Self-GIVE: Associative Thinking from Limited Structured Knowledge for Enhanced Large Language Model Reasoning
作者: Jiashu He, Jinxuan Fan, Bowen Jiang, Ignacio Houine, Dan Roth, Alejandro Ribeiro
分类: cs.CL, cs.AI
发布日期: 2025-05-21 (更新: 2025-10-03)
💡 一句话要点
Self-GIVE:利用有限结构化知识增强大语言模型推理的联想思维
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识图谱 强化学习 联想思维 生物医学问答
📋 核心要点
- 现有方法在知识图谱上进行推理时,需要构建和修剪大量假设三元组,效率低且泛化性差。
- Self-GIVE通过检索-强化学习框架,使LLM能够自动进行联想思维,从而更好地利用结构化知识。
- 实验表明,Self-GIVE显著提升了小型LLM在生物医学问答任务上的性能,甚至超越了大型模型。
📝 摘要(中文)
本文提出Self-GIVE,一个检索-强化学习框架,旨在通过强化学习增强大语言模型的自动联想思维能力。当检索到的知识不足以直接回答问题时,大型语言模型需要联想思维来解决科学问题。Self-GIVE提取结构化信息和实体集合,以帮助模型链接到查询的概念。该方法解决了GIVE的关键限制:知识推断需要大量的LLM调用和token开销,难以部署在较小的LLM上(3B或7B),以及来自LLM修剪的不准确知识。在使用包含135个节点的UMLS知识图谱进行微调后,Self-GIVE将Qwen2.5 3B和7B模型在具有挑战性的生物医学QA任务中未见样本上的性能分别提高了高达28.5%→71.4%和78.6%→90.5%。Self-GIVE使得7B模型能够匹配甚至优于使用GIVE的GPT3.5 turbo,同时减少了超过90%的token使用量。Self-GIVE增强了结构化检索和推理与联想思维的可扩展集成。
🔬 方法详解
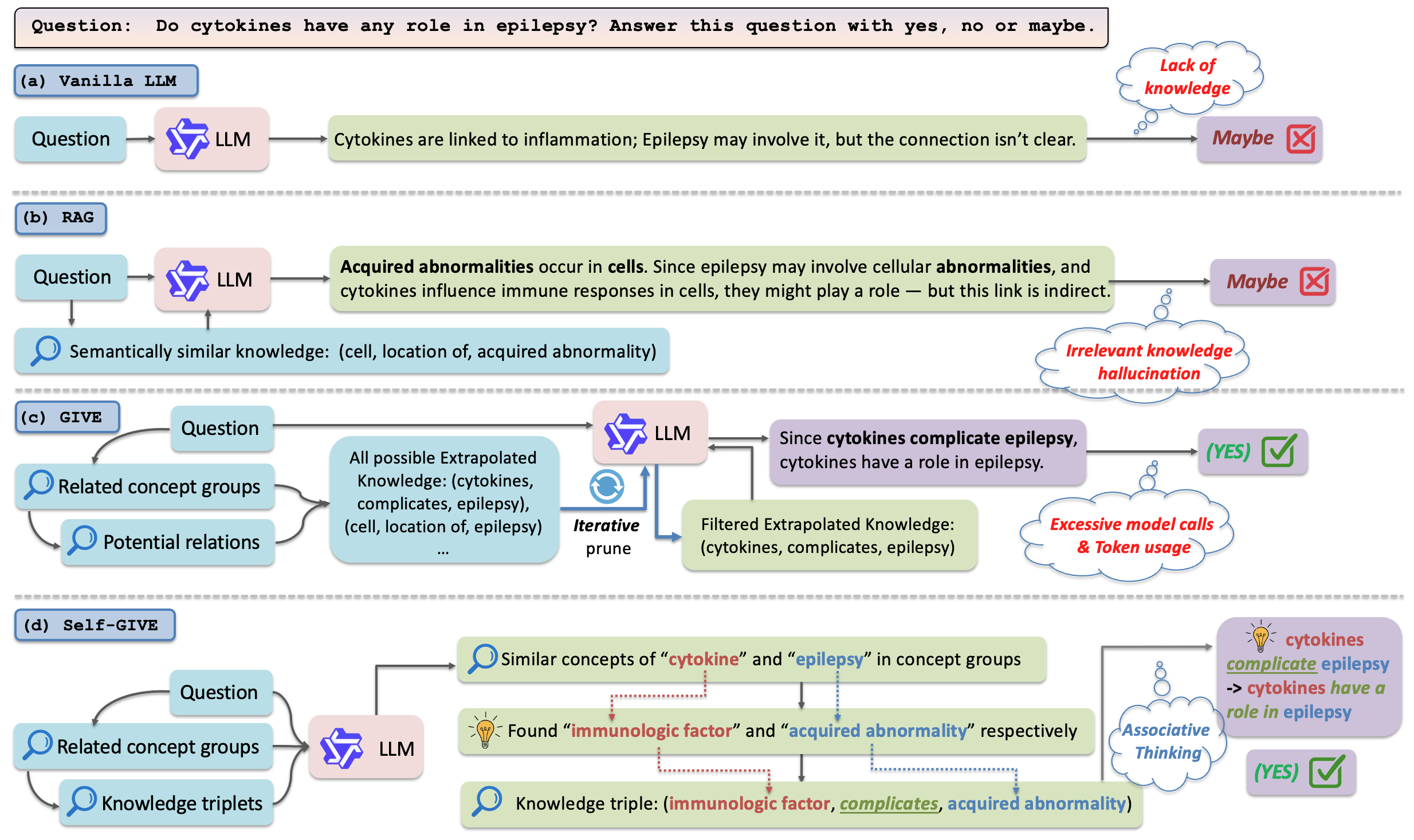
问题定义:论文旨在解决大型语言模型(LLM)在处理复杂问题,特别是科学问答时,由于检索到的知识不足而无法有效推理的问题。现有方法,如GIVE,依赖于知识图谱(KG)进行知识外推,但需要构建和修剪大量的假设三元组,导致效率低下,泛化能力受限,并且计算成本高昂,难以在小型LLM上部署。
核心思路:Self-GIVE的核心思路是通过强化学习(RL)训练LLM,使其能够自动进行联想思维。具体来说,模型通过提取结构化信息和实体集合,辅助其将查询概念与相关知识联系起来。这种方法避免了GIVE中大量假设三元组的生成和评估,从而提高了效率和泛化能力。
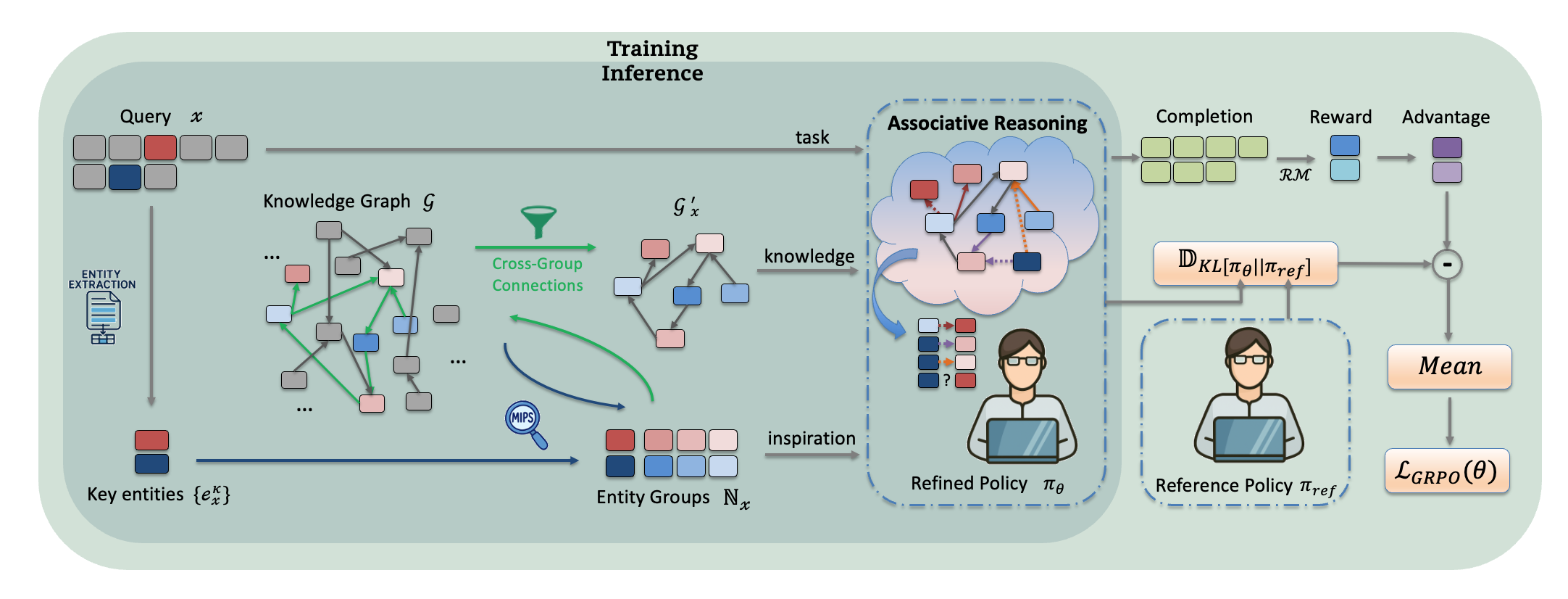
技术框架:Self-GIVE采用检索-强化学习框架。首先,模型接收问题并从知识库中检索相关信息。然后,模型利用提取的结构化信息和实体集合进行联想推理,生成答案。强化学习用于训练模型,使其能够选择最佳的联想推理路径,从而提高答案的准确性。整体流程包括知识检索、结构化信息提取、联想推理和奖励反馈四个主要阶段。
关键创新:Self-GIVE的关键创新在于将强化学习引入到LLM的知识推理过程中,使其能够自动学习如何进行联想思维。与GIVE相比,Self-GIVE避免了大量假设三元组的生成和评估,从而提高了效率和泛化能力。此外,Self-GIVE还解决了GIVE难以在小型LLM上部署的问题。
关键设计:Self-GIVE的关键设计包括:1) 使用UMLS知识图谱作为结构化知识来源;2) 设计奖励函数,鼓励模型生成准确的答案并避免不相关的联想;3) 使用Qwen2.5 3B和7B模型作为基础LLM,并进行微调;4) 采用特定的训练策略,以提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
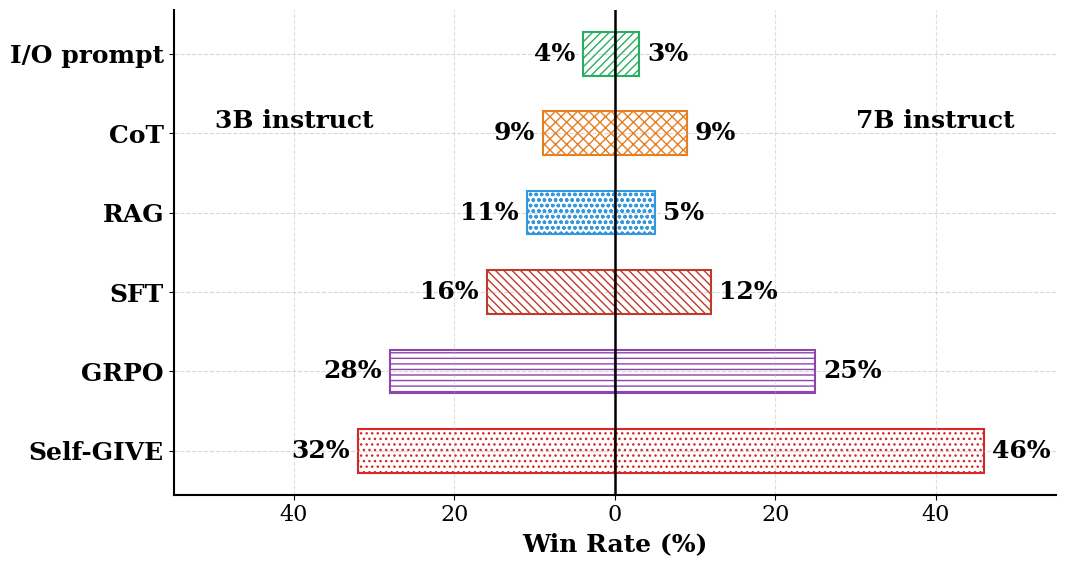
Self-GIVE在生物医学问答任务上取得了显著的性能提升。在未见样本上,Self-GIVE将Qwen2.5 3B模型的性能从28.5%提高到71.4%,将Qwen2.5 7B模型的性能从78.6%提高到90.5%。更重要的是,Self-GIVE使得7B模型能够匹配甚至优于使用GIVE的GPT3.5 turbo,同时减少了超过90%的token使用量,证明了其在效率和性能上的优势。
🎯 应用场景
Self-GIVE在生物医学问答、科学研究、智能客服等领域具有广泛的应用前景。它可以帮助研究人员更有效地利用知识图谱进行推理,从而加速科学发现。在智能客服领域,Self-GIVE可以提高问题解答的准确性和效率,从而提升用户体验。未来,Self-GIVE有望应用于更广泛的知识密集型任务,例如智能诊断、药物研发等。
📄 摘要(原文)
When addressing complex questions that require new information, people often associate the question with existing knowledge to derive a sensible answer. For instance, when evaluating whether melatonin aids insomnia, one might associate "hormones helping mental disorders" with "melatonin being a hormone and insomnia a mental disorder" to complete the reasoning. Large Language Models (LLMs) also require such associative thinking, particularly in resolving scientific inquiries when retrieved knowledge is insufficient and does not directly answer the question. Graph Inspired Veracity Extrapolation (GIVE) addresses this by using a knowledge graph (KG) to extrapolate structured knowledge. However, it involves the construction and pruning of many hypothetical triplets, which limits efficiency and generalizability. We propose Self-GIVE, a retrieve-RL framework that enhances LLMs with automatic associative thinking through reinforcement learning. Self-GIVE extracts structured information and entity sets to assist the model in linking to the queried concepts. We address GIVE's key limitations: (1) extensive LLM calls and token overhead for knowledge extrapolation, (2) difficulty in deploying on smaller LLMs (3B or 7B) due to complex instructions, and (3) inaccurate knowledge from LLM pruning. Specifically, after fine-tuning using self-GIVE with a 135 node UMLS KG, it improves the performance of the Qwen2.5 3B and 7B models by up to $\textbf{28.5%$\rightarrow$71.4%}$ and $\textbf{78.6$\rightarrow$90.5%}$ in samples $\textbf{unseen}$ in challenging biomedical QA tasks. In particular, Self-GIVE allows the 7B model to match or outperform GPT3.5 turbo with GIVE, while cutting token usage by over 90%. Self-GIVE enhances the scalable integration of structured retrieval and reasoning with associative thinking.