Breaking Bad Tokens: Detoxification of LLMs Using Sparse Autoencoders
作者: Agam Goyal, Vedant Rathi, William Yeh, Yian Wang, Yuen Chen, Hari Sundaram
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-10-23)
备注: EMNLP 2025
💡 一句话要点
利用稀疏自编码器进行LLM解毒:打破不良Token
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 解毒 稀疏自编码器 激活控制 因果干预
📋 核心要点
- 现有LLM解毒方法通常采用表面修复,易受越狱攻击,无法有效应对深层毒性问题。
- 利用稀疏自编码器识别LLM残差流中的毒性相关方向,通过激活控制进行有针对性的干预。
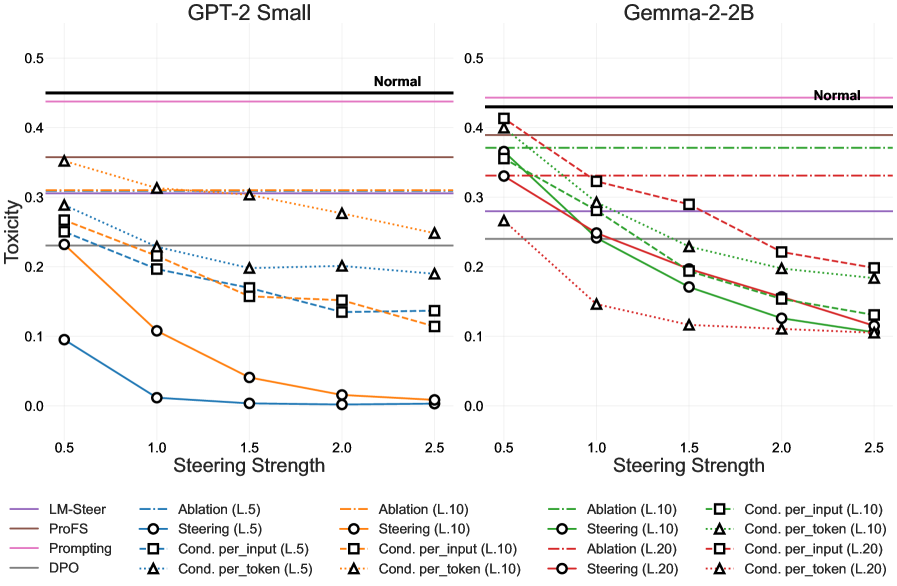
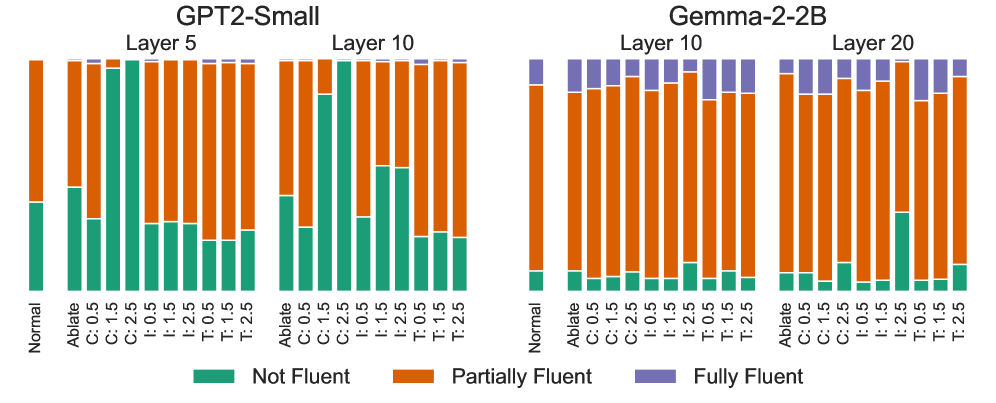
- 实验表明,该方法在降低毒性方面优于基线,同时保持了模型的知识和通用能力。
📝 摘要(中文)
大型语言模型(LLMs)已广泛应用于面向用户的应用程序中,但它们仍然会生成不良的有毒输出,包括亵渎、粗俗和贬损性言论。虽然存在许多解毒方法,但大多数方法都应用了广泛的、表面层次的修复,因此很容易被越狱攻击规避。本文利用稀疏自编码器(SAEs)来识别模型残差流中与毒性相关的方向,并使用相应的解码器向量执行有针对性的激活控制。我们引入了三个级别的控制强度,并在GPT-2 Small和Gemma-2-2B上评估它们,揭示了毒性降低和语言流畅性之间的权衡。在更强的控制强度下,这些因果干预在降低毒性方面超过了竞争基线高达20%,尽管在GPT-2 Small上,流畅性可能会根据强度而明显降低。关键的是,控制后的标准NLP基准分数保持稳定,表明模型的知识和一般能力得以保留。我们进一步表明,更宽的SAE中的特征分裂会阻碍安全干预,突显了解开纠缠的特征学习的重要性。我们的研究结果突出了基于SAE的因果干预在LLM解毒方面的希望和当前局限性,并进一步提出了更安全地部署语言模型的实用指南。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)生成有毒输出的问题,包括不当言论、粗俗语言和歧视性评论。现有解毒方法通常采用表面修复,容易被对抗性攻击绕过,无法从根本上解决LLM中的毒性问题。
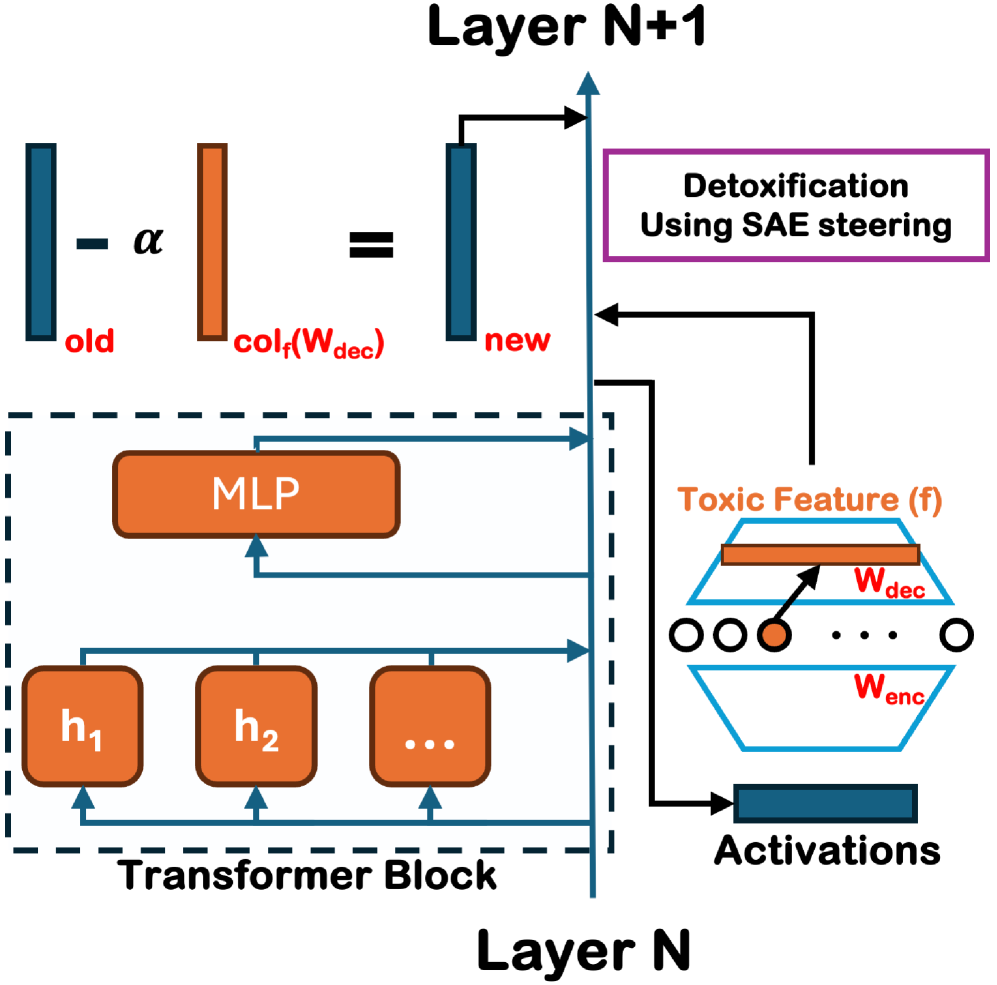
核心思路:论文的核心思路是利用稀疏自编码器(SAEs)来识别LLM内部表示(残差流)中与毒性相关的特定方向。通过对这些方向进行有针对性的激活控制,可以减少模型生成有毒内容的可能性,同时尽量保持模型的语言能力和知识。
技术框架:该方法主要包含以下几个阶段:1) 使用LLM生成文本;2) 使用SAE分析LLM的残差流,提取与毒性相关的特征;3) 根据SAE的输出,对LLM的激活进行控制,降低毒性特征的激活强度;4) 评估控制后的LLM的毒性和语言能力。整体流程是通过SAE来理解LLM的内部表示,并利用这些理解来指导LLM的生成过程,从而实现解毒。
关键创新:该方法的关键创新在于使用SAE来识别LLM内部的毒性相关方向,并进行有针对性的干预。与传统的解毒方法相比,该方法更加精细化,可以避免对模型整体性能产生过大的影响。此外,论文还研究了SAE的宽度对解毒效果的影响,发现特征分裂会阻碍安全干预。
关键设计:论文设计了三个级别的控制强度,以平衡毒性降低和语言流畅性之间的权衡。实验中使用了GPT-2 Small和Gemma-2-2B作为LLM,并使用标准NLP基准来评估模型的性能。SAE的训练目标是稀疏表示,以鼓励特征解耦。论文还分析了特征分裂对解毒效果的影响,并提出了避免特征分裂的建议。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在更强的控制强度下,该方法在降低毒性方面超过了竞争基线高达20%。同时,标准NLP基准分数保持稳定,表明模型的知识和一般能力得以保留。研究还发现,SAE的特征分裂会阻碍安全干预,突显了解开纠缠的特征学习的重要性。
🎯 应用场景
该研究成果可应用于各种需要使用LLM的场景,例如聊天机器人、内容生成平台和在线客服系统。通过降低LLM生成有毒内容的可能性,可以提高用户体验,减少潜在的法律风险,并促进更安全、更负责任的AI应用。
📄 摘要(原文)
Large language models (LLMs) are now ubiquitous in user-facing applications, yet they still generate undesirable toxic outputs, including profanity, vulgarity, and derogatory remarks. Although numerous detoxification methods exist, most apply broad, surface-level fixes and can therefore easily be circumvented by jailbreak attacks. In this paper we leverage sparse autoencoders (SAEs) to identify toxicity-related directions in the residual stream of models and perform targeted activation steering using the corresponding decoder vectors. We introduce three tiers of steering aggressiveness and evaluate them on GPT-2 Small and Gemma-2-2B, revealing trade-offs between toxicity reduction and language fluency. At stronger steering strengths, these causal interventions surpass competitive baselines in reducing toxicity by up to 20%, though fluency can degrade noticeably on GPT-2 Small depending on the aggressiveness. Crucially, standard NLP benchmark scores upon steering remain stable, indicating that the model's knowledge and general abilities are preserved. We further show that feature-splitting in wider SAEs hampers safety interventions, underscoring the importance of disentangled feature learning. Our findings highlight both the promise and the current limitations of SAE-based causal interventions for LLM detoxification, further suggesting practical guidelines for safer language-model deployment.