PersonaTAB: Predicting Personality Traits using Textual, Acoustic, and Behavioral Cues in Fully-Duplex Speech Dialogs
作者: Sho Inoue, Shai Wang, Haizhou Li
分类: cs.SD, cs.CL, eess.AS
发布日期: 2025-05-20
备注: This is accepted to Interspeech 2025; Added an extra page for supplementary figures; Project page: https://github.com/shinshoji01/Personality-Prediction-for-Conversation-Agents
💡 一句话要点
PersonaTAB:利用全双工语音对话中的文本、声学和行为线索预测人格特质
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人格预测 语音对话系统 自然语言处理 大型语言模型 情感分析
📋 核心要点
- 现有对话系统缺乏人格感知能力,主要原因是语音数据集缺少人格标注,限制了相关研究。
- 论文提出一个数据处理流水线,自动生成带有时间戳、响应类型和情感标签的对话数据集,为后续人格预测提供基础。
- 实验结果表明,该系统在人格预测方面与人类判断的对齐性优于现有方法,验证了方法的有效性。
📝 摘要(中文)
由于语音数据集中缺乏人格标注,具备人格感知能力的对话Agent(能够根据人格调整行为)的研究仍然不足。本文提出一个流水线,预处理原始录音,创建一个带有时间戳、响应类型以及情感/情绪标签的对话数据集。我们采用自动语音识别(ASR)系统提取文本和时间戳,然后生成对话级别的标注。利用这些标注,我们设计了一个系统,该系统使用大型语言模型来预测对话人格。我们聘请人工评估员来识别对话特征并分配人格标签。我们的分析表明,与现有方法相比,所提出的系统与人类判断的对齐性更强。
🔬 方法详解
问题定义:现有对话系统无法根据对话参与者的人格进行自适应调整,缺乏个性化交互能力。主要痛点在于缺乏带有高质量人格标注的大规模语音对话数据集,阻碍了相关模型的训练和评估。
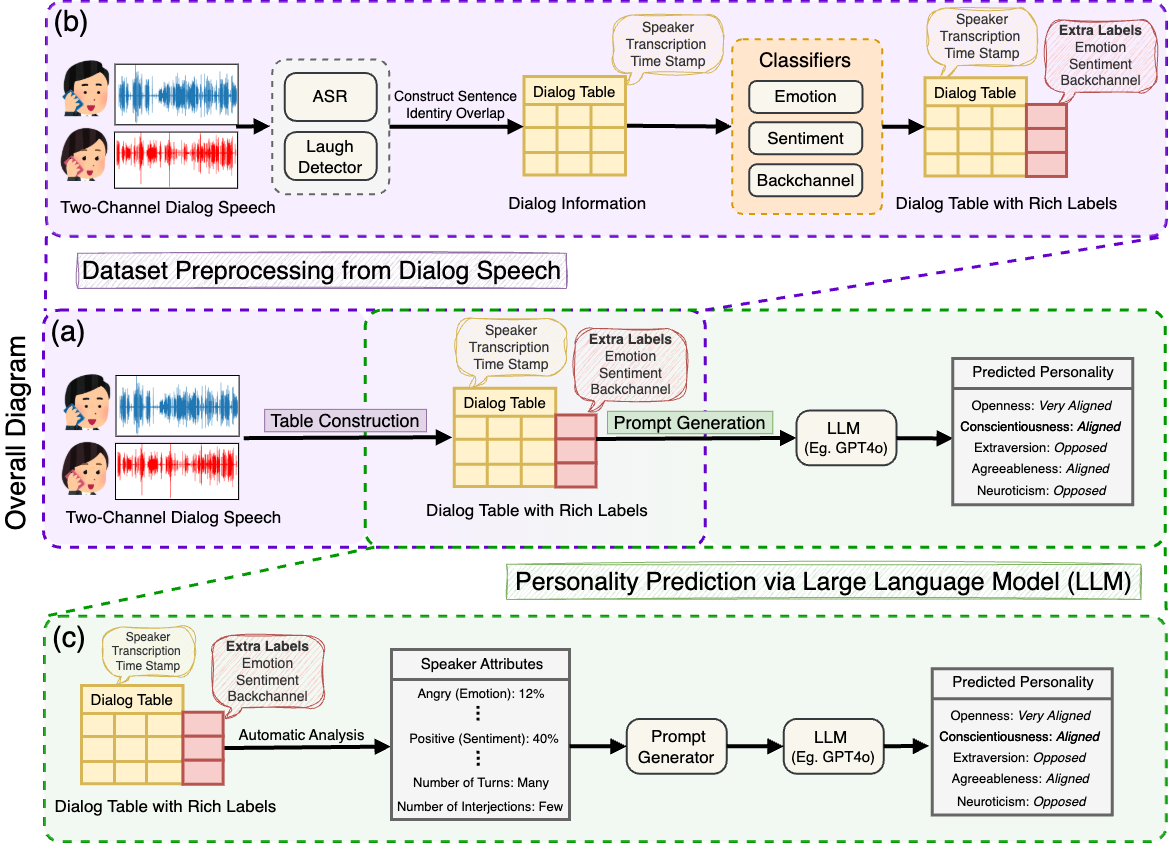
核心思路:论文的核心思路是构建一个自动化的数据处理流水线,从原始语音数据中提取文本、声学和行为特征,并利用大型语言模型进行人格预测。通过引入时间戳、响应类型和情感标签等信息,增强模型对对话上下文的理解能力。
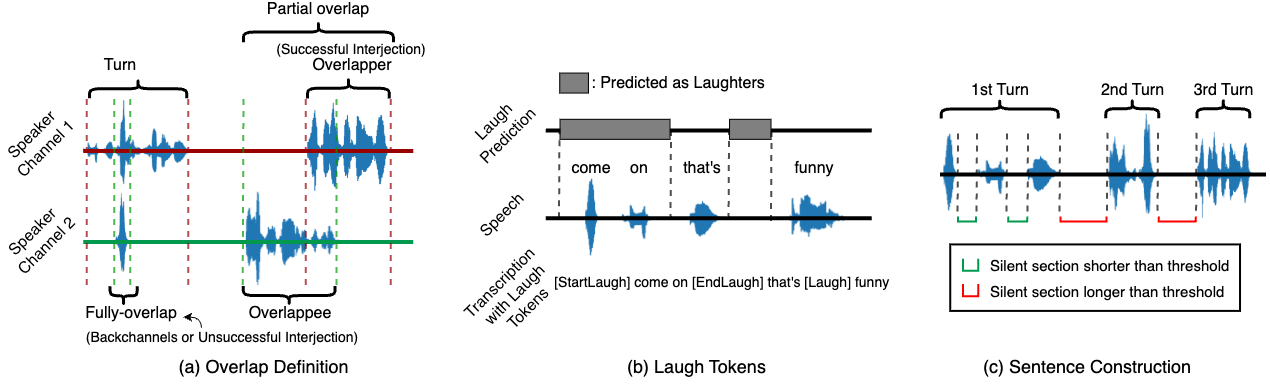
技术框架:整体框架包含以下几个主要模块:1) 数据预处理:对原始音频进行清洗和分割;2) 自动语音识别(ASR):将音频转换为文本,并提取时间戳信息;3) 对话标注:自动生成响应类型和情感/情绪标签;4) 人格预测:利用大型语言模型,结合文本、声学和行为特征,预测对话参与者的人格;5) 人工评估:聘请人工评估员对预测结果进行评估,验证模型的有效性。
关键创新:该论文的关键创新在于提出了一个端到端的自动化流程,能够从原始语音数据中生成带有高质量人格标注的对话数据集。此外,该方法结合了文本、声学和行为特征,并利用大型语言模型进行人格预测,提高了预测的准确性。
关键设计:论文中使用了自动语音识别(ASR)系统进行文本转录,具体使用的ASR模型类型未知。在人格预测阶段,使用了大型语言模型,具体模型架构和训练细节未知。人工评估阶段,评估员的数量和评估标准未知。损失函数和网络结构等技术细节在论文中没有详细描述。
🖼️ 关键图片
📊 实验亮点
论文通过人工评估验证了所提出系统的有效性。实验结果表明,该系统在人格预测方面与人类判断的对齐性优于现有方法。具体的性能数据和对比基线在摘要中没有给出,详细的实验结果需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于开发更具个性化和情感化的对话Agent,例如智能客服、虚拟助手和社交机器人。通过理解用户的人格特质,Agent可以提供更贴合用户需求的个性化服务,提升用户体验。未来,该技术还可以应用于心理健康咨询、招聘面试等领域。
📄 摘要(原文)
Despite significant progress in neural spoken dialog systems, personality-aware conversation agents -- capable of adapting behavior based on personalities -- remain underexplored due to the absence of personality annotations in speech datasets. We propose a pipeline that preprocesses raw audio recordings to create a dialogue dataset annotated with timestamps, response types, and emotion/sentiment labels. We employ an automatic speech recognition (ASR) system to extract transcripts and timestamps, then generate conversation-level annotations. Leveraging these annotations, we design a system that employs large language models to predict conversational personality. Human evaluators were engaged to identify conversational characteristics and assign personality labels. Our analysis demonstrates that the proposed system achieves stronger alignment with human judgments compared to existing approaches.