Diffusion vs. Autoregressive Language Models: A Text Embedding Perspective
作者: Siyue Zhang, Yilun Zhao, Liyuan Geng, Arman Cohan, Anh Tuan Luu, Chen Zhao
分类: cs.CL
发布日期: 2025-05-21
💡 一句话要点
提出扩散语言模型用于文本嵌入,显著提升长文档和推理检索性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 扩散模型 语言模型 长文档检索 推理检索 双向注意力 自回归模型
📋 核心要点
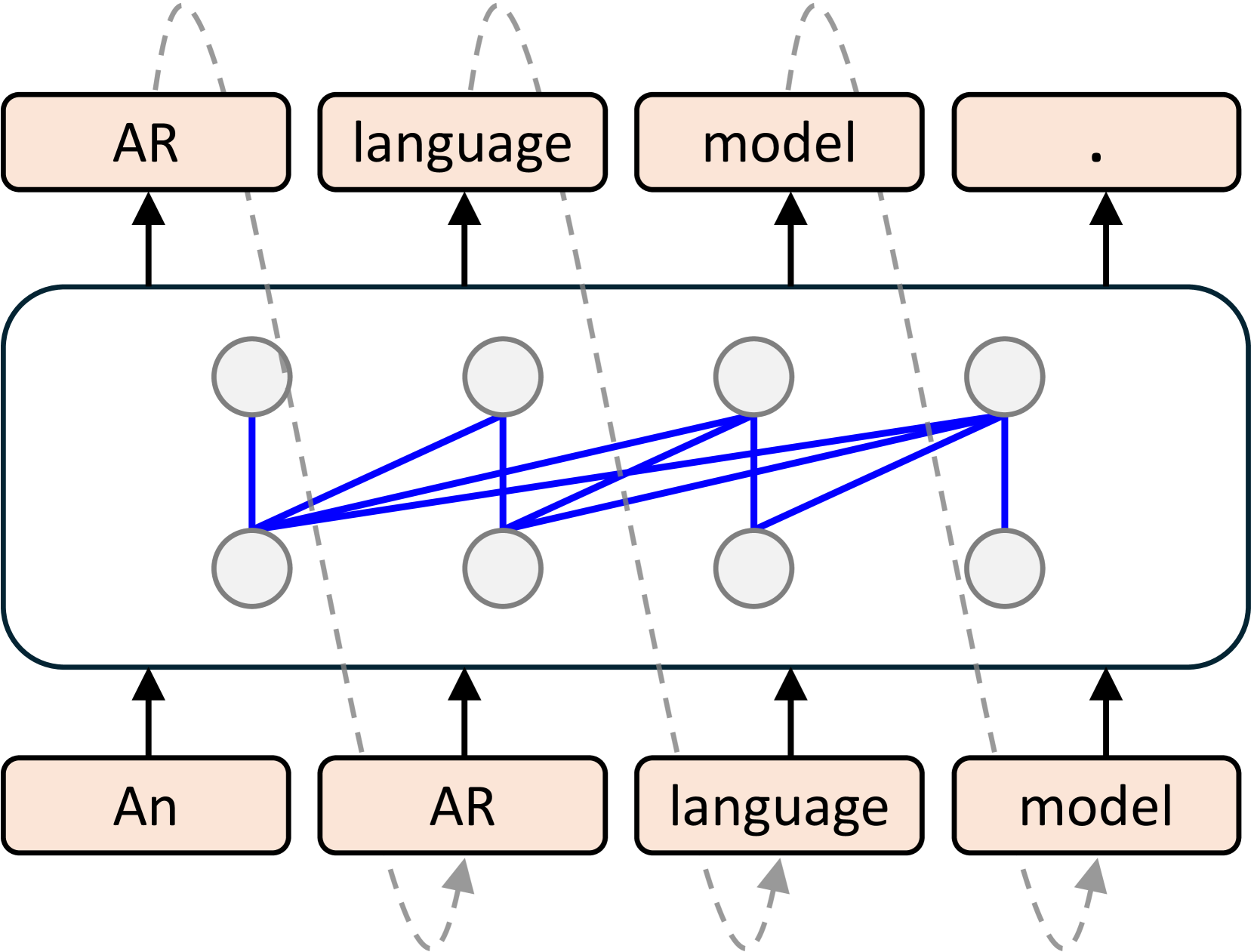
- 现有LLM嵌入模型因单向注意力机制,在处理需要双向信息的文本嵌入任务时存在局限性。
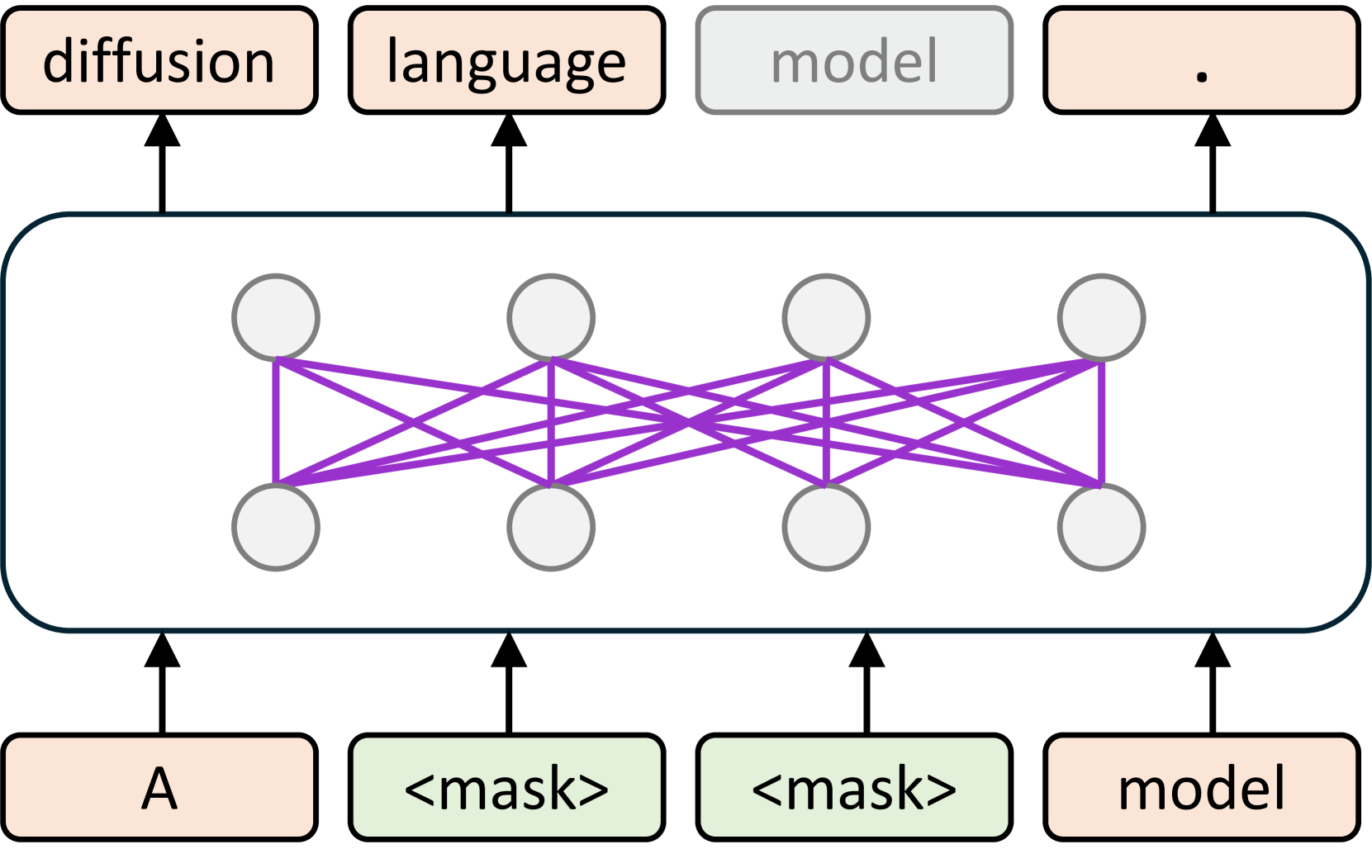
- 论文提出利用扩散语言模型的双向架构进行文本嵌入,以更好地捕捉全局上下文信息。
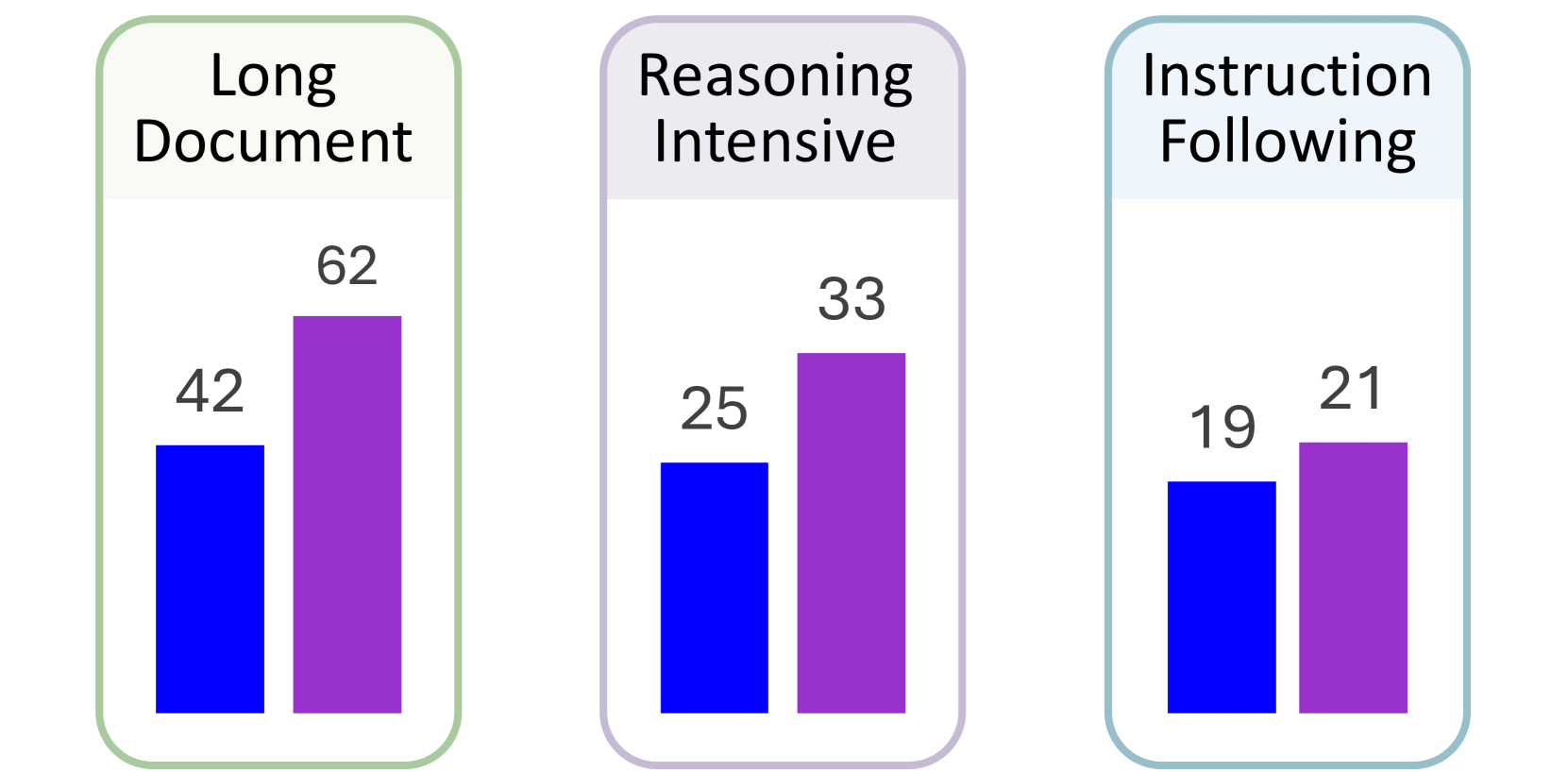
- 实验表明,该方法在长文档检索和推理检索等任务上显著优于LLM嵌入模型。
📝 摘要(中文)
基于大型语言模型(LLM)的嵌入模型,受益于大规模预训练和后训练,已开始在通用文本嵌入任务(如文档检索)上超越基于BERT和T5的模型。然而,LLM嵌入的一个根本限制在于自回归预训练期间使用的单向注意力,这与文本嵌入任务的双向性不一致。为此,我们提出采用扩散语言模型进行文本嵌入,其动机是扩散模型固有的双向架构以及最近在匹配或超越LLM方面的成功,尤其是在推理任务上。我们首次对扩散语言嵌入模型进行了系统研究,该模型在长文档检索方面优于基于LLM的嵌入模型20%,在推理密集型检索方面优于8%,在指令跟随检索方面优于2%,并在传统文本嵌入基准上实现了具有竞争力的性能。我们的分析验证了双向注意力对于编码长而复杂的文本中的全局上下文至关重要。
🔬 方法详解
问题定义:论文旨在解决现有基于LLM的文本嵌入模型在处理长文本和需要推理的任务时性能不足的问题。LLM通常采用自回归的方式进行预训练,其单向注意力机制无法有效捕捉文本中的双向依赖关系,导致在需要全局上下文信息的任务中表现不佳。
核心思路:论文的核心思路是利用扩散语言模型固有的双向架构来学习文本嵌入。扩散模型通过逐步添加噪声到数据,然后再逐步去噪恢复数据的方式进行训练,这种双向过程使其能够更好地理解文本中的全局上下文信息。
技术框架:该方法使用扩散语言模型作为文本编码器,将文本映射到嵌入向量空间。具体流程包括:首先,使用扩散模型对文本进行编码,得到文本的嵌入表示;然后,将这些嵌入表示用于下游的文本嵌入任务,例如文档检索、文本分类等。
关键创新:该论文的关键创新在于首次将扩散语言模型应用于文本嵌入任务,并证明了其在长文本和推理任务上的优越性。与传统的自回归模型相比,扩散模型能够更好地捕捉文本中的双向依赖关系,从而提高文本嵌入的质量。
关键设计:论文可能涉及的关键设计包括:扩散模型的具体架构(例如,采用何种噪声添加和去除策略),损失函数的设计(例如,如何衡量重构文本与原始文本之间的差异),以及如何将扩散模型的输出映射到文本嵌入向量空间。具体的参数设置和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在长文档检索任务上比基于LLM的嵌入模型提升了20%,在推理密集型检索任务上提升了8%,在指令跟随检索任务上提升了2%。这些结果表明,扩散语言模型在处理需要全局上下文信息的任务时具有显著优势。
🎯 应用场景
该研究成果可广泛应用于信息检索、文档分类、问答系统等领域。特别是在需要处理长文本和复杂推理的任务中,例如法律文档检索、科学文献分析等,该方法具有重要的应用价值。未来,该方法有望推动相关领域的技术发展,提升人工智能系统的理解和推理能力。
📄 摘要(原文)
Large language model (LLM)-based embedding models, benefiting from large scale pre-training and post-training, have begun to surpass BERT and T5-based models on general-purpose text embedding tasks such as document retrieval. However, a fundamental limitation of LLM embeddings lies in the unidirectional attention used during autoregressive pre-training, which misaligns with the bidirectional nature of text embedding tasks. To this end, We propose adopting diffusion language models for text embeddings, motivated by their inherent bidirectional architecture and recent success in matching or surpassing LLMs especially on reasoning tasks. We present the first systematic study of the diffusion language embedding model, which outperforms the LLM-based embedding model by 20% on long-document retrieval, 8% on reasoning-intensive retrieval, 2% on instruction-following retrieval, and achieve competitive performance on traditional text embedding benchmarks. Our analysis verifies that bidirectional attention is crucial for encoding global context in long and complex text.