WebNovelBench: Placing LLM Novelists on the Web Novel Distribution
作者: Leon Lin, Jun Zheng, Haidong Wang
分类: cs.CL, cs.AI
发布日期: 2025-05-20
💡 一句话要点
提出WebNovelBench,用于评估LLM在长文本小说生成中的能力,并将其置于真实网络小说分布中进行对比。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 大型语言模型 小说创作 自动评估 基准测试
📋 核心要点
- 现有长文本生成评估基准缺乏规模、多样性和客观性,难以有效评估LLM的叙事能力。
- WebNovelBench利用大规模中文网络小说数据集,将评估转化为概要到故事的生成任务,并提出多维度评估框架。
- 实验表明,WebNovelBench能有效区分人类作品、流行小说和LLM生成内容,并对多个LLM进行了全面评估和排名。
📝 摘要(中文)
本文提出WebNovelBench,一个专门为评估大型语言模型(LLM)长文本小说生成能力的新基准。现有基准通常缺乏必要的规模、多样性或客观的评估指标,因此评估LLM的长文本叙事能力仍然是一个巨大的挑战。WebNovelBench利用超过4000部中文网络小说的海量数据集,将评估任务定义为从概要到故事的生成。我们提出了一个多方面的框架,包含八个叙事质量维度,通过LLM-as-Judge方法自动评估。使用主成分分析法聚合分数,并将其映射到相对于人类作品的百分位数排名。实验表明,WebNovelBench能够有效区分人类撰写的杰作、流行的网络小说和LLM生成的内容。我们对24个最先进的LLM进行了全面分析,对它们的叙事能力进行排名,并为未来的发展提供了见解。该基准提供了一种可扩展、可复制和数据驱动的方法,用于评估和推进LLM驱动的叙事生成。
🔬 方法详解
问题定义:论文旨在解决如何有效、客观地评估大型语言模型(LLM)在长文本小说生成方面的能力。现有方法的痛点在于缺乏大规模、多样化的数据集,以及难以量化的评估指标,导致无法准确衡量LLM的叙事质量。
核心思路:论文的核心思路是构建一个基于真实网络小说分布的评估基准,即WebNovelBench。通过将LLM生成的小说与人类创作的小说进行对比,从而更客观地评估LLM的叙事能力。此外,采用LLM-as-Judge的方法,自动评估多个叙事质量维度,提高评估效率和可重复性。
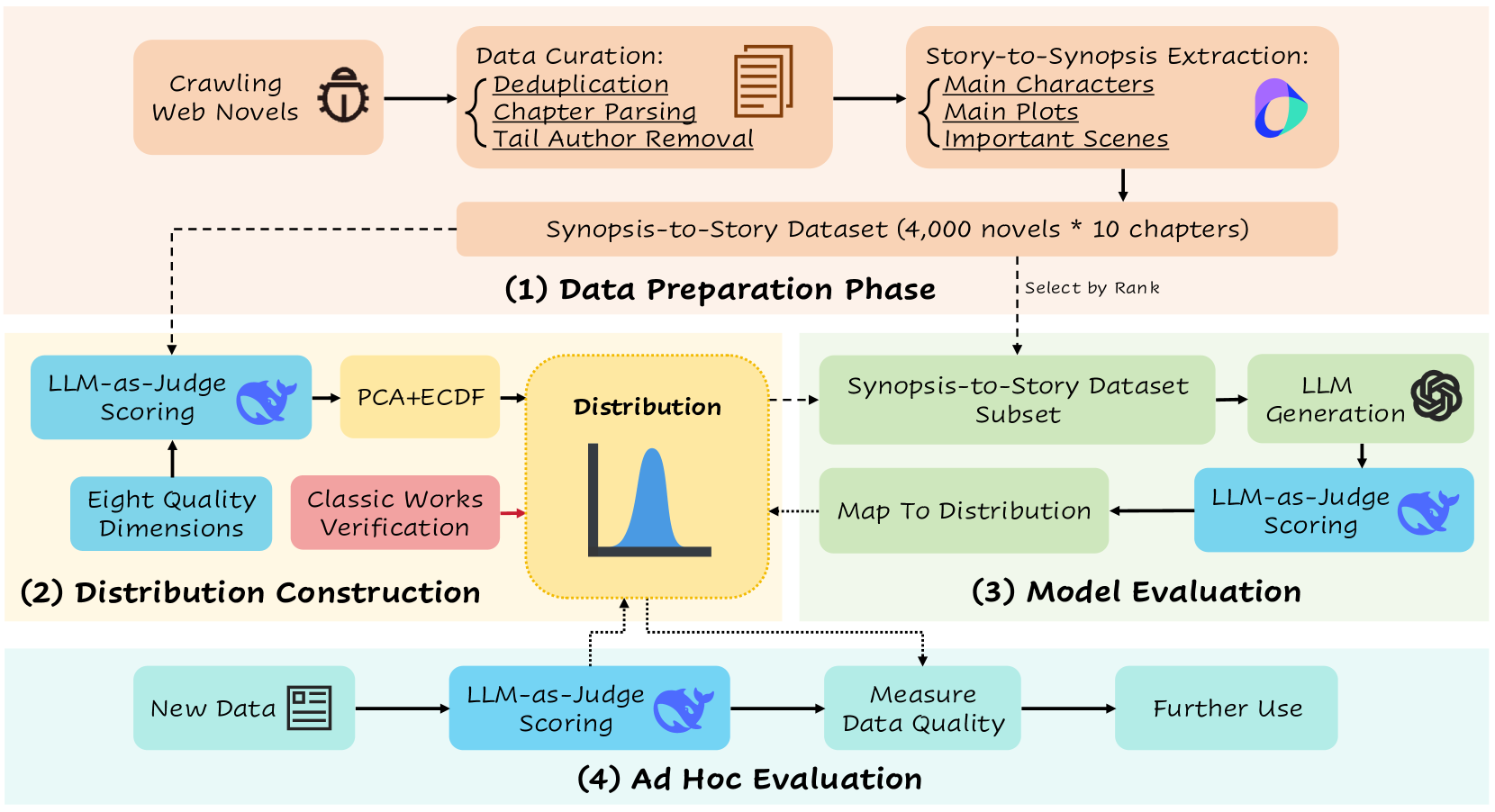
技术框架:WebNovelBench的整体框架包括以下几个主要阶段:1) 数据收集:构建包含4000+中文网络小说的大规模数据集。2) 任务定义:将评估任务定义为从小说概要生成完整故事。3) 质量评估:提出包含八个叙事质量维度的评估框架,并使用LLM-as-Judge自动评估。4) 结果分析:使用主成分分析(PCA)聚合各个维度的分数,并将其映射到相对于人类作品的百分位数排名。
关键创新:最重要的技术创新点在于构建了WebNovelBench,一个大规模、多样化的网络小说评估基准。此外,采用LLM-as-Judge的方法进行自动评估,提高了评估效率和客观性。与现有方法相比,WebNovelBench更贴近真实应用场景,能够更准确地反映LLM在长文本小说生成方面的能力。
关键设计:在质量评估方面,论文提出了八个叙事质量维度,包括情节连贯性、人物塑造、文笔流畅性等。LLM-as-Judge的具体实现细节未知,但可以推测是利用大型语言模型对生成的小说进行打分,并根据预定义的规则进行聚合。主成分分析(PCA)用于降维和特征提取,将多个维度的分数转化为一个综合的质量评分。
🖼️ 关键图片


📊 实验亮点
WebNovelBench能够有效区分人类撰写的杰作、流行的网络小说和LLM生成的内容。通过对24个最先进的LLM进行评估,论文对它们的叙事能力进行了排名,并提供了有价值的分析和见解。实验结果表明,LLM在长文本小说生成方面仍有很大的提升空间,WebNovelBench为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于提升LLM在内容创作领域的应用,例如辅助小说创作、剧本生成、游戏剧情设计等。WebNovelBench提供了一个标准化的评估平台,可以促进LLM在长文本生成方面的研究和发展,并推动相关技术的实际应用。未来,该基准可以扩展到其他语言和领域,进一步提升LLM的创作能力。
📄 摘要(原文)
Robustly evaluating the long-form storytelling capabilities of Large Language Models (LLMs) remains a significant challenge, as existing benchmarks often lack the necessary scale, diversity, or objective measures. To address this, we introduce WebNovelBench, a novel benchmark specifically designed for evaluating long-form novel generation. WebNovelBench leverages a large-scale dataset of over 4,000 Chinese web novels, framing evaluation as a synopsis-to-story generation task. We propose a multi-faceted framework encompassing eight narrative quality dimensions, assessed automatically via an LLM-as-Judge approach. Scores are aggregated using Principal Component Analysis and mapped to a percentile rank against human-authored works. Our experiments demonstrate that WebNovelBench effectively differentiates between human-written masterpieces, popular web novels, and LLM-generated content. We provide a comprehensive analysis of 24 state-of-the-art LLMs, ranking their storytelling abilities and offering insights for future development. This benchmark provides a scalable, replicable, and data-driven methodology for assessing and advancing LLM-driven narrative generation.