Can Pruning Improve Reasoning? Revisiting Long-CoT Compression with Capability in Mind for Better Reasoning
作者: Shangziqi Zhao, Jiahao Yuan, Jinyang Wu, Zhenglin Wang, Guisong Yang, Usman Naseem
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-12-23)
备注: 19 pages,6 figures
💡 一句话要点
提出Prune-on-Logic框架,通过剪枝提升Long-CoT在小模型上的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长链式思考 CoT压缩 模型剪枝 小型语言模型 推理能力 结构化学习 自验证 能力对齐
📋 核心要点
- Long-CoT推理虽然提升了LLM的准确率,但其冗余性难以有效迁移到小型模型。
- Prune-on-Logic框架将Long-CoT转化为逻辑图,通过自验证约束选择性地剪枝低效推理步骤。
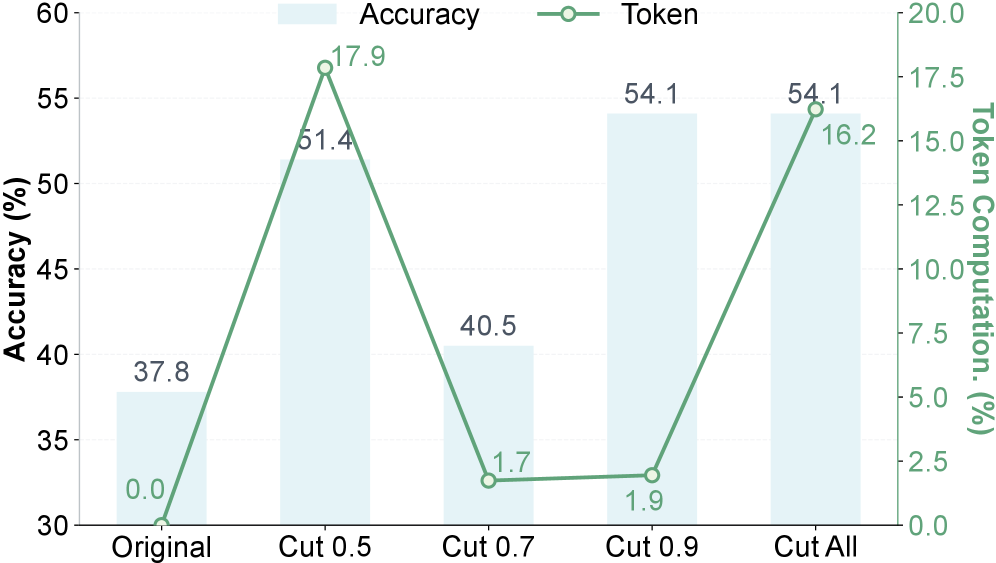
- 实验表明,验证剪枝能持续提升准确率并减少token使用,尤其对大型模型效果更显著。
📝 摘要(中文)
长链式思考(Long-CoT)推理提高了大型语言模型(LLMs)的准确性,但其冗长、自反思的风格常常阻碍其有效提炼到小型语言模型(SLMs)中。本文从能力对齐的角度重新审视Long-CoT压缩,并提出问题:剪枝能否提高推理能力?我们提出了Prune-on-Logic,这是一个结构感知的框架,它将Long-CoT转换为逻辑图,并在自我验证约束下选择性地剪除低效的推理步骤。通过对三种剪枝策略(针对整个链、核心推理和验证)的系统分析,我们发现验证剪枝始终提高准确性并减少token使用,而剪除推理步骤或不加选择的剪枝会降低性能。我们的研究表明,有效的剪枝使监督与模型容量对齐,而不仅仅是缩短输入。这种优势在任务、模型规模和CoT能力上都成立,更大的模型由于更丰富但更冗余的推理而从剪枝中获益更多。我们的实验结果表明,剪枝是一种结构优化策略,用于使CoT推理与SLM容量对齐。
🔬 方法详解
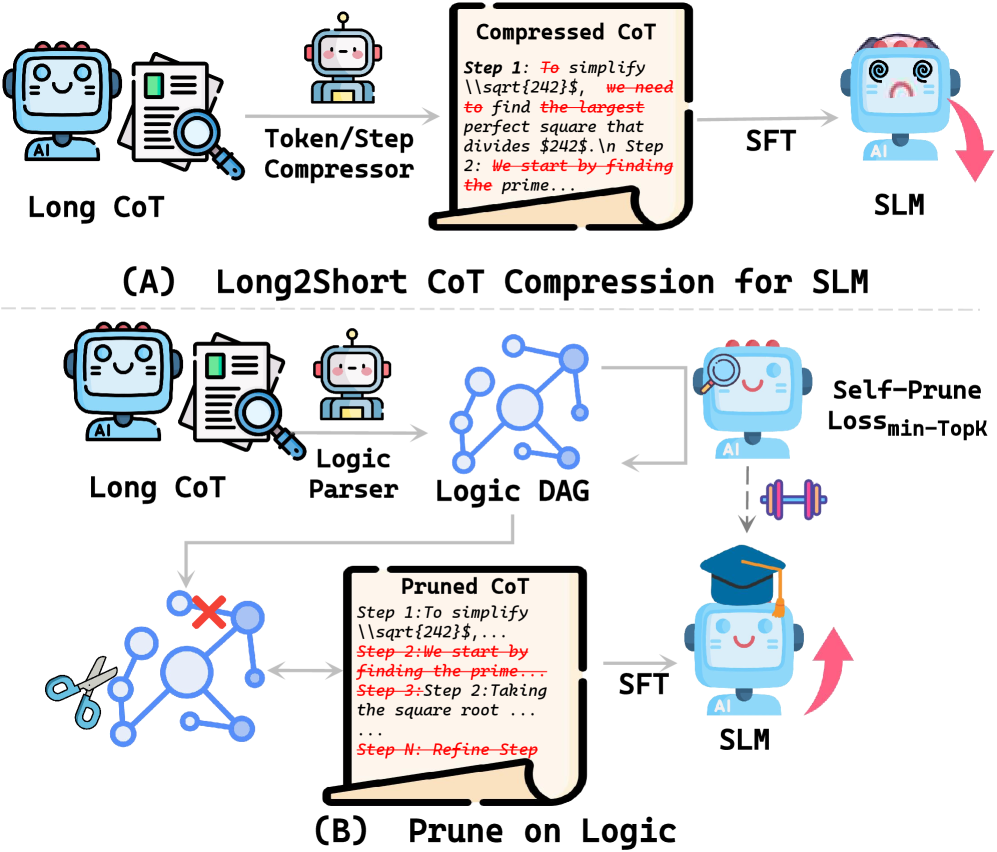
问题定义:论文旨在解决将大型语言模型的长链式思考(Long-CoT)推理能力迁移到小型语言模型(SLMs)时遇到的困难。Long-CoT虽然能提升LLM的推理准确性,但其冗长的特性使得直接蒸馏到SLM效果不佳。现有方法通常侧重于缩短CoT的长度,但忽略了CoT中不同步骤的重要性,可能导致关键推理信息的丢失。
核心思路:论文的核心思路是通过结构化的剪枝,选择性地移除Long-CoT中冗余或低效的推理步骤,从而使SLM能够更好地学习和利用CoT中的关键信息。这种剪枝不是盲目的缩短CoT,而是基于对CoT逻辑结构的理解,保留对最终答案贡献最大的部分。
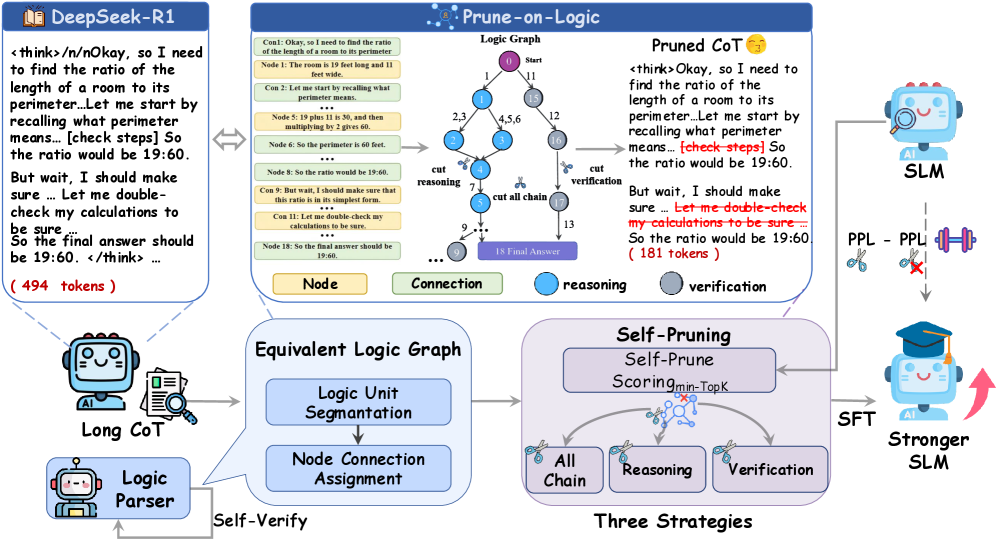
技术框架:Prune-on-Logic框架包含以下主要步骤:1) 将Long-CoT转化为逻辑图,节点表示推理步骤,边表示步骤之间的逻辑关系。2) 定义三种剪枝策略:链式剪枝(移除整个推理链)、核心推理剪枝(移除核心推理步骤)和验证剪枝(移除验证步骤)。3) 使用自验证约束来评估每个推理步骤的效用,并根据剪枝策略选择性地移除低效步骤。4) 使用剪枝后的CoT数据训练SLM。
关键创新:论文的关键创新在于提出了结构感知的剪枝方法,即Prune-on-Logic框架。与以往的CoT压缩方法不同,该框架不是简单地缩短CoT的长度,而是通过分析CoT的逻辑结构,选择性地移除冗余或低效的推理步骤。此外,论文还提出了基于自验证约束的推理步骤效用评估方法,能够更准确地判断哪些步骤对最终答案的贡献较小。
关键设计:论文中,逻辑图的构建方式、自验证约束的具体实现以及三种剪枝策略的细节是关键设计。自验证约束可能涉及到对模型输出的置信度评估,以及对不同推理步骤之间一致性的判断。三种剪枝策略的具体实现方式(例如,如何确定核心推理步骤,如何评估验证步骤的效用)也会影响最终的剪枝效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,验证剪枝策略能够持续提升SLM的准确率并减少token使用。例如,在某些任务上,验证剪枝可以将准确率提高几个百分点,同时减少10%-20%的token使用。此外,实验还发现,更大的模型由于其推理过程更冗余,因此从剪枝中获益更多。这些结果表明,Prune-on-Logic框架能够有效地提升Long-CoT在小模型上的推理能力。
🎯 应用场景
该研究成果可应用于各种需要小型语言模型进行复杂推理的场景,例如移动设备上的智能助手、资源受限的边缘计算设备等。通过剪枝优化Long-CoT,可以使SLM在保持较高推理准确率的同时,降低计算成本和内存占用,从而实现更高效的部署和应用。未来,该方法还可以扩展到其他类型的推理任务和模型。
📄 摘要(原文)
Long chain-of-thought (Long-CoT) reasoning improves accuracy in LLMs, yet its verbose, self-reflective style often hinders effective distillation into small language models (SLMs). We revisit Long-CoT compression through the lens of capability alignment and ask: Can pruning improve reasoning? We propose Prune-on-Logic, a structure-aware framework that transforms Long-CoT into logic graphs and selectively prunes low-utility reasoning steps under self-verification constraints. Through systematic analysis across three pruning strategies targeting entire chains, core reasoning, and verification, we find that verification pruning consistently improves accuracy while reducing token usage, whereas pruning reasoning steps or indiscriminate pruning degrades performance. Our study reveals that effective pruning aligns supervision with model capacity rather than merely shortening inputs. Gains hold across tasks, model scales, and CoT capability, with larger models benefiting more from pruning due to richer but more redundant reasoning. Our empirical findings highlight pruning as a structural optimization strategy for aligning CoT reasoning with SLM capacity.