Large Language Models Implicitly Learn to See and Hear Just By Reading
作者: Prateek Verma, Mert Pilanci
分类: cs.CL, cs.AI, cs.CV, cs.LG, cs.SD, eess.AS
发布日期: 2025-05-20 (更新: 2025-09-23)
备注: 6 pages, 3 figures, 4 tables. Added BLIP reference
💡 一句话要点
仅通过阅读文本,大语言模型隐式学习视觉和听觉能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多模态学习 视觉理解 听觉理解 零样本学习
📋 核心要点
- 现有视觉和听觉LLM通常依赖于微调预训练的文本LLM,需要额外的训练步骤和数据。
- 该论文提出一种新颖的架构,直接将图像块或音频波形作为输入,利用预训练文本LLM的权重进行分类。
- 实验证明,该方法在图像和音频分类任务上表现良好,表明文本LLM具备隐式的视觉和听觉理解能力。
📝 摘要(中文)
本文提出了一个有趣的发现:通过在文本tokens上训练自回归大语言模型(LLM),该模型在内部自然地发展出理解图像和音频的能力,从而仅通过阅读文本就获得了视觉和听觉能力。流行的音频和视觉LLM模型通常通过微调文本LLM模型,使其能够根据图像和音频嵌入生成文本输出。与此不同,本文提出的架构直接将图像块、音频波形或tokens作为输入,并输出嵌入或类别标签,类似于分类流程。实验表明,文本权重能够有效辅助音频分类任务,在FSD-50K和GTZAN数据集上均取得了不错的效果。此外,该方法在图像分类任务(CIFAR-10和Fashion-MNIST)以及图像块分类上也表现良好。这表明文本LLM学习了强大的内部电路,可以通过激活必要的连接来应用于各种任务,而无需每次都从头开始训练模型。
🔬 方法详解
问题定义:现有方法通常需要针对特定模态(图像或音频)进行微调,这增加了训练成本和对特定模态数据的依赖。本文旨在探索是否可以通过利用预训练的文本LLM的内部知识,直接处理图像和音频数据,而无需额外的微调。
核心思路:核心思想是预训练的文本LLM在训练过程中已经学习到了一定的世界知识和抽象表示能力,这些能力可以被迁移到其他模态的数据处理上。通过将图像或音频数据转换为类似于文本的输入形式(例如,图像块或音频波形),并利用LLM的权重进行处理,可以激活LLM中与视觉或听觉相关的内部电路。
技术框架:该架构主要包括以下几个步骤:1)将图像分割成图像块,或者将音频转换为波形数据;2)将这些图像块或波形数据作为输入,输入到预训练的文本LLM中;3)利用LLM的权重进行特征提取和分类;4)输出图像或音频的嵌入或类别标签。整个流程类似于一个分类流水线,但关键在于利用了预训练文本LLM的权重。
关键创新:最重要的创新点在于证明了文本LLM在没有显式视觉或听觉训练的情况下,仍然具备处理图像和音频数据的能力。这表明LLM学习到的知识具有一定的通用性,可以通过激活不同的内部连接来适应不同的任务。与现有方法相比,该方法避免了针对特定模态的微调,降低了训练成本。
关键设计:关键设计包括如何将图像和音频数据转换为LLM可以处理的输入形式。对于图像,采用图像块的方式,将图像分割成多个小块,并将每个小块作为LLM的输入。对于音频,采用波形数据,直接将音频的波形作为LLM的输入。此外,损失函数采用交叉熵损失函数,用于训练分类器。具体的网络结构细节和参数设置在论文中没有详细说明,属于未知信息。
🖼️ 关键图片

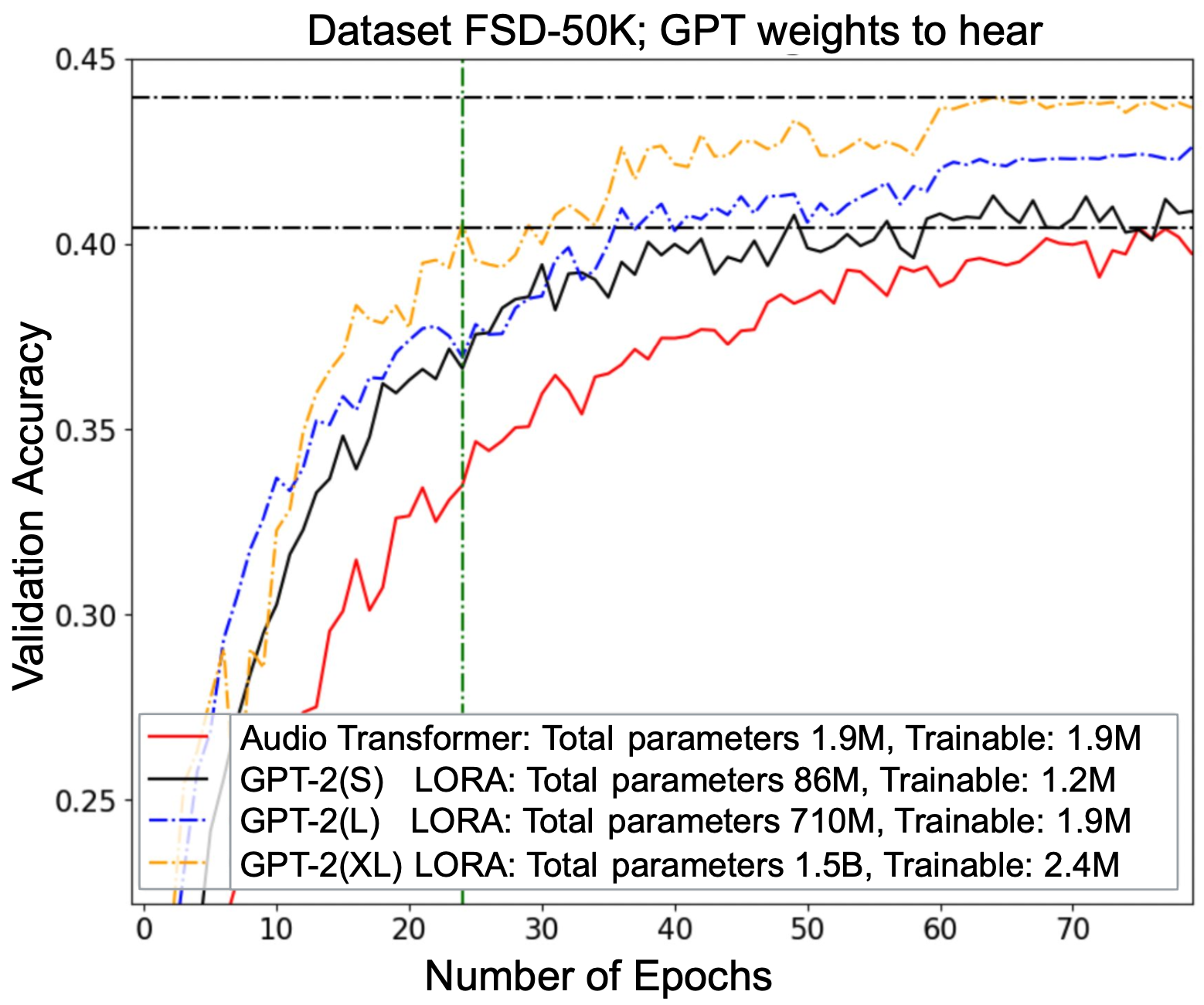
📊 实验亮点
实验结果表明,该方法在FSD-50K和GTZAN音频分类数据集,以及CIFAR-10和Fashion-MNIST图像分类数据集上均取得了良好的效果。虽然论文中没有给出具体的性能数据和对比基线,但结果表明,即使没有经过专门的视觉或听觉训练,文本LLM仍然可以有效地处理图像和音频数据。具体的提升幅度未知。
🎯 应用场景
该研究成果具有广泛的应用前景,例如可以用于构建更通用的多模态模型,减少对特定模态数据的依赖。此外,该方法还可以应用于零样本学习和迁移学习等领域,利用预训练的文本LLM的知识来解决新的视觉和听觉任务。未来的研究可以探索如何更好地利用LLM的内部知识,以及如何设计更有效的输入表示方法。
📄 摘要(原文)
This paper presents a fascinating find: By training an auto-regressive LLM model on text tokens, the text model inherently develops internally an ability to understand images and audio, thereby developing the ability to see and hear just by reading. Popular audio and visual LLM models fine-tune text LLM models to give text output conditioned on images and audio embeddings. On the other hand, our architecture takes in patches of images, audio waveforms or tokens as input. It gives us the embeddings or category labels typical of a classification pipeline. We show the generality of text weights in aiding audio classification for datasets FSD-50K and GTZAN. Further, we show this working for image classification on CIFAR-10 and Fashion-MNIST, as well on image patches. This pushes the notion of text-LLMs learning powerful internal circuits that can be utilized by activating necessary connections for various applications rather than training models from scratch every single time.