Internal Chain-of-Thought: Empirical Evidence for Layer-wise Subtask Scheduling in LLMs
作者: Zhipeng Yang, Junzhuo Li, Siyu Xia, Xuming Hu
分类: cs.CL, cs.LG
发布日期: 2025-05-20 (更新: 2025-09-28)
备注: EMNLP 2025 Main
💡 一句话要点
揭示LLM内部思维链:层级化子任务调度机制的实证研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链 子任务调度 层级化学习 模型透明度
📋 核心要点
- 现有方法缺乏对LLM内部运作机制的深入理解,难以解释其完成复杂任务的过程。
- 论文提出LLM存在内部思维链,通过层级化的方式分解和执行复合任务,实现逐步推理。
- 实验结果表明,LLM的不同层学习不同的子任务,并按顺序执行,提升了模型透明度。
📝 摘要(中文)
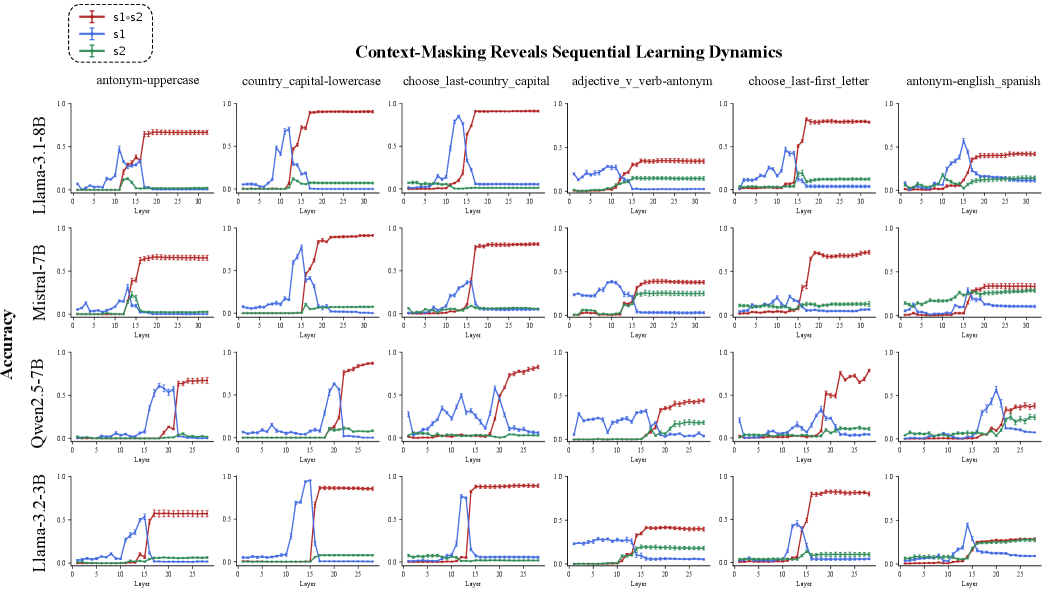
本文揭示了大型语言模型(LLM)表现出一种“内部思维链”:它们逐层地顺序分解和执行复合任务。我们的研究基于两个论点:(i)不同的子任务在网络的不同深度被学习;(ii)这些子任务跨层顺序执行。在一个包含15个两步复合任务的基准测试中,我们采用来自上下文的层掩码,并提出了一种新颖的跨任务修补方法,证实了(i)。为了检验论点(ii),我们应用LogitLens来解码隐藏状态,揭示了一致的层级执行模式。我们进一步在真实世界的TRACE基准上复制了我们的分析,观察到相同的逐步动态。总之,我们的结果通过展示LLM内部规划和执行子任务(或指令)的能力,增强了LLM的透明度,为细粒度的指令级激活控制开辟了道路。
🔬 方法详解
问题定义:现有的大型语言模型在处理复杂任务时,其内部运作机制如同一个黑盒,难以理解模型是如何将一个复杂的任务分解成多个子任务,并最终完成任务的。现有的方法缺乏对模型内部子任务调度和执行过程的细粒度分析,阻碍了对模型行为的深入理解和控制。
核心思路:本文的核心思路是揭示LLM内部存在一个“思维链”,这个思维链以层级化的方式组织和执行子任务。具体来说,模型在不同的网络层学习不同的子任务,并且这些子任务按照一定的顺序跨层执行。通过分析每一层网络的行为,可以理解模型是如何逐步完成复杂任务的。
技术框架:本文的研究框架主要包括以下几个步骤:首先,构建一个包含多个两步复合任务的基准测试集。然后,采用层掩码技术和跨任务修补方法,验证不同的子任务在网络的不同深度被学习。接着,使用LogitLens技术解码隐藏状态,分析子任务的执行顺序。最后,在真实世界的TRACE基准上验证研究结果的泛化性。
关键创新:本文最重要的技术创新点在于提出了“内部思维链”的概念,并提供了实证证据支持这一观点。与以往将LLM视为黑盒的方法不同,本文尝试打开这个黑盒,揭示模型内部的子任务调度和执行机制。此外,本文提出的跨任务修补方法和LogitLens分析方法为研究LLM的内部运作提供了新的工具。
关键设计:在实验设计方面,本文精心选择了包含15个两步复合任务的基准测试集,这些任务涵盖了不同的领域和难度,能够全面评估LLM的子任务处理能力。在层掩码技术方面,本文通过屏蔽不同层的上下文信息,观察模型性能的变化,从而推断该层所负责的子任务。在LogitLens分析方面,本文通过解码隐藏状态,分析每一层网络的输出概率分布,从而推断子任务的执行顺序。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在不同的网络层学习不同的子任务,并且这些子任务按照一定的顺序跨层执行。在TRACE基准测试中,观察到与两步复合任务基准测试中相似的逐步动态。这些结果为LLM的内部思维链提供了有力的实证支持。
🎯 应用场景
该研究成果可应用于提升LLM的透明度和可控性,例如,通过理解模型内部的子任务调度机制,可以对模型的行为进行干预和引导,从而提高模型的性能和可靠性。此外,该研究还可以为开发更高效的LLM架构提供新的思路,例如,可以设计专门的网络层来处理特定的子任务。
📄 摘要(原文)
We show that large language models (LLMs) exhibit an $\textit{internal chain-of-thought}$: they sequentially decompose and execute composite tasks layer-by-layer. Two claims ground our study: (i) distinct subtasks are learned at different network depths, and (ii) these subtasks are executed sequentially across layers. On a benchmark of 15 two-step composite tasks, we employ layer-from context-masking and propose a novel cross-task patching method, confirming (i). To examine claim (ii), we apply LogitLens to decode hidden states, revealing a consistent layerwise execution pattern. We further replicate our analysis on the real-world $\text{TRACE}$ benchmark, observing the same stepwise dynamics. Together, our results enhance LLMs transparency by showing their capacity to internally plan and execute subtasks (or instructions), opening avenues for fine-grained, instruction-level activation steering.