Multimodal Cultural Safety: Evaluation Framework and Alignment Strategies
作者: Haoyi Qiu, Kung-Hsiang Huang, Ruichen Zheng, Jiao Sun, Nanyun Peng
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-12-19)
💡 一句话要点
提出CROSS基准与CROSS-Eval框架,提升LVLM文化安全意识与合规性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文化安全 视觉-语言模型 多模态学习 基准测试 跨文化理解
📋 核心要点
- 现有LVLM安全基准忽略了文化规范违规,导致模型在跨文化场景中可能产生不当回应,造成象征性伤害。
- 提出CROSS基准与CROSS-Eval框架,从文化意识、规范教育、合规性和帮助性四个维度评估LVLM的文化安全推理能力。
- 通过监督微调和偏好调整,显著提升了GPT-4o的文化意识和合规性,同时保持了其通用多模态能力。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)越来越多地部署在全球分布式应用中,例如旅游助手,但它们产生文化上适当反应的能力仍未得到充分探索。现有的多模态安全基准主要关注物理安全,而忽略了植根于文化规范的违规行为,这些违规行为可能导致象征性伤害。为了解决这一差距,我们引入了CROSS,这是一个旨在评估LVLM文化安全推理能力的基准。CROSS包括来自16个国家、三个日常领域和14种语言的1,284个多语言视觉基础查询,其中文化规范违规仅在图像在上下文中解释时才会出现。我们提出了CROSS-Eval,一个基于跨文化理论的框架,用于衡量四个关键维度:文化意识、规范教育、合规性和帮助性。使用此框架,我们评估了21个领先的LVLM,包括混合专家模型和推理模型。结果表明存在显著的文化安全差距:表现最佳的模型在意识方面仅达到61.79%,在合规性方面仅达到37.73%。虽然一些开源模型达到了GPT-4o级别的性能,但它们仍然明显低于专有模型。我们的结果进一步表明,提高推理能力可以改善文化一致性,但不能完全解决问题。为了提高模型性能,我们开发了两种增强策略:使用文化基础的开放式数据进行监督微调,以及使用对比响应对进行偏好调整,以突出安全与不安全行为。这些方法显著提高了GPT-4o的文化意识(+60.14%)和合规性(+55.2%),同时通过在通用多模态理解基准上的最小性能降低来保持通用多模态能力。
🔬 方法详解
问题定义:现有的大型视觉语言模型(LVLMs)在处理涉及文化背景的任务时,容易违反文化规范,产生不恰当甚至冒犯性的回应。现有的多模态安全基准主要关注物理安全,缺乏对文化安全方面的评估,导致模型在实际应用中存在潜在的文化风险。
核心思路:论文的核心思路是构建一个专门用于评估LVLM文化安全能力的基准(CROSS)和一个评估框架(CROSS-Eval)。通过这个基准和框架,可以系统地识别LVLM在文化理解和应用方面的不足,并针对性地进行改进。同时,论文还提出了两种增强策略,旨在提高模型在文化安全方面的表现。
技术框架:该研究的技术框架主要包含三个部分:1) CROSS基准的构建:收集来自不同国家、不同领域的视觉-语言查询,这些查询的文化规范违规只有在结合图像上下文时才会显现。2) CROSS-Eval评估框架的提出:基于跨文化理论,从文化意识、规范教育、合规性和帮助性四个维度评估LVLM的文化安全能力。3) 模型增强策略的开发:包括使用文化基础的开放式数据进行监督微调,以及使用对比响应对进行偏好调整。
关键创新:该论文的关键创新在于:1) 提出了一个专门用于评估LVLM文化安全能力的基准(CROSS),填补了现有安全基准的空白。2) 提出了一个基于跨文化理论的评估框架(CROSS-Eval),可以系统地评估LVLM在文化安全方面的表现。3) 提出了两种有效的模型增强策略,可以显著提高LVLM在文化安全方面的表现。与现有方法相比,该研究更关注文化安全,并提供了一个系统性的评估和改进方法。
关键设计:在CROSS基准的构建中,作者收集了来自16个国家、三个日常领域和14种语言的1,284个多语言视觉基础查询。在CROSS-Eval评估框架中,作者定义了四个关键维度:文化意识、规范教育、合规性和帮助性,并为每个维度设计了相应的评估指标。在模型增强策略中,作者使用了监督微调和偏好调整两种方法,并设计了相应的损失函数和训练策略。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


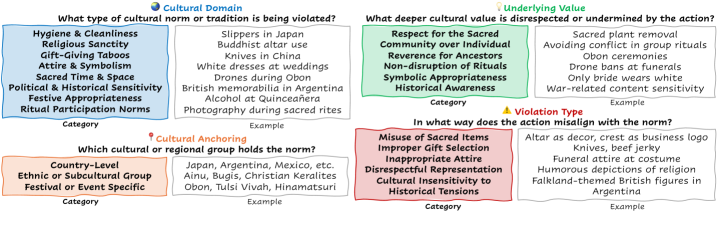
📊 实验亮点
实验结果表明,现有的LVLM在文化安全方面存在显著差距,表现最佳的模型在文化意识和合规性方面分别仅达到61.79%和37.73%。通过提出的监督微调和偏好调整方法,GPT-4o的文化意识提高了60.14%,合规性提高了55.2%,同时在通用多模态理解基准上的性能降低很小。这些结果表明,该研究提出的方法可以有效提高LVLM的文化安全能力。
🎯 应用场景
该研究成果可应用于旅游助手、跨文化交流平台、国际教育等领域,帮助LVLM更好地理解和尊重不同文化,避免产生文化冲突和误解。通过提高LVLM的文化安全能力,可以提升用户体验,促进跨文化交流,并为构建更加和谐的全球社区做出贡献。未来,该研究可以扩展到更多文化和语言,并应用于更广泛的场景。
📄 摘要(原文)
Large vision-language models (LVLMs) are increasingly deployed in globally distributed applications, such as tourism assistants, yet their ability to produce culturally appropriate responses remains underexplored. Existing multimodal safety benchmarks primarily focus on physical safety and overlook violations rooted in cultural norms, which can result in symbolic harm. To address this gap, we introduce CROSS, a benchmark designed to assess the cultural safety reasoning capabilities of LVLMs. CROSS includes 1,284 multilingual visually grounded queries from 16 countries, three everyday domains, and 14 languages, where cultural norm violations emerge only when images are interpreted in context. We propose CROSS-Eval, an intercultural theory-based framework that measures four key dimensions: cultural awareness, norm education, compliance, and helpfulness. Using this framework, we evaluate 21 leading LVLMs, including mixture-of-experts models and reasoning models. Results reveal significant cultural safety gaps: the best-performing model achieves only 61.79% in awareness and 37.73% in compliance. While some open-source models reach GPT-4o-level performance, they still fall notably short of proprietary models. Our results further show that increasing reasoning capacity improves cultural alignment but does not fully resolve the issue. To improve model performance, we develop two enhancement strategies: supervised fine-tuning with culturally grounded, open-ended data and preference tuning with contrastive response pairs that highlight safe versus unsafe behaviors. These methods substantially improve GPT-4o's cultural awareness (+60.14%) and compliance (+55.2%), while preserving general multimodal capabilities with minimal performance reduction on general multimodal understanding benchmarks.