DISCO Balances the Scales: Adaptive Domain- and Difficulty-Aware Reinforcement Learning on Imbalanced Data
作者: Yuhang Zhou, Jing Zhu, Shengyi Qian, Zhuokai Zhao, Xiyao Wang, Xiaoyu Liu, Ming Li, Paiheng Xu, Wei Ai, Furong Huang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-21 (更新: 2025-09-24)
备注: Accepted by EMNLP 2025 Findings
🔗 代码/项目: GITHUB
💡 一句话要点
DISCO:自适应领域与难度感知的强化学习,解决不平衡数据下的LLM对齐问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈强化学习 大型语言模型 数据不平衡 领域自适应
📋 核心要点
- 现有GRPO方法在处理多领域不平衡数据时,会过度优化主导领域,忽略代表性不足的领域,导致泛化性和公平性下降。
- DISCO通过领域感知奖励缩放和难度感知奖励缩放,平衡不同领域和难度的样本,从而实现更公平和有效的策略学习。
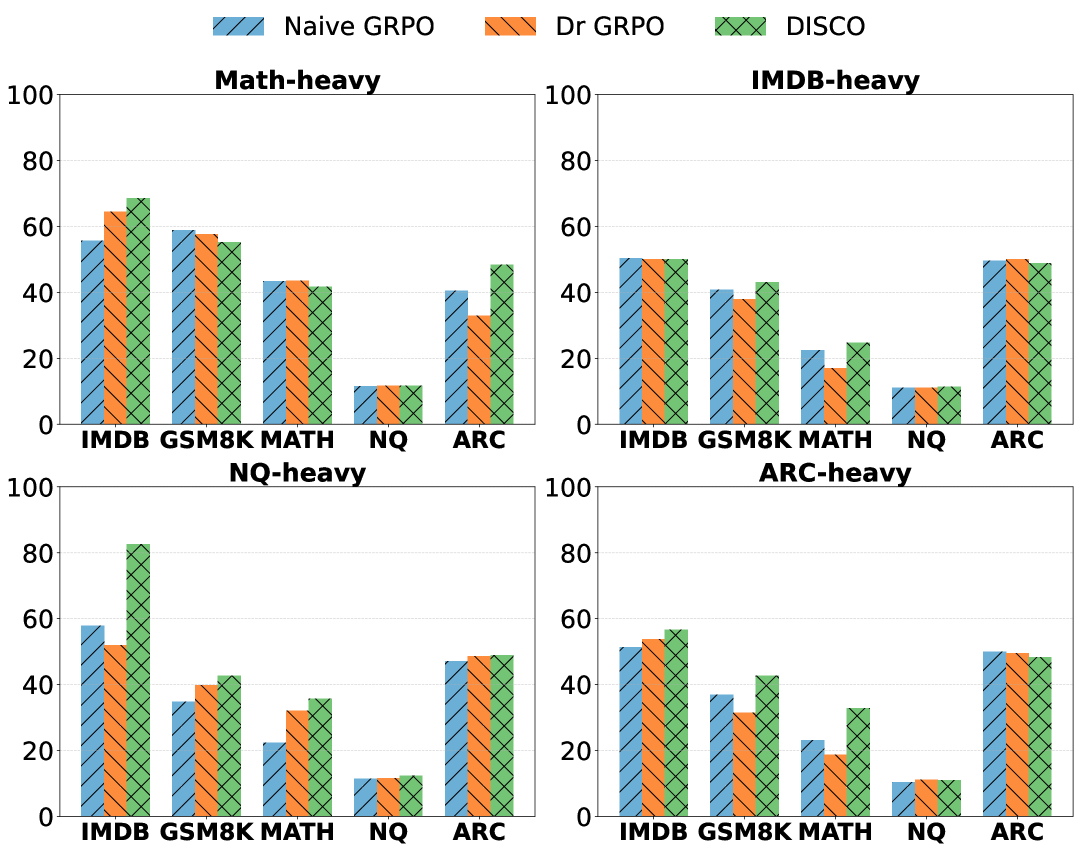
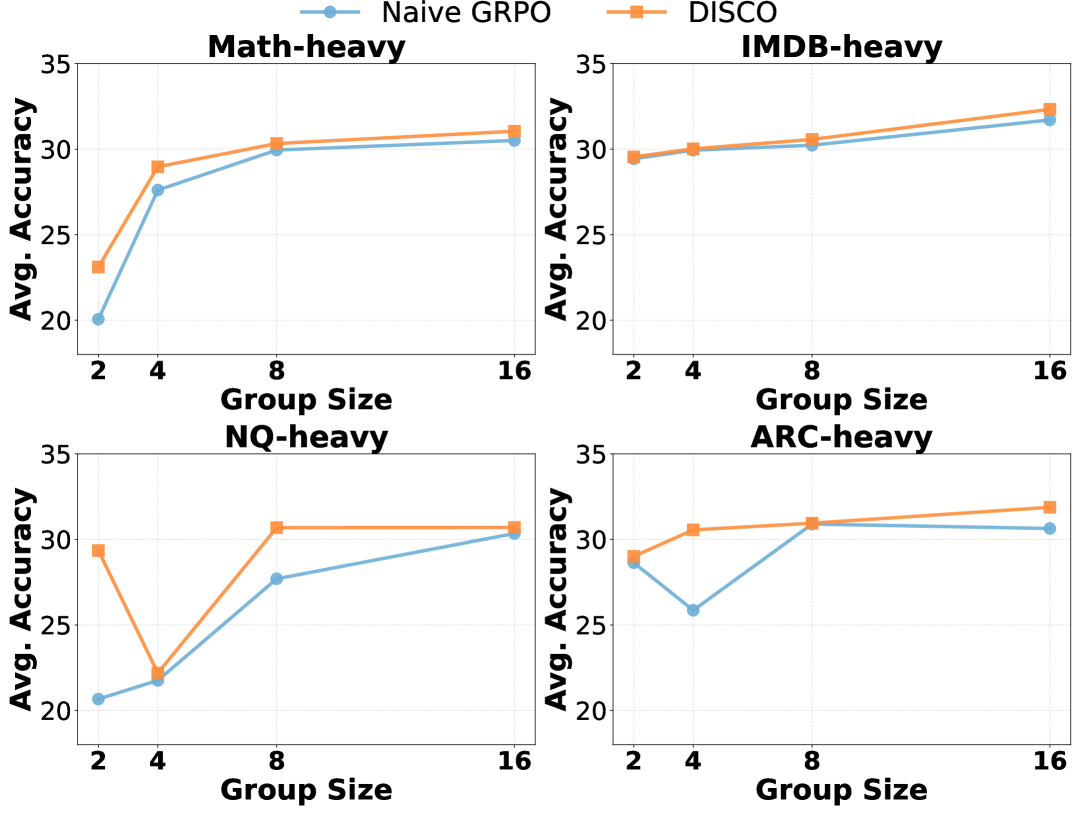
- 实验结果表明,DISCO在多个LLM和倾斜训练分布下,显著提高了泛化能力,并在多领域对齐基准上取得了新的SOTA。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地通过人类反馈强化学习(RLHF)与人类偏好对齐。在RLHF方法中,群体相对策略优化(GRPO)因其简单性和强大性能而备受关注,尤其是不需要学习价值函数。然而,GRPO隐含地假设平衡的领域分布和跨组的统一语义对齐,这些假设在现实世界的数据集中很少成立。当应用于多领域、不平衡数据时,GRPO会不成比例地优化主导领域,忽略代表性不足的领域,从而导致泛化能力和公平性较差。我们提出了领域感知自洽策略优化(DISCO),这是GRPO的一个原则性扩展,通过两个关键创新来解决组间不平衡问题。领域感知奖励缩放通过基于领域流行度重新加权优化来抵消频率偏差。难度感知奖励缩放利用提示级别的自洽性来识别和优先考虑提供更大学习价值的不确定提示。这些策略共同促进了跨领域更公平和有效的策略学习。跨多个LLM和倾斜训练分布的广泛实验表明,DISCO提高了泛化能力,在Qwen3模型上优于现有的GRPO变体5%,并在多领域对齐基准上设置了新的最先进结果。我们的代码和数据可在https://github.com/Tonyzhou98/disco_grpo 获得。
🔬 方法详解
问题定义:论文旨在解决在多领域、数据不平衡的情况下,使用GRPO等RLHF方法训练LLM时,模型容易偏向于数据量大的领域,导致在数据量小的领域表现不佳,泛化能力和公平性受损的问题。现有方法未能充分考虑领域分布的不平衡性和样本难度差异,导致优化过程存在偏差。
核心思路:DISCO的核心思路是通过领域感知和难度感知的奖励缩放,来平衡不同领域和不同难度的样本对策略更新的影响。领域感知奖励缩放通过对不同领域的奖励进行加权,使得模型更加关注数据量小的领域。难度感知奖励缩放则通过评估样本的自洽性,对不确定性高的样本赋予更高的权重,从而提高学习效率。
技术框架:DISCO是在GRPO的基础上进行的扩展。整体框架仍然是基于策略梯度的强化学习,但引入了两个关键模块:领域感知奖励缩放模块和难度感知奖励缩放模块。领域感知奖励缩放模块根据每个领域的数据量计算权重,并对该领域的奖励进行缩放。难度感知奖励缩放模块则通过计算prompt的自洽性来评估样本难度,并对奖励进行相应的缩放。
关键创新:DISCO的关键创新在于同时考虑了领域不平衡性和样本难度差异,并提出了相应的奖励缩放策略。领域感知奖励缩放能够有效地平衡不同领域的数据量差异,避免模型过度拟合数据量大的领域。难度感知奖励缩放则能够提高模型对不确定性样本的学习效率,从而加速收敛。
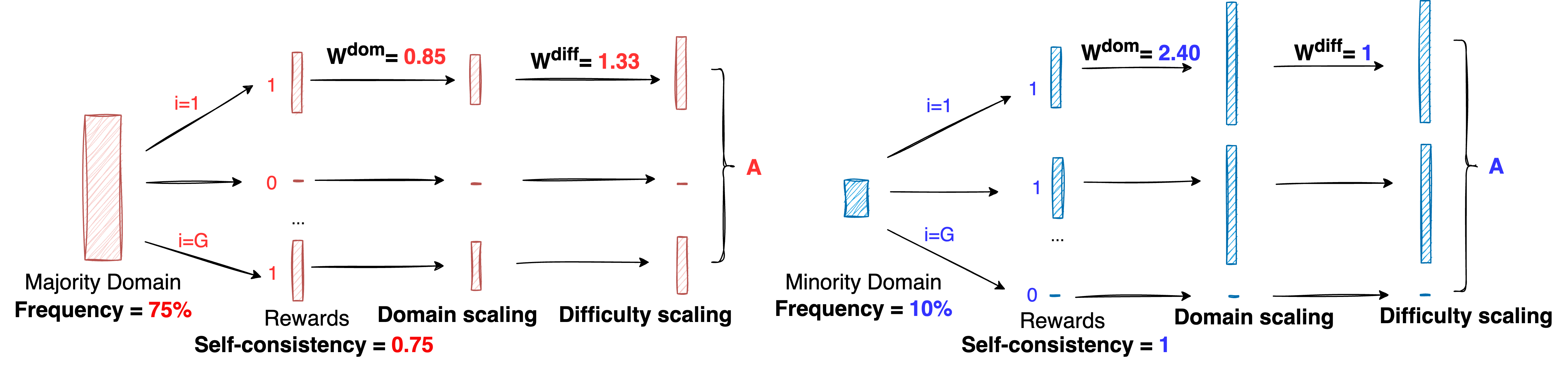
关键设计:领域感知奖励缩放的关键在于如何计算每个领域的权重。论文采用了一种基于领域数据量的倒数加权方法,即数据量越小的领域,权重越大。难度感知奖励缩放的关键在于如何评估样本的自洽性。论文通过多次采样模型对同一prompt的回复,并计算这些回复之间的相似度来评估自洽性。相似度越低,说明样本难度越高,奖励权重也越大。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DISCO在多个LLM(包括Qwen3)和倾斜训练分布下,显著提高了泛化能力。在Qwen3模型上,DISCO优于现有的GRPO变体5%。此外,DISCO在多领域对齐基准上取得了新的SOTA,证明了其在处理不平衡数据方面的有效性。消融实验也验证了领域感知奖励缩放和难度感知奖励缩放的有效性。
🎯 应用场景
DISCO方法可广泛应用于需要处理多领域、不平衡数据的LLM对齐任务中,例如对话系统、文本生成、问答系统等。通过平衡不同领域的数据,可以提高模型在各个领域的性能,提升用户体验。此外,DISCO方法还可以应用于其他强化学习任务中,解决数据不平衡带来的挑战,提高模型的泛化能力和鲁棒性。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly aligned with human preferences through Reinforcement Learning from Human Feedback (RLHF). Among RLHF methods, Group Relative Policy Optimization (GRPO) has gained attention for its simplicity and strong performance, notably eliminating the need for a learned value function. However, GRPO implicitly assumes a balanced domain distribution and uniform semantic alignment across groups, assumptions that rarely hold in real-world datasets. When applied to multi-domain, imbalanced data, GRPO disproportionately optimizes for dominant domains, neglecting underrepresented ones and resulting in poor generalization and fairness. We propose Domain-Informed Self-Consistency Policy Optimization (DISCO), a principled extension to GRPO that addresses inter-group imbalance with two key innovations. Domain-aware reward scaling counteracts frequency bias by reweighting optimization based on domain prevalence. Difficulty-aware reward scaling leverages prompt-level self-consistency to identify and prioritize uncertain prompts that offer greater learning value. Together, these strategies promote more equitable and effective policy learning across domains. Extensive experiments across multiple LLMs and skewed training distributions show that DISCO improves generalization, outperforms existing GRPO variants by 5% on Qwen3 models, and sets new state-of-the-art results on multi-domain alignment benchmarks. Our code and data are available at https://github.com/Tonyzhou98/disco_grpo.