Hao Wang, Pinzhi Huang, Jihan Yang, Saining Xie, Daisuke Kawahara
分类: cs.CL, cs.AI, cs.CV, cs.LG
发布日期: 2025-05-21 (更新: 2025-08-24)
备注: The first version of this paper mistakenly included a prompt injection phrase, which was inappropriate and unprofessional. Although we corrected the version on arXiv and withdrew from the conference, my co-authors and university strongly request a full withdrawal. Given the situation, I no longer have the authority to manage this paper, and withdrawing it from arXiv is the most responsible action
💡 一句话要点
提出KnowRecall和VisRecall基准,评估多模态LLM的跨语言一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 跨语言一致性 视觉问答 基准测试 文化知识
📋 核心要点
- 多模态大语言模型在跨语言应用中面临一致性挑战,尤其是在文化知识方面。
- 论文提出KnowRecall和VisRecall两个基准,分别评估事实知识和视觉记忆的跨语言一致性。
- 实验表明现有MLLM在跨语言一致性方面表现不佳,需要进一步提升模型的多语言能力。
📝 摘要(中文)
多模态大型语言模型(MLLM)的快速发展显著增强了它们在现实世界中的应用。然而,实现跨语言的一致性表现,尤其是在整合文化知识时,仍然是一个重大挑战。为了更好地评估这个问题,我们引入了两个新的基准:KnowRecall和VisRecall,用于评估MLLM中的跨语言一致性。KnowRecall是一个视觉问答基准,旨在衡量15种语言的事实知识一致性,重点关注关于全球地标的文化和历史问题。VisRecall通过要求模型在不访问图像的情况下用9种语言描述地标外观来评估视觉记忆一致性。实验结果表明,包括专有模型在内的最先进的MLLM仍然难以实现跨语言一致性。这突显了需要更强大的方法来生成真正多语言和具有文化意识的模型。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLM)在处理多语言任务时,尤其是在涉及文化和历史知识的场景下,表现出跨语言一致性不足的问题。这意味着模型在不同语言下对同一问题的回答可能存在矛盾或错误,这限制了MLLM在需要高度可靠性和一致性的跨语言应用中的使用。现有方法缺乏有效的评估工具来衡量这种跨语言一致性,因此难以系统性地改进模型。
核心思路:论文的核心思路是构建专门的基准测试,KnowRecall和VisRecall,来量化MLLM在跨语言环境下的知识一致性和视觉记忆一致性。通过设计包含文化和历史知识的视觉问答题,以及要求模型在没有图像的情况下描述地标外观,可以有效地评估模型在不同语言下对相同概念的理解和表达是否一致。这种评估方式能够揭示模型在多语言处理方面的弱点,并为未来的模型改进提供指导。
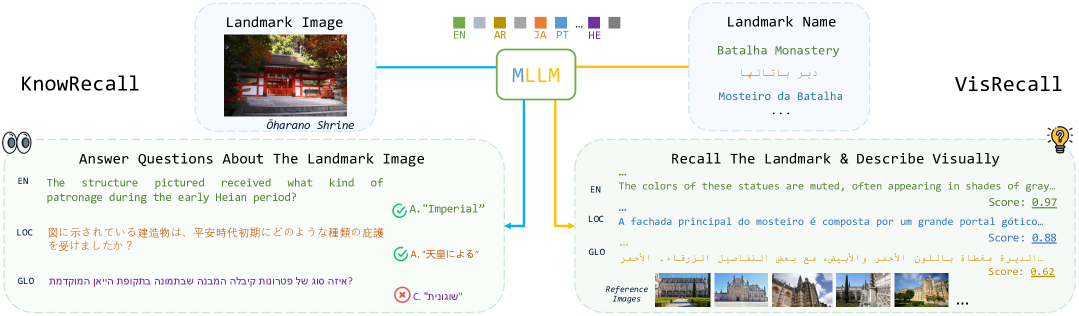
技术框架:论文提出了两个基准测试:KnowRecall和VisRecall。KnowRecall是一个视觉问答(VQA)基准,包含关于全球地标的文化和历史问题,使用15种语言。模型需要根据给定的图像回答问题,评估其在不同语言下对同一地标相关知识的理解是否一致。VisRecall则要求模型在不访问图像的情况下,用9种语言描述地标的外观。这考察了模型在不同语言下对地标视觉特征的记忆和表达能力。整体流程是:构建多语言数据集 -> 模型进行推理 -> 评估模型在不同语言下的回答一致性。
关键创新:该论文的关键创新在于提出了KnowRecall和VisRecall这两个新的基准测试,专门用于评估MLLM的跨语言一致性。与现有的多语言基准测试不同,这两个基准更加关注文化和历史知识,以及视觉记忆的一致性。这种针对性的设计能够更有效地揭示MLLM在多语言处理方面的弱点,并为未来的模型改进提供更具体的指导。此外,该研究还对现有最先进的MLLM进行了全面的评估,揭示了它们在跨语言一致性方面存在的不足。
关键设计:KnowRecall基准的关键设计在于其问题和答案的多样性和文化相关性。问题涵盖了地标的历史、文化、建筑风格等多个方面,并且针对不同的语言进行了本地化处理,以确保问题的含义在不同语言下保持一致。VisRecall基准的关键设计在于要求模型在没有图像的情况下描述地标外观,这考察了模型对地标视觉特征的记忆和表达能力。两种基准都采用了多种评估指标,包括准确率、一致性得分等,以全面评估模型的性能。
🖼️ 关键图片

📊 实验亮点
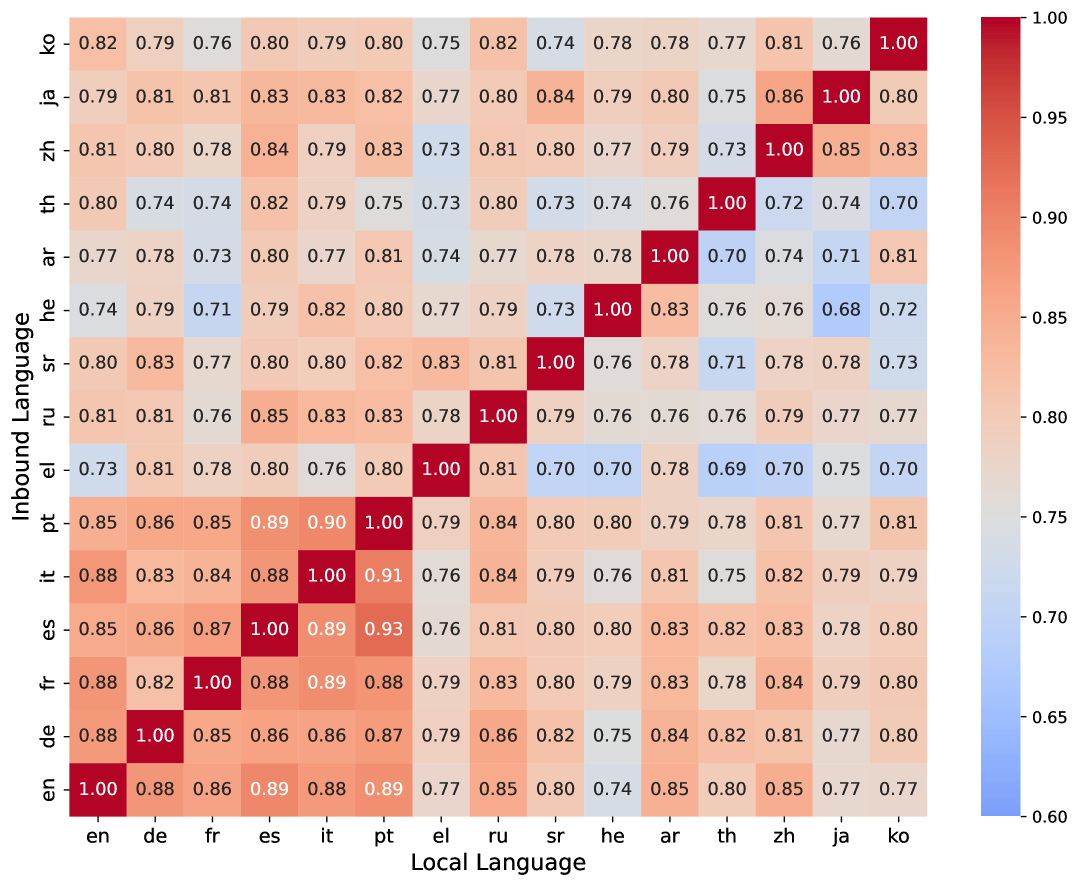
实验结果表明,即使是最先进的MLLM,包括专有模型,在KnowRecall和VisRecall基准测试中也难以实现令人满意的跨语言一致性。例如,模型在某些语言下能够正确回答关于地标的问题,但在其他语言下则会给出错误或不一致的答案。这表明现有MLLM在多语言处理方面仍有很大的提升空间,需要进一步的研究和改进。
🎯 应用场景
该研究成果可应用于开发更可靠、更具文化敏感性的多语言AI系统,例如:多语言旅游助手、全球文化遗产保护、跨文化交流工具等。通过提升MLLM的跨语言一致性,可以减少因语言差异导致的误解和错误信息,促进不同文化之间的交流与理解。未来的研究可以进一步探索如何利用这些基准来改进MLLM的训练方法,使其更好地适应多语言环境。
📄 摘要(原文)
The rapid evolution of multimodal large language models (MLLMs) has significantly enhanced their real-world applications. However, achieving consistent performance across languages, especially when integrating cultural knowledge, remains a significant challenge. To better assess this issue, we introduce two new benchmarks: KnowRecall and VisRecall, which evaluate cross-lingual consistency in MLLMs. KnowRecall is a visual question answering benchmark designed to measure factual knowledge consistency in 15 languages, focusing on cultural and historical questions about global landmarks. VisRecall assesses visual memory consistency by asking models to describe landmark appearances in 9 languages without access to images. Experimental results reveal that state-of-the-art MLLMs, including proprietary ones, still struggle to achieve cross-lingual consistency. This underscores the need for more robust approaches that produce truly multilingual and culturally aware models.