Scaling Laws for State Dynamics in Large Language Models
作者: Jacob X Li, Shreyas S Raman, Jessica Wan, Fahad Samman, Jazlyn Lin
分类: cs.CL, cs.AI
发布日期: 2025-05-20
备注: 16 pages; 23 figures
💡 一句话要点
研究揭示大语言模型在状态动态建模中面临的挑战,并探究其内部状态追踪机制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 状态动态 状态追踪 注意力机制 激活修补
📋 核心要点
- 大语言模型在需要状态追踪的任务中表现不佳,尤其是在状态空间增大和转移稀疏的情况下,现有方法缺乏对状态转移动态的深入理解。
- 该研究通过在不同领域(如盒子追踪、DFA序列和文本游戏)评估LLMs的下一状态预测准确率,来分析其状态动态建模能力。
- 实验表明,LLMs的准确率随着状态空间增大而下降,并识别出负责状态信息传播的关键注意力头,揭示了状态追踪的分布式交互机制。
📝 摘要(中文)
本文研究了大语言模型(LLMs)在状态转移动态建模方面的能力,尤其是在需要内部状态追踪的任务中。作者在三个领域评估了LLMs对确定性状态动态的捕捉能力:盒子追踪、抽象DFA序列和复杂文本游戏,每个领域都可以形式化为有限状态系统。研究发现,随着状态空间增大和转移变得稀疏,LLMs的下一状态预测准确率会下降。GPT-2 XL在低复杂度设置下达到约70%的准确率,但当盒子或状态的数量超过5或10时,准确率降至30%以下。在DFA任务中,当状态数>10且转移数<30时,Pythia-1B的准确率未能超过50%。通过激活修补,作者识别出负责传播状态信息的注意力头:GPT-2 XL的第22层头20,以及Pythia-1B的第10、11、12和14层头。虽然这些头成功地移动了相关的状态特征,但动作信息没有可靠地路由到最终的token,表明联合状态-动作推理能力较弱。研究结果表明,LLMs中的状态追踪源于下一token头的分布式交互,而不是显式的符号计算。
🔬 方法详解
问题定义:现有的大语言模型在处理需要内部状态追踪的任务时,其状态转移动态建模能力不足。尤其是在状态空间较大或状态转移较为稀疏的情况下,模型的预测准确率会显著下降。现有的方法缺乏对模型内部状态追踪机制的深入理解,难以解释模型如何维护和更新状态信息。
核心思路:该研究的核心思路是通过设计一系列可形式化为有限状态系统的任务,来评估LLMs对确定性状态动态的捕捉能力。通过分析模型在不同复杂度任务上的表现,以及识别负责状态信息传播的关键注意力头,来揭示模型内部的状态追踪机制。研究重点在于理解模型如何利用其内部表示来模拟状态转移,以及状态和动作信息如何相互作用。
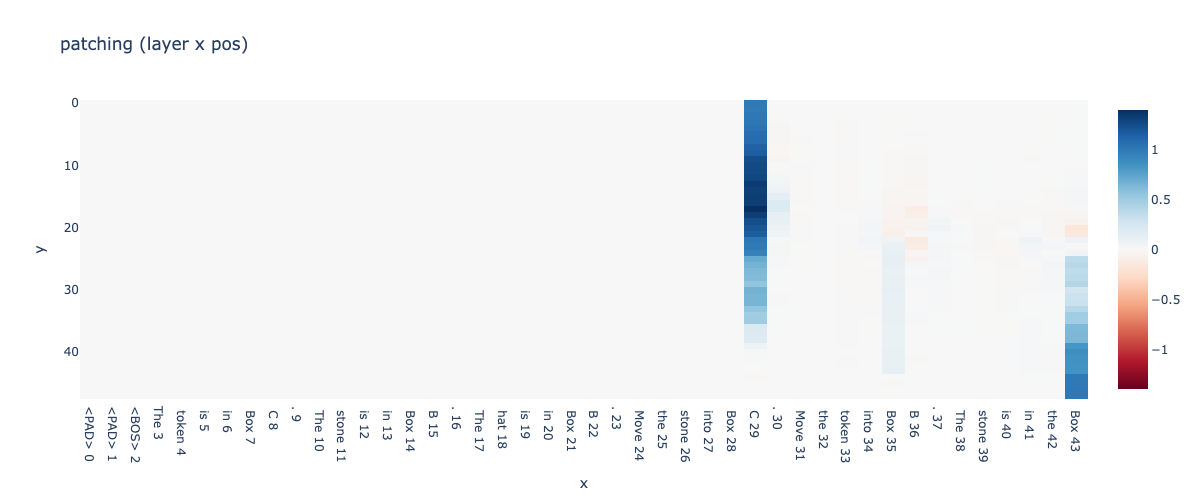
技术框架:该研究的整体框架包括以下几个主要步骤: 1. 任务设计:设计了三个领域(盒子追踪、抽象DFA序列和复杂文本游戏)的任务,每个任务都可以形式化为有限状态系统。 2. 模型评估:使用GPT-2 XL和Pythia-1B等LLMs在这些任务上进行下一状态预测,并评估其准确率。 3. 激活修补:使用激活修补技术来识别负责传播状态信息的注意力头。 4. 信息路由分析:分析状态和动作信息如何在模型内部路由,以及它们如何影响最终的预测结果。
关键创新:该研究的关键创新在于: 1. 系统性地评估了LLMs在不同复杂度状态动态建模任务上的表现。 2. 通过激活修补技术,识别出负责状态信息传播的关键注意力头。 3. 揭示了LLMs中的状态追踪源于下一token头的分布式交互,而不是显式的符号计算。
关键设计: 1. 任务设计:精心设计的任务涵盖了不同类型的状态转移动态,从简单的盒子追踪到复杂的文本游戏。 2. 激活修补:使用激活修补技术来识别负责传播状态信息的注意力头,具体方法是替换特定头的激活值,观察对模型输出的影响。 3. 模型选择:选择了GPT-2 XL和Pythia-1B等不同规模的LLMs,以便比较不同模型在状态动态建模方面的能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GPT-2 XL在低复杂度设置下达到约70%的准确率,但当盒子或状态的数量超过5或10时,准确率降至30%以下。在DFA任务中,当状态数>10且转移数<30时,Pythia-1B的准确率未能超过50%。通过激活修补,识别出GPT-2 XL Layer 22 Head 20,以及Pythia-1B Layers 10, 11, 12, and 14等关键注意力头。
🎯 应用场景
该研究成果可应用于提升LLMs在需要复杂状态管理的任务中的性能,例如对话系统、游戏AI和机器人控制。通过理解LLMs如何追踪和更新状态,可以设计更有效的训练方法和模型架构,从而提高模型在这些任务中的可靠性和泛化能力。此外,该研究还有助于开发更具解释性的LLMs,使其行为更容易理解和预测。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used in tasks requiring internal state tracking, yet their ability to model state transition dynamics remains poorly understood. We evaluate how well LLMs capture deterministic state dynamics across 3 domains: Box Tracking, Abstract DFA Sequences, and Complex Text Games, each formalizable as a finite-state system. Across tasks, we find that next-state prediction accuracy degrades with increasing state-space size and sparse transitions. GPT-2 XL reaches about 70% accuracy in low-complexity settings but drops below 30% when the number of boxes or states exceeds 5 or 10, respectively. In DFA tasks, Pythia-1B fails to exceed 50% accuracy when the number of states is > 10 and transitions are < 30. Through activation patching, we identify attention heads responsible for propagating state information: GPT-2 XL Layer 22 Head 20, and Pythia-1B Heads at Layers 10, 11, 12, and 14. While these heads successfully move relevant state features, action information is not reliably routed to the final token, indicating weak joint state-action reasoning. Our results suggest that state tracking in LLMs emerges from distributed interactions of next-token heads rather than explicit symbolic computation.