Can Large Language Models Understand Internet Buzzwords Through User-Generated Content
作者: Chen Huang, Junkai Luo, Xinzuo Wang, Wenqiang Lei, Jiancheng Lv
分类: cs.CL
发布日期: 2025-05-21
备注: ACL 2025 Main Paper. Our dataset and code are available at https://github.com/SCUNLP/Buzzword
🔗 代码/项目: GITHUB
💡 一句话要点
提出RESS方法并构建CHEER数据集,提升大语言模型对互联网流行语的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 互联网流行语 用户生成内容 定义生成 自然语言处理
📋 核心要点
- 现有方法难以准确理解和定义新兴的中文互联网流行语,尤其是在缺乏高质量用户生成内容的情况下。
- 论文提出RESS方法,通过引导LLM学习过程,使其能够像人类一样从UGC中学习并定义流行语。
- 构建了CHEER数据集,并在此数据集上验证了RESS方法的有效性,同时指出了现有方法的不足之处。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)能否基于用户生成内容(UGC)为中文互联网流行语生成准确的定义。为此,我们做出了三方面的贡献。首先,我们引入了CHEER,这是第一个中文互联网流行语数据集,每个流行语都标注了定义和相关的UGC。其次,我们提出了一种名为RESS的新方法,可以有效地引导LLMs的理解过程,从而生成更准确的流行语定义,模仿人类的语言学习技能。第三,我们使用CHEER数据集,对各种现成的定义生成方法和我们的RESS方法进行了基准测试,评估了它们的优势和劣势。我们的基准测试证明了RESS的有效性,同时也揭示了关键的共同挑战:过度依赖先前的曝光、不发达的推理能力以及难以识别高质量的UGC以促进理解。我们相信我们的工作为未来基于LLM的定义生成方面的进步奠定了基础。我们的数据集和代码可在https://github.com/SCUNLP/Buzzword获取。
🔬 方法详解
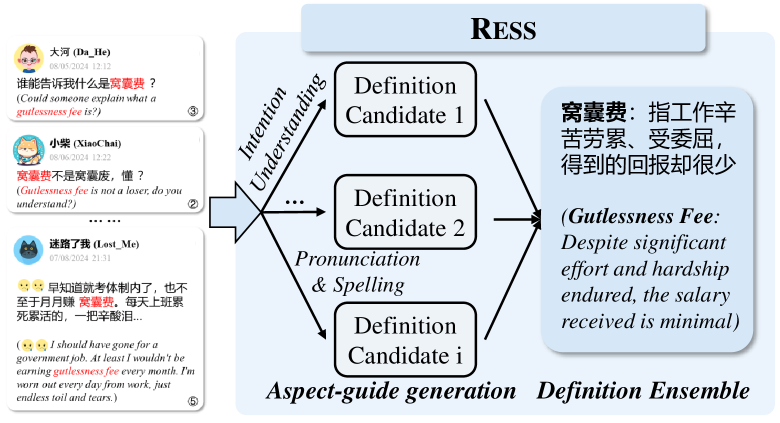
问题定义:论文旨在解决大型语言模型(LLMs)在理解和定义中文互联网流行语时面临的挑战。现有的方法往往依赖于预训练数据中的先验知识,对于新出现的、缺乏明确定义的流行语难以给出准确的解释。此外,如何从海量的用户生成内容(UGC)中提取有效信息,辅助LLM理解流行语的含义,也是一个亟待解决的问题。
核心思路:论文的核心思路是模仿人类学习语言的方式,即通过上下文语境(UGC)来理解新词的含义。RESS方法通过引导LLM关注与流行语相关的UGC,并利用这些UGC来生成定义,从而提高LLM对流行语的理解能力。这种方法避免了过度依赖预训练知识,更加注重从实际语境中学习。
技术框架:RESS方法的技术框架主要包括以下几个步骤:1) 数据收集:收集包含目标流行语的UGC;2) 上下文选择:从UGC中选择与流行语最相关的上下文信息;3) 定义生成:利用LLM,基于选择的上下文信息生成流行语的定义;4) 评估与优化:评估生成定义的质量,并根据评估结果优化模型。
关键创新:RESS方法的关键创新在于其引导LLM学习的方式。与传统的直接利用LLM生成定义的方法不同,RESS方法强调利用UGC作为LLM学习的“教材”,通过选择高质量的上下文信息,引导LLM关注与流行语相关的关键特征。这种方法能够有效提高LLM对流行语的理解能力,并生成更准确的定义。
关键设计:RESS方法的关键设计包括:1) 上下文选择策略:如何从海量的UGC中选择与流行语最相关的上下文信息?论文可能采用了基于相似度或相关性的方法,例如计算UGC与流行语之间的语义相似度,选择相似度最高的UGC作为上下文信息。2) 定义生成模型:论文可能采用了基于Transformer的序列到序列模型,例如BART或T5,作为定义生成模型。3) 损失函数:论文可能采用了交叉熵损失函数来训练定义生成模型,并可能引入了额外的正则化项,以提高生成定义的质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RESS方法在CHEER数据集上取得了显著的性能提升,能够生成更准确、更符合语境的流行语定义。与现有的定义生成方法相比,RESS方法在多个评价指标上均取得了领先优势,证明了其有效性。同时,实验也揭示了现有方法在处理互联网流行语时面临的挑战,例如过度依赖先验知识、推理能力不足等。
🎯 应用场景
该研究成果可应用于智能客服、舆情分析、社交媒体内容理解等领域。通过提升LLM对互联网流行语的理解能力,可以更准确地识别用户意图、分析舆论趋势,并生成更符合语境的回复。此外,该研究还可以促进自然语言处理技术在社交媒体领域的应用,为构建更加智能、人性化的社交媒体平台提供支持。
📄 摘要(原文)
The massive user-generated content (UGC) available in Chinese social media is giving rise to the possibility of studying internet buzzwords. In this paper, we study if large language models (LLMs) can generate accurate definitions for these buzzwords based on UGC as examples. Our work serves a threefold contribution. First, we introduce CHEER, the first dataset of Chinese internet buzzwords, each annotated with a definition and relevant UGC. Second, we propose a novel method, called RESS, to effectively steer the comprehending process of LLMs to produce more accurate buzzword definitions, mirroring the skills of human language learning. Third, with CHEER, we benchmark the strengths and weaknesses of various off-the-shelf definition generation methods and our RESS. Our benchmark demonstrates the effectiveness of RESS while revealing crucial shared challenges: over-reliance on prior exposure, underdeveloped inferential abilities, and difficulty identifying high-quality UGC to facilitate comprehension. We believe our work lays the groundwork for future advancements in LLM-based definition generation. Our dataset and code are available at https://github.com/SCUNLP/Buzzword.