Too Long, Didn't Model: Decomposing LLM Long-Context Understanding With Novels
作者: Sil Hamilton, Rebecca M. M. Hicke, Matthew Wilkens, David Mimno
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-20
💡 一句话要点
提出TLDM基准,揭示LLM在长文本小说理解中超过64k tokens后性能显著下降
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 大型语言模型 基准测试 小说分析 叙事推理
📋 核心要点
- 现有LLM长文本理解评估方法不足,缺乏对复杂语义依赖和叙事结构的有效测试。
- 提出TLDM基准,利用小说作为测试LLM在长程语义理解和叙事推理能力的案例。
- 实验表明,现有LLM在处理超过64k tokens的小说时,理解能力显著下降,亟需改进。
📝 摘要(中文)
尽管大型语言模型(LLM)的上下文长度已扩展到数百万个tokens,但评估其在“大海捞针”方法之外的有效性仍然很困难。我们认为,小说提供了一个微妙、复杂的结构和长程语义依赖的案例研究,其长度通常超过128k个tokens。受到计算小说分析工作的启发,我们发布了“太长,没建模”(TLDM)基准,该基准测试模型报告情节摘要、故事世界配置和流逝叙事时间的能力。我们发现,七个经过测试的前沿LLM中,没有一个能在超过64k个tokens后保持稳定的理解。我们的结果表明,语言模型开发者在评估复杂长上下文场景中的模型性能时,必须超越“中间迷失”基准。为了帮助进一步开发,我们发布了TLDM基准以及参考代码和数据。
🔬 方法详解
问题定义:论文旨在解决现有LLM在长文本理解方面的评估困境。现有评估方法,如“大海捞针”,无法充分测试模型对复杂语义依赖和叙事结构的理解能力。小说作为一种长文本形式,包含了丰富的语义信息和复杂的叙事结构,可以作为评估LLM长文本理解能力的理想测试对象。现有方法难以有效评估LLM在长文本小说中的情节理解、故事世界配置和叙事时间推断能力。
核心思路:论文的核心思路是利用小说作为测试LLM长文本理解能力的基准。通过设计一系列任务,例如情节摘要、故事世界配置和叙事时间推断,来评估LLM在处理长文本小说时的理解能力。这种方法能够更全面地评估LLM对长程语义依赖和叙事结构的理解能力,从而弥补现有评估方法的不足。
技术框架:TLDM基准测试框架主要包含以下几个模块:1) 数据集构建:收集包含不同类型和风格的小说,并进行预处理。2) 任务设计:设计情节摘要、故事世界配置和叙事时间推断等任务,用于评估LLM的理解能力。3) 模型评估:使用不同的LLM模型在TLDM基准上进行测试,并分析其性能表现。4) 结果分析:分析实验结果,揭示LLM在长文本理解方面的优势和不足。
关键创新:该论文的关键创新在于提出了TLDM基准,利用小说作为评估LLM长文本理解能力的测试对象。与现有的“大海捞针”等评估方法相比,TLDM基准能够更全面地评估LLM对复杂语义依赖和叙事结构的理解能力。此外,该论文还设计了一系列新的任务,例如情节摘要、故事世界配置和叙事时间推断,用于评估LLM在长文本小说中的理解能力。
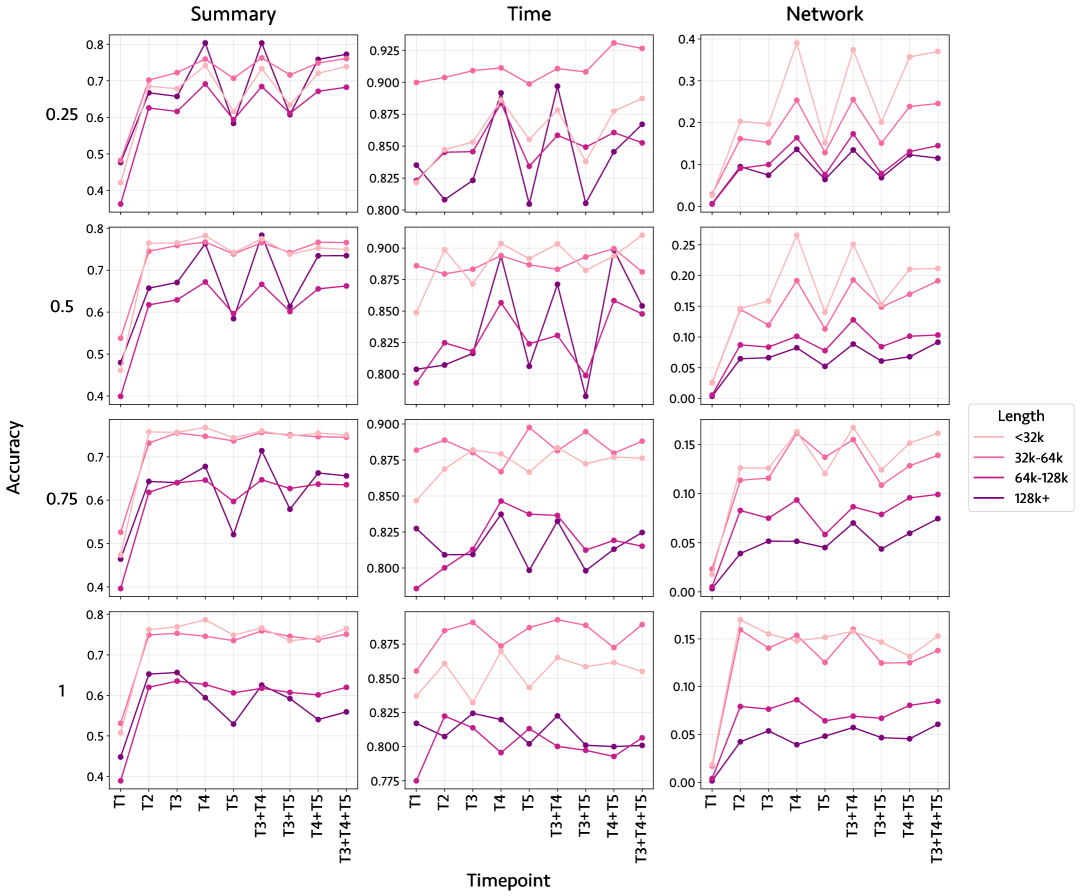
关键设计:TLDM基准的关键设计包括:1) 小说数据集的选择:选择包含不同类型和风格的小说,以保证基准的泛化能力。2) 任务设计:设计情节摘要、故事世界配置和叙事时间推断等任务,这些任务能够有效评估LLM对长文本小说中关键信息的理解能力。3) 评估指标:使用准确率、召回率和F1值等指标来评估LLM在不同任务上的性能表现。4) 上下文长度设置:实验中测试了不同上下文长度下LLM的性能,发现超过64k tokens后性能显著下降。
🖼️ 关键图片
📊 实验亮点
实验结果表明,七个前沿LLM在TLDM基准上,超过64k tokens后理解能力显著下降,表明现有模型在处理长文本时存在局限性。该研究强调了现有评估方法的不足,并为LLM开发者提供了新的评估工具和方向,促使他们关注模型在复杂长上下文场景下的性能。
🎯 应用场景
该研究成果可应用于提升LLM在处理长文本数据(如法律文档、新闻报道、科学论文等)时的理解能力。通过TLDM基准,可以更好地评估和改进LLM在长文本场景下的性能,从而提高其在信息检索、文本摘要、问答系统等领域的应用效果。未来,该研究可以推动LLM在长文本理解方面的进一步发展。
📄 摘要(原文)
Although the context length of large language models (LLMs) has increased to millions of tokens, evaluating their effectiveness beyond needle-in-a-haystack approaches has proven difficult. We argue that novels provide a case study of subtle, complicated structure and long-range semantic dependencies often over 128k tokens in length. Inspired by work on computational novel analysis, we release the Too Long, Didn't Model (TLDM) benchmark, which tests a model's ability to report plot summary, storyworld configuration, and elapsed narrative time. We find that none of seven tested frontier LLMs retain stable understanding beyond 64k tokens. Our results suggest language model developers must look beyond "lost in the middle" benchmarks when evaluating model performance in complex long-context scenarios. To aid in further development we release the TLDM benchmark together with reference code and data.