Think-J: Learning to Think for Generative LLM-as-a-Judge
作者: Hui Huang, Yancheng He, Hongli Zhou, Rui Zhang, Wei Liu, Weixun Wang, Jiaheng Liu, Wenbo Su
分类: cs.CL, cs.AI
发布日期: 2025-05-20 (更新: 2026-01-10)
备注: Accepted by AAAI2026
💡 一句话要点
Think-J:通过学习思考提升生成式LLM作为评判者的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估 强化学习 奖励建模 生成式模型 判断思考 离线强化学习 在线强化学习 LLM-as-a-Judge
📋 核心要点
- 现有LLM作为评判者的能力不足,无法准确评估生成式LLM的输出质量,限制了LLM的有效评估和奖励建模。
- Think-J通过让LLM学习“思考”过程,模拟人类评判的思维方式,从而提升其作为评判者的能力。
- 实验表明,Think-J显著提升了LLM评判能力,优于现有生成式和分类器方法,且无需额外人工标注。
📝 摘要(中文)
LLM-as-a-Judge指的是对大型语言模型(LLM)生成的响应进行自动偏好建模,这对于LLM评估和奖励建模都具有重要意义。尽管生成式LLM在各种任务中取得了显著进展,但它们作为LLM-Judge的性能仍然未达到预期。本文提出了Think-J,通过学习如何思考来改进生成式LLM-as-a-Judge。首先,我们利用少量精心策划的数据来开发模型,使其具备初步的判断思考能力。随后,我们基于强化学习(RL)优化判断思考轨迹。我们提出了两种基于离线和在线RL的判断思考优化方法。离线方法需要训练一个评论模型来构建用于学习的正负样本。在线方法定义了基于规则的奖励作为优化的反馈。实验结果表明,我们的方法可以显著提高生成式LLM-Judge的评估能力,超越了生成式和基于分类器的LLM-Judge,且无需额外的人工标注。
🔬 方法详解
问题定义:论文旨在解决生成式LLM作为评判者时,其评估能力不足的问题。现有的LLM-Judge方法,无论是生成式还是分类器,都难以准确捕捉人类的偏好,导致评估结果与人类直觉不符。这限制了LLM的有效评估和奖励建模,阻碍了LLM的进一步发展。
核心思路:论文的核心思路是让LLM学习“思考”过程,模拟人类在进行判断时的思维方式。通过学习如何分析、推理和比较不同的选项,LLM可以更好地理解人类的偏好,从而做出更准确的判断。这种“学习思考”的过程是通过强化学习来实现的。
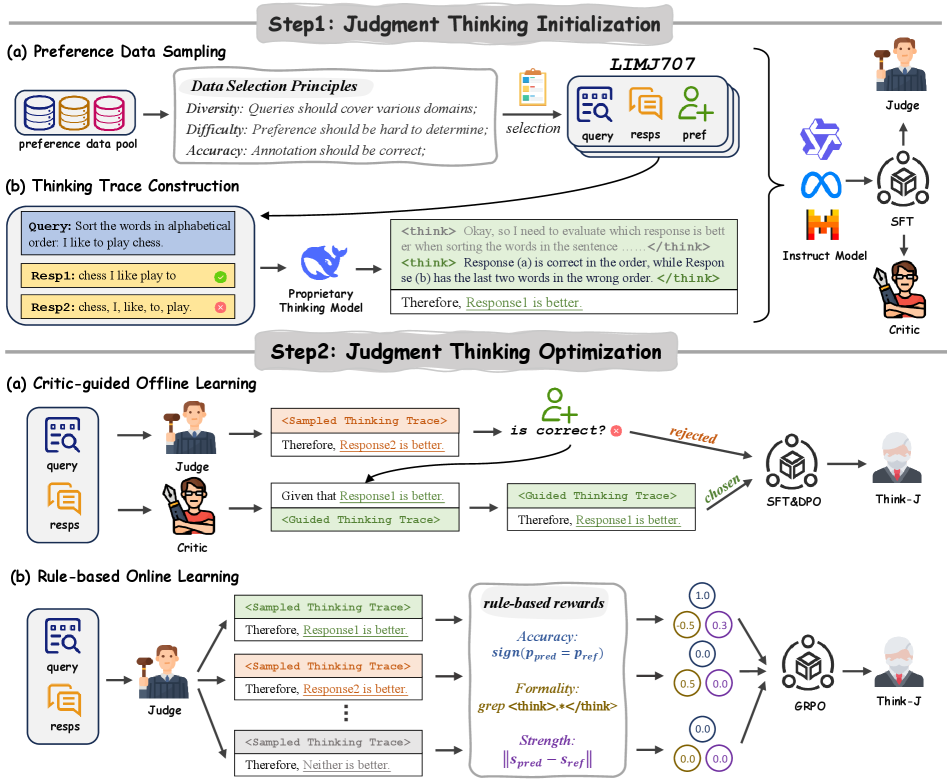
技术框架:Think-J的整体框架包括三个主要阶段:1) 初始判断思考能力构建:利用少量高质量的标注数据,训练LLM具备初步的判断思考能力。2) 判断思考轨迹优化(离线):训练一个评论模型(Critic Model),用于评估LLM的判断思考轨迹的质量。基于评论模型的评估结果,构建正负样本,用于进一步优化LLM的判断思考能力。3) 判断思考轨迹优化(在线):定义基于规则的奖励函数,作为强化学习的反馈信号,直接优化LLM的判断思考轨迹。
关键创新:最重要的创新点在于引入了“学习思考”的概念,将LLM-Judge的训练过程转化为一个学习如何进行有效判断思考的过程。与传统的直接预测或分类方法不同,Think-J更加注重模拟人类的思维过程,从而提升了LLM的判断能力。此外,论文还提出了两种不同的强化学习方法(离线和在线)来优化判断思考轨迹,为LLM-Judge的训练提供了更多的选择。
关键设计:在离线强化学习中,评论模型的设计至关重要,它需要能够准确评估判断思考轨迹的质量。在在线强化学习中,奖励函数的设计需要能够有效地引导LLM学习正确的判断思考方式。论文中具体使用的参数设置、损失函数和网络结构等技术细节在原文中有更详细的描述。
🖼️ 关键图片

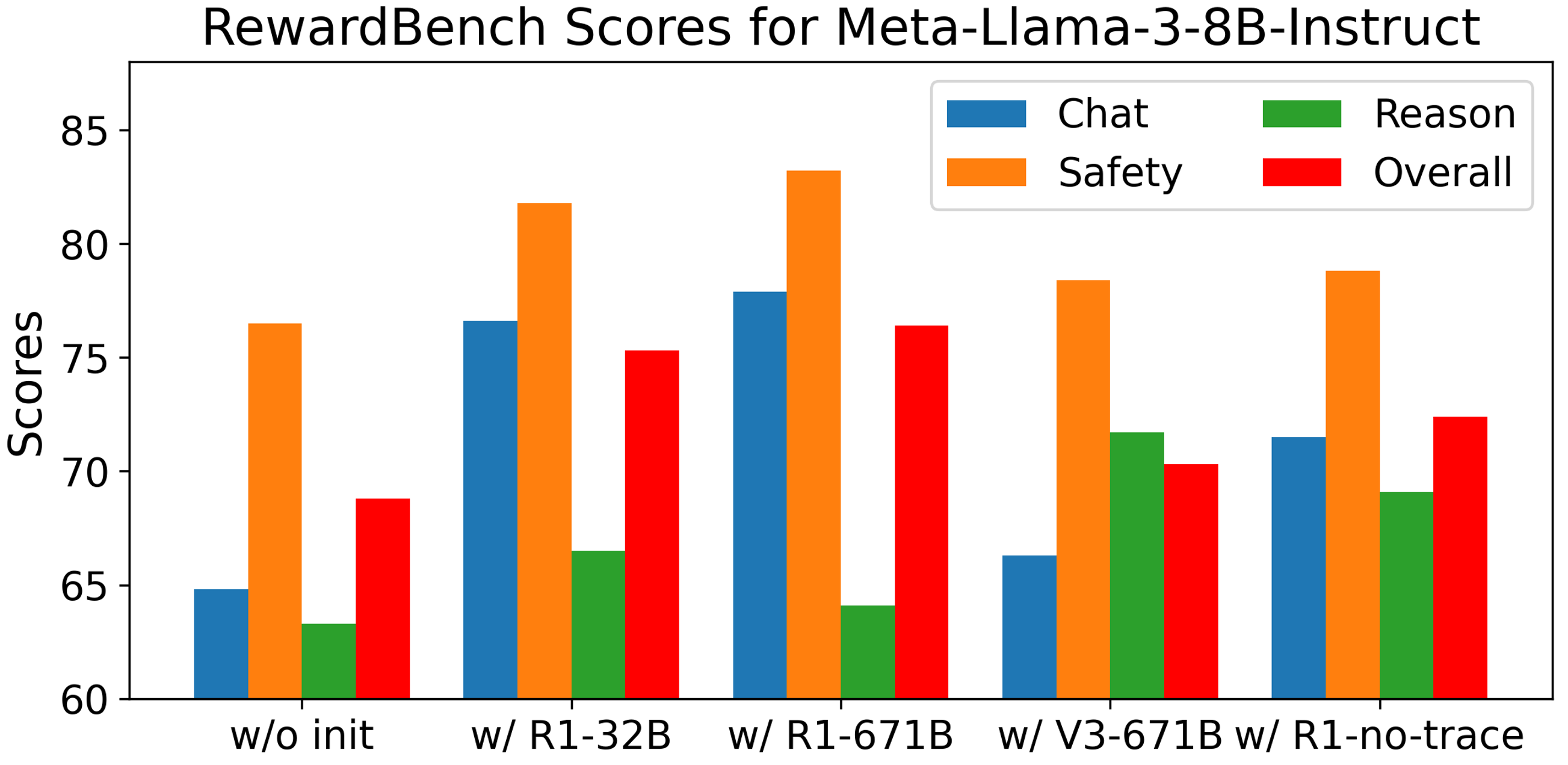
📊 实验亮点
实验结果表明,Think-J在LLM评估任务中取得了显著的性能提升,超越了现有的生成式和基于分类器的LLM-Judge方法。具体而言,Think-J在多个评估指标上都取得了最佳结果,并且无需额外的人工标注。这表明Think-J能够更准确地捕捉人类的偏好,从而做出更可靠的判断。
🎯 应用场景
Think-J具有广泛的应用前景,可用于自动评估LLM生成的文本质量,辅助LLM的训练和优化。此外,该方法还可以应用于其他需要进行判断和决策的场景,例如自动代码评审、医疗诊断辅助等。通过提升LLM的判断能力,Think-J有望推动人工智能在更多领域的应用。
📄 摘要(原文)
LLM-as-a-Judge refers to the automatic modeling of preferences for responses generated by Large Language Models (LLMs), which is of significant importance for both LLM evaluation and reward modeling. Although generative LLMs have made substantial progress in various tasks, their performance as LLM-Judge still falls short of expectations. In this work, we propose Think-J, which improves generative LLM-as-a-Judge by learning how to think. We first utilized a small amount of curated data to develop the model with initial judgment thinking capabilities. Subsequently, we optimize the judgment thinking traces based on reinforcement learning (RL). We propose two methods for judgment thinking optimization, based on offline and online RL, respectively. The offline method requires training a critic model to construct positive and negative examples for learning. The online method defines rule-based reward as feedback for optimization. Experimental results showed that our approach can significantly enhance the evaluation capability of generative LLM-Judge, surpassing both generative and classifier-based LLM-Judge without requiring extra human annotations.