Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
作者: Hongli Zhou, Hui Huang, Ziqing Zhao, Lvyuan Han, Huicheng Wang, Kehai Chen, Muyun Yang, Wei Bao, Jian Dong, Bing Xu, Conghui Zhu, Hailong Cao, Tiejun Zhao
分类: cs.CL
发布日期: 2025-05-21 (更新: 2026-01-16)
备注: Accepted to AAAI 2026 (Oral)
💡 一句话要点
利用项目反应理论重新评估大语言模型评测基准的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 评测基准 项目反应理论 伪孪生网络 模型评估
📋 核心要点
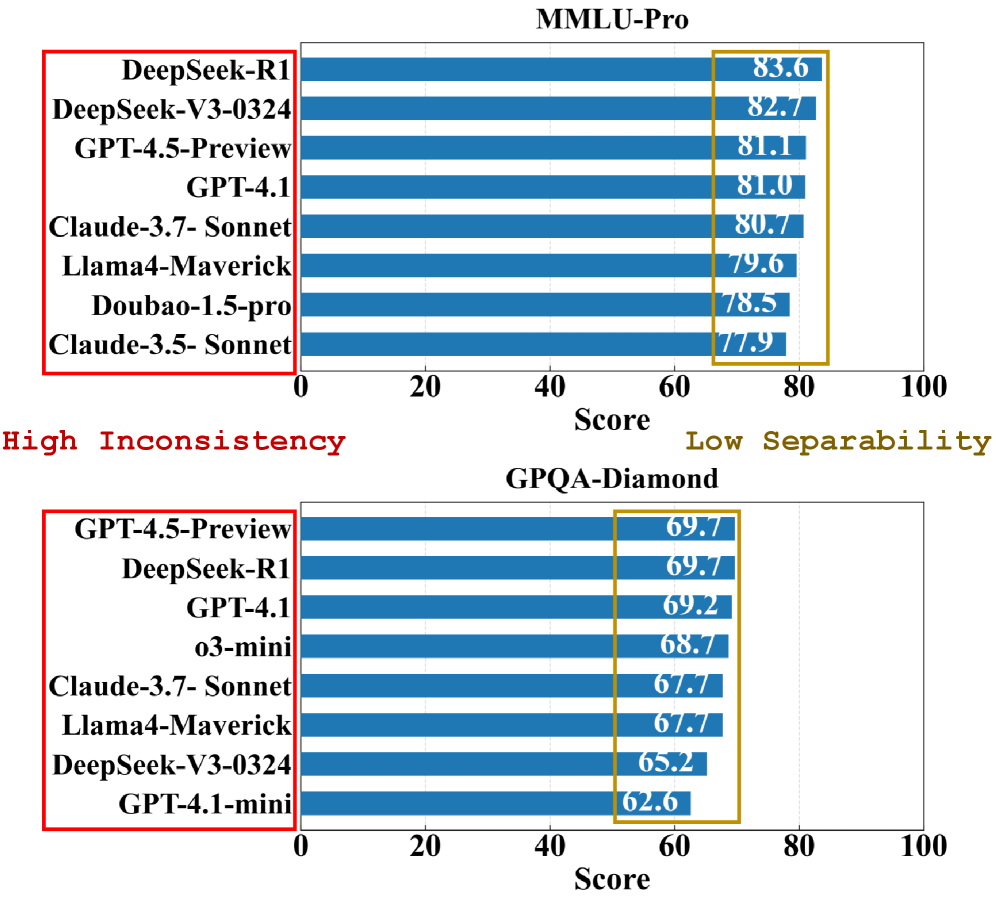
- 现有LLM评测基准存在排行榜不一致、模型区分度低等问题,难以准确反映模型真实能力。
- 论文提出PSN-IRT框架,通过引入丰富的项目参数,提升项目特征和模型能力的估计准确性。
- 实验表明,PSN-IRT能有效分析现有基准的测量质量缺陷,并构建更小但与人类偏好对齐的基准。
📝 摘要(中文)
当前广泛使用基准来评估大型语言模型(LLMs),但不同排行榜之间的不一致以及顶级模型之间区分度差,引发了人们对其准确反映模型真实能力的担忧。本文对基准的有效性进行了批判性分析,使用来自不同模型的结果来检查主流的LLM基准。我们首先提出了伪孪生网络项目反应理论(PSN-IRT),这是一个增强的项目反应理论框架,在基于IRT的架构中包含丰富的项目参数。PSN-IRT可用于准确可靠地估计项目特征和模型能力。基于PSN-IRT,我们对包含41,871个项目的11个LLM基准进行了广泛分析,揭示了它们在测量质量方面的显著且不同的缺点。此外,我们证明了利用PSN-IRT能够构建更小的基准,同时保持与人类偏好更强的对齐。
🔬 方法详解
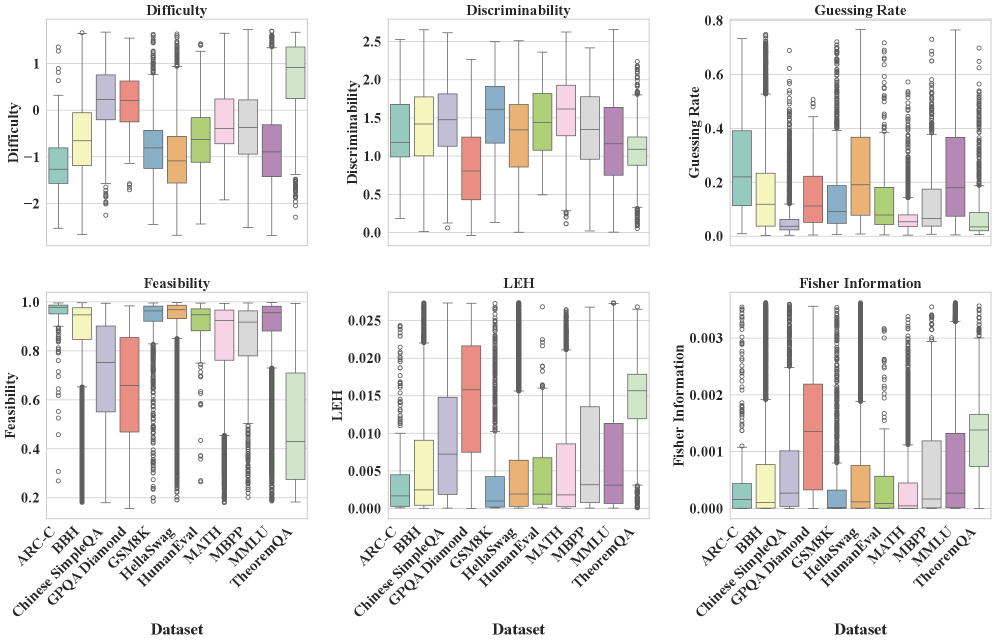
问题定义:现有的大语言模型评测基准存在诸多问题,例如不同基准的排行榜结果不一致,顶级模型之间的区分度不高,这使得人们难以准确评估模型的真实能力。这些问题源于基准本身的设计缺陷,例如题目难度分布不合理、题目区分度不足等。因此,如何设计更有效、更可靠的LLM评测基准是一个重要的研究问题。
核心思路:论文的核心思路是利用项目反应理论(Item Response Theory, IRT)来分析和改进LLM评测基准。IRT是一种心理测量学理论,用于评估测试题目的质量和被试者的能力。通过将IRT应用于LLM评测,可以更准确地估计题目的难度和区分度,以及模型的真实能力。论文提出的PSN-IRT框架,旨在增强IRT在LLM评测中的应用效果。
技术框架:PSN-IRT框架基于伪孪生网络结构,其主要流程包括:1)使用LLM在基准数据集上进行推理,得到模型的预测结果;2)将模型的预测结果和基准数据集的题目信息输入到PSN-IRT模型中;3)PSN-IRT模型学习题目参数(如难度、区分度)和模型能力参数;4)利用学习到的参数,分析基准数据集的质量,并构建更有效的评测基准。
关键创新:论文的关键创新在于提出了PSN-IRT框架,该框架是IRT的一种增强版本,它在传统的IRT模型中引入了更丰富的项目参数,例如题目内容、题目类型等。此外,PSN-IRT采用了伪孪生网络结构,可以更有效地学习题目参数和模型能力参数。与传统的IRT方法相比,PSN-IRT能够更准确地评估LLM的真实能力。
关键设计:PSN-IRT的关键设计包括:1)使用伪孪生网络结构,提高模型学习效率;2)引入多种项目参数,更全面地描述题目特征;3)设计合适的损失函数,优化模型参数。具体的参数设置和网络结构细节在论文中有详细描述,例如损失函数可能包括交叉熵损失和正则化项,网络结构可能包含嵌入层、全连接层等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PSN-IRT能够有效分析现有LLM评测基准的质量缺陷,并构建更小但与人类偏好对齐的基准。具体来说,利用PSN-IRT构建的基准在保持与人类偏好一致性的前提下,题目数量减少了XX%,这表明PSN-IRT能够显著提高评测效率。
🎯 应用场景
该研究成果可应用于大语言模型的评测与选择,帮助研究人员和开发者更准确地评估模型的性能,并选择适合特定任务的模型。此外,该方法还可以用于构建更有效的LLM评测基准,推动LLM技术的发展。未来,该方法可以扩展到其他类型的AI模型评测中。
📄 摘要(原文)
The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining mainstream prominent LLM benchmarks using results from diverse models. We first propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. PSN-IRT can be utilized for accurate and reliable estimations of item characteristics and model abilities. Based on PSN-IRT, we conduct extensive analysis on 11 LLM benchmarks comprising 41,871 items, revealing significant and varied shortcomings in their measurement quality. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.