Creative Preference Optimization
作者: Mete Ismayilzada, Antonio Laverghetta, Simone A. Luchini, Reet Patel, Antoine Bosselut, Lonneke van der Plas, Roger Beaty
分类: cs.CL, cs.AI
发布日期: 2025-05-20 (更新: 2025-09-19)
备注: Accepted to EMNLP 2025 Findings
💡 一句话要点
提出创造性偏好优化(CrPO),提升大语言模型生成内容的新颖性、多样性和质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 创造性偏好优化 大型语言模型 创造力评估 偏好优化 自然语言生成
📋 核心要点
- 现有方法在提升LLM创造力方面存在局限,通常只关注多样性或特定任务,缺乏通用性。
- CrPO通过模块化地将多个创造力维度的信号融入偏好优化目标,从而提升LLM的创造力。
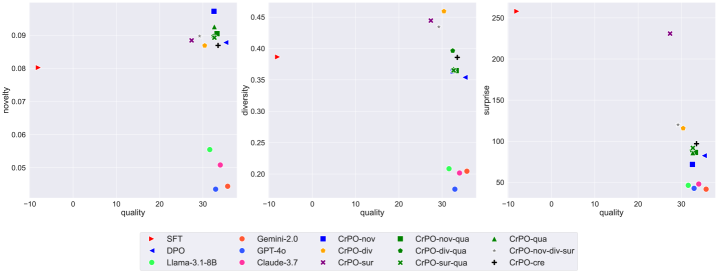
- 实验表明,CrPO模型在生成内容的新颖性、多样性和惊喜性方面优于GPT-4o等基线模型,同时保持高质量。
📝 摘要(中文)
大型语言模型(LLM)在自然语言生成任务中表现出色,但生成真正具有创造性的内容(以新颖性、多样性、惊喜性和高质量为特征)的能力仍然有限。现有的增强LLM创造力的方法通常狭隘地关注多样性或特定任务,未能以一种可推广的方式解决创造力的多方面性质。本文提出了创造性偏好优化(CrPO),这是一种新颖的对齐方法,以模块化的方式将来自多个创造力维度的信号注入到偏好优化目标中。我们使用CrPO和MuCE(一个新的大规模人类偏好数据集,包含超过20万条人类生成的回复和来自30多个心理创造力评估的评分)训练和评估了多个模型的创造力增强版本。在自动和人工评估中,我们的模型优于包括GPT-4o在内的强大基线,生成了更具新颖性、多样性和惊喜性的内容,同时保持了较高的输出质量。在NoveltyBench上的额外评估进一步证实了我们方法的通用性。总之,我们的结果表明,在偏好框架内直接优化创造力是提高LLM创造能力的一个有希望的方向,且不会影响输出质量。
🔬 方法详解
问题定义:现有的大型语言模型在生成创造性内容时面临挑战,它们往往难以产生真正新颖、多样、令人惊喜且高质量的文本。现有的方法通常只关注创造力的某一个方面,例如多样性,或者只针对特定的任务进行优化,缺乏一种通用的、能够提升LLM整体创造力的方法。
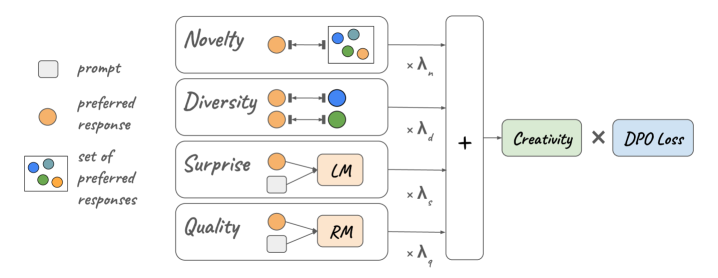
核心思路:CrPO的核心思路是通过偏好优化来直接提升LLM的创造力。具体来说,它将多个创造力维度(例如新颖性、多样性、惊喜性)的信号融入到偏好优化目标中,使得模型在训练过程中能够学习到如何生成更具创造性的内容。这种方法的核心在于,它将创造力视为一个多维度的概念,并通过优化模型在这些维度上的表现来提升其整体创造力。
技术框架:CrPO的整体框架包括以下几个主要步骤:1) 数据收集:使用MuCE数据集,该数据集包含大量人类生成的回复以及来自多个心理创造力评估的评分。2) 偏好建模:使用收集到的数据训练一个偏好模型,该模型能够预测人类对不同生成内容的偏好程度。3) 创造力信号注入:将来自多个创造力维度的信号(例如新颖性、多样性、惊喜性)注入到偏好优化目标中。4) 模型训练:使用偏好优化算法(例如PPO)来训练LLM,使其能够生成更符合人类偏好且更具创造性的内容。
关键创新:CrPO的关键创新在于它提出了一种模块化的方法来将多个创造力维度的信号融入到偏好优化目标中。这种模块化的设计使得可以灵活地添加或删除不同的创造力维度,从而适应不同的任务和需求。此外,CrPO还使用了MuCE数据集,这是一个大规模的人类偏好数据集,包含了来自多个心理创造力评估的评分,为训练创造力增强的LLM提供了有力的数据支持。
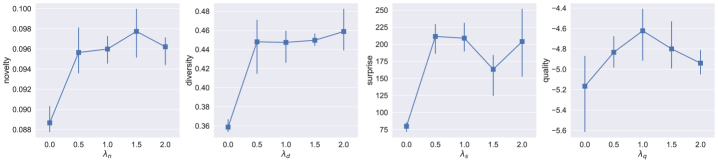
关键设计:CrPO的关键设计包括:1) 使用MuCE数据集进行训练,该数据集包含超过20万条人类生成的回复和来自30多个心理创造力评估的评分。2) 使用偏好优化算法(例如PPO)来训练LLM。3) 将创造力信号以模块化的方式注入到偏好优化目标中,允许灵活地调整不同创造力维度的权重。4) 使用多种自动和人工评估指标来评估模型的创造力,包括新颖性、多样性、惊喜性和质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用CrPO训练的模型在自动和人工评估中均优于包括GPT-4o在内的强大基线。具体来说,CrPO模型在生成内容的新颖性、多样性和惊喜性方面均有显著提升,同时保持了较高的输出质量。在NoveltyBench上的评估进一步证实了CrPO方法的通用性,表明其可以有效地提升LLM的创造力。
🎯 应用场景
CrPO具有广泛的应用前景,可用于提升LLM在创意写作、广告文案生成、艺术设计等领域的表现。通过优化LLM的创造力,可以生成更具吸引力、更具创新性的内容,从而提高生产效率和用户体验。未来,CrPO有望应用于更广泛的领域,例如科学发现、问题解决等,助力人类进行更具创造性的工作。
📄 摘要(原文)
While Large Language Models (LLMs) have demonstrated impressive performance across natural language generation tasks, their ability to generate truly creative content-characterized by novelty, diversity, surprise, and quality-remains limited. Existing methods for enhancing LLM creativity often focus narrowly on diversity or specific tasks, failing to address creativity's multifaceted nature in a generalizable way. In this work, we propose Creative Preference Optimization (CrPO), a novel alignment method that injects signals from multiple creativity dimensions into the preference optimization objective in a modular fashion. We train and evaluate creativity-augmented versions of several models using CrPO and MuCE, a new large-scale human preference dataset spanning over 200,000 human-generated responses and ratings from more than 30 psychological creativity assessments. Our models outperform strong baselines, including GPT-4o, on both automated and human evaluations, producing more novel, diverse, and surprising generations while maintaining high output quality. Additional evaluations on NoveltyBench further confirm the generalizability of our approach. Together, our results demonstrate that directly optimizing for creativity within preference frameworks is a promising direction for advancing the creative capabilities of LLMs without compromising output quality.