Context Reasoner: Incentivizing Reasoning Capability for Contextualized Privacy and Safety Compliance via Reinforcement Learning
作者: Wenbin Hu, Haoran Li, Huihao Jing, Qi Hu, Ziqian Zeng, Sirui Han, Heli Xu, Tianshu Chu, Peizhao Hu, Yangqiu Song
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-09-04)
备注: Accepted to EMNLP 2025 Main
💡 一句话要点
提出Context Reasoner,通过强化学习提升LLM在安全隐私合规方面的上下文推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 安全隐私 上下文推理 合规性 Contextual Integrity 规则奖励
📋 核心要点
- 现有LLM安全策略过度依赖模式匹配,忽略上下文推理,且缺乏对GDPR等法律标准的考量。
- Context Reasoner通过强化学习,利用规则奖励激励LLM在上下文推理中遵守安全和隐私规范。
- 实验表明,该方法显著提升了LLM在安全隐私基准测试和通用推理任务上的准确率。
📝 摘要(中文)
大型语言模型(LLMs)在展现卓越能力的同时,也带来了显著的安全和隐私风险。现有的缓解策略通常无法在风险场景中保持上下文推理能力,而是过度依赖敏感模式匹配来保护LLMs,限制了应用范围。此外,这些策略忽略了既定的安全和隐私标准,导致了系统性的法律合规风险。为了解决这些问题,本文遵循上下文完整性(CI)理论,将安全和隐私问题形式化为上下文合规问题。在CI框架下,模型与三个关键监管标准(GDPR、欧盟AI法案和HIPAA)对齐。具体而言,采用强化学习(RL)与基于规则的奖励,以激励上下文推理能力,同时增强对安全和隐私规范的遵守。实验结果表明,该方法不仅显著提高了法律合规性(在安全/隐私基准测试中实现了+8.58%的准确率提升),而且进一步提高了通用推理能力。对于OpenThinker-7B,一个强大的推理模型,在各种主题上显著优于其基础模型Qwen2.5-7B-Instruct,该方法增强了其通用推理能力,在MMLU和LegalBench基准测试中分别实现了+2.05%和+8.98%的准确率提升。
🔬 方法详解
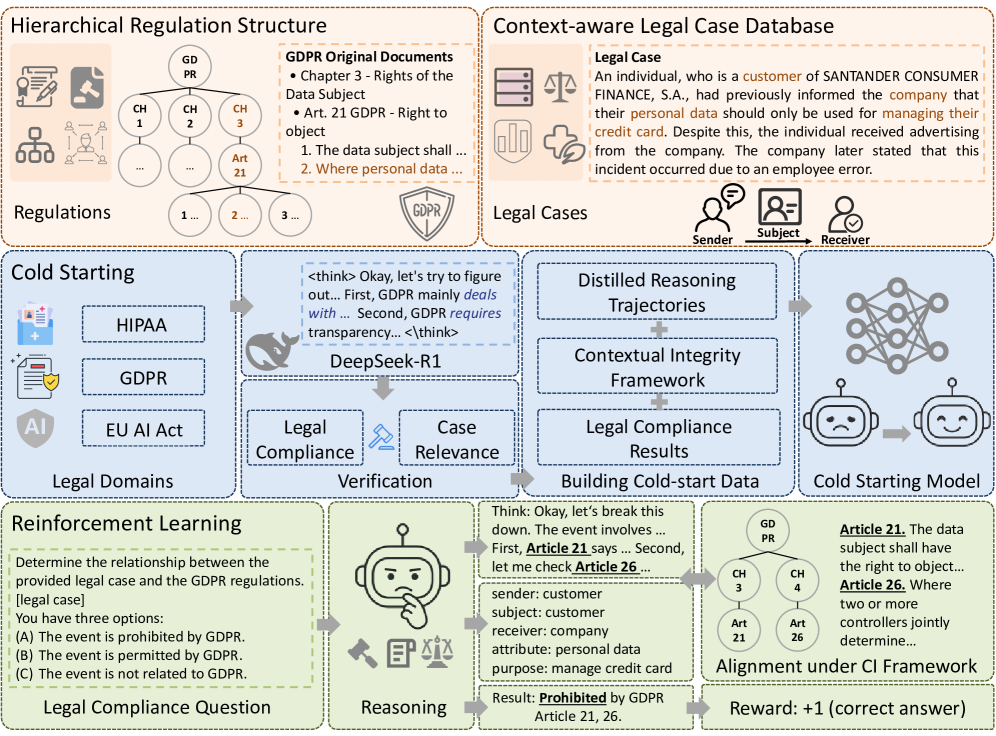
问题定义:现有的大型语言模型在处理安全和隐私相关问题时,往往依赖于简单的模式匹配,缺乏对上下文信息的深入理解和推理能力。这种方法不仅容易被绕过,而且忽略了法律法规(如GDPR、HIPAA等)对数据处理的合规性要求。因此,需要一种能够结合上下文信息进行推理,并确保模型行为符合安全和隐私标准的方法。
核心思路:本文的核心思路是将安全和隐私问题转化为上下文合规问题,并利用强化学习来训练模型。通过定义基于规则的奖励函数,激励模型在生成响应时考虑到上下文信息,并遵守相关的安全和隐私规范。这种方法旨在提升模型在复杂场景下的推理能力,同时确保其行为符合法律法规的要求。
技术框架:Context Reasoner的技术框架主要包括以下几个模块:1) 上下文编码器:用于提取输入文本的上下文信息。2) 策略网络:基于上下文信息生成响应。3) 奖励函数:根据生成的响应是否符合安全和隐私规范,以及是否具有良好的推理能力,给出奖励信号。4) 强化学习算法:利用奖励信号更新策略网络的参数,使其能够生成更安全、更合规的响应。整个流程通过强化学习不断迭代优化,提升模型在上下文推理和安全隐私合规方面的能力。
关键创新:该方法最重要的创新点在于将上下文完整性(Contextual Integrity, CI)理论引入到LLM的安全和隐私保护中,并利用强化学习来训练模型。与传统的基于模式匹配的方法相比,该方法能够更好地理解上下文信息,并根据不同的场景采取不同的策略。此外,该方法还考虑了法律法规的合规性要求,确保模型行为符合相关的安全和隐私标准。
关键设计:奖励函数的设计是关键。它基于预定义的规则,评估模型生成的响应是否违反了安全和隐私规范,例如是否泄露了个人敏感信息,是否符合GDPR的要求等。同时,奖励函数也考虑了响应的质量,例如是否具有逻辑性,是否能够回答用户的问题等。强化学习算法采用的是PPO(Proximal Policy Optimization),通过限制策略更新的幅度,保证训练的稳定性。
🖼️ 关键图片
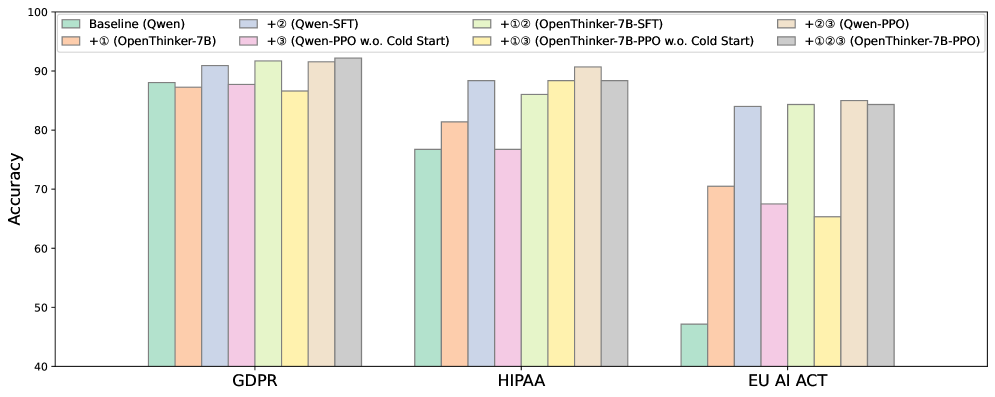

📊 实验亮点
实验结果表明,Context Reasoner在安全/隐私基准测试中实现了+8.58%的准确率提升。对于OpenThinker-7B模型,在MMLU和LegalBench基准测试中分别实现了+2.05%和+8.98%的准确率提升。这些结果表明,该方法不仅能够提高LLM的安全和隐私合规性,而且能够进一步提升其通用推理能力。
🎯 应用场景
Context Reasoner可应用于各种需要处理敏感信息的场景,例如医疗健康、金融服务、法律咨询等。它可以帮助企业构建更加安全和合规的LLM应用,降低数据泄露和法律风险。未来,该技术有望成为LLM安全和隐私保护的重要组成部分,推动人工智能技术的健康发展。
📄 摘要(原文)
While Large Language Models (LLMs) exhibit remarkable capabilities, they also introduce significant safety and privacy risks. Current mitigation strategies often fail to preserve contextual reasoning capabilities in risky scenarios. Instead, they rely heavily on sensitive pattern matching to protect LLMs, which limits the scope. Furthermore, they overlook established safety and privacy standards, leading to systemic risks for legal compliance. To address these gaps, we formulate safety and privacy issues into contextualized compliance problems following the Contextual Integrity (CI) theory. Under the CI framework, we align our model with three critical regulatory standards: GDPR, EU AI Act, and HIPAA. Specifically, we employ reinforcement learning (RL) with a rule-based reward to incentivize contextual reasoning capabilities while enhancing compliance with safety and privacy norms. Through extensive experiments, we demonstrate that our method not only significantly enhances legal compliance (achieving a +8.58% accuracy improvement in safety/privacy benchmarks) but also further improves general reasoning capability. For OpenThinker-7B, a strong reasoning model that significantly outperforms its base model Qwen2.5-7B-Instruct across diverse subjects, our method enhances its general reasoning capabilities, with +2.05% and +8.98% accuracy improvement on the MMLU and LegalBench benchmark, respectively.