MultiHal: Multilingual Dataset for Knowledge-Graph Grounded Evaluation of LLM Hallucinations
作者: Ernests Lavrinovics, Russa Biswas, Katja Hose, Johannes Bjerva
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-10-23)
💡 一句话要点
MultiHal:用于知识图谱 grounding 的 LLM 幻觉多语言评估数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识图谱 幻觉评估 多语言 事实性 KG-RAG 问答系统
📋 核心要点
- 现有LLM幻觉评估benchmark主要集中于英语数据集,忽略了结构化知识图谱(KG)的利用,限制了多语言环境下的事实性评估。
- MultiHal通过构建多语言、多跳的KG-based benchmark,旨在弥补现有benchmark在KG路径和多语言性方面的不足,促进LLM的事实性评估。
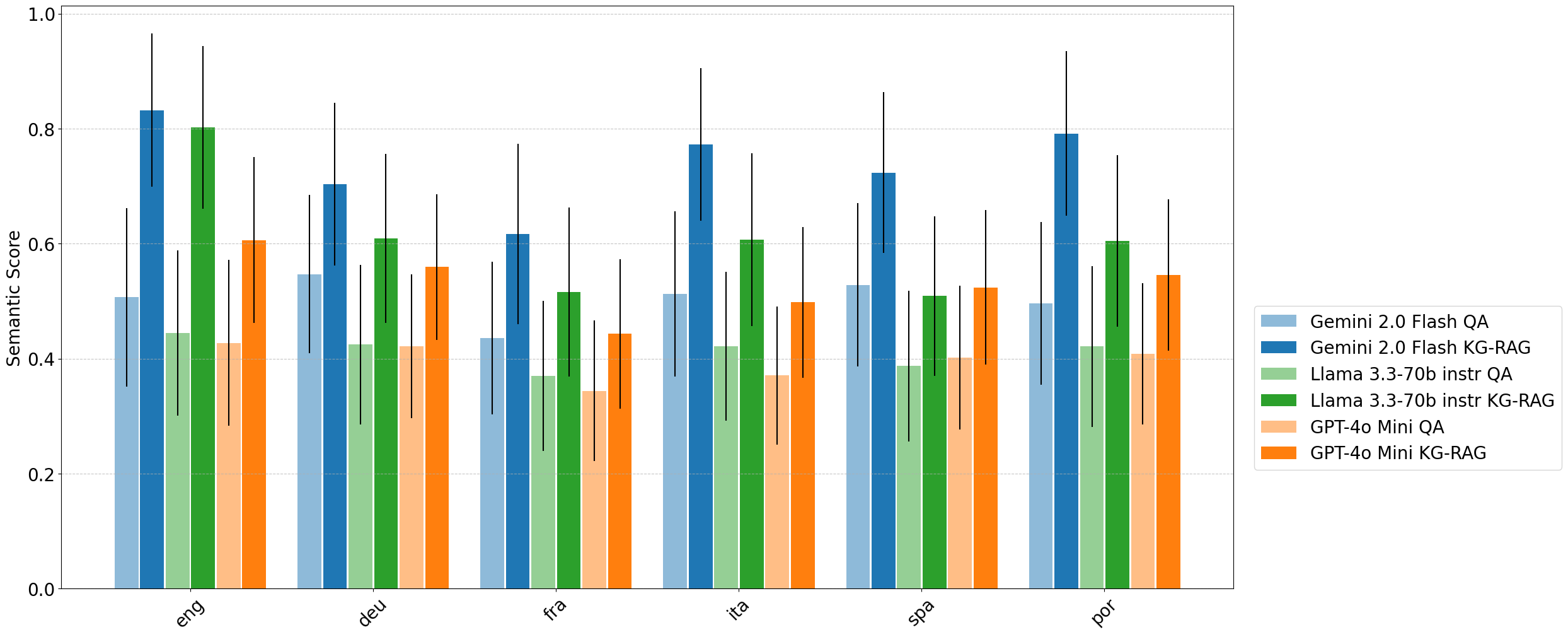
- 实验结果表明,在多种语言和模型中,基于MultiHal的KG-RAG方法在语义相似度、NLI推理和幻觉检测方面均优于传统QA方法。
📝 摘要(中文)
大型语言模型(LLMs)存在固有的忠实性和事实性限制,通常被称为幻觉。现有的基准测试主要集中在以英语为中心的数据集上,并依赖于网络链接或文本段落等补充信息性上下文,而忽略了可用的结构化事实资源,从而为事实性评估提供了一个测试平台。为此,知识图谱(KGs)已被认为是缓解幻觉的有用辅助手段,因为它们提供了一种结构化的方式来表示关于实体及其关系的 facts,且语言开销最小。我们弥补了现有幻觉评估基准中 KG 路径和多语言性的不足,并提出了一个基于 KG 的多语言、多跳基准测试,名为 MultiHal,用于生成文本评估。作为数据收集流程的一部分,我们从开放域 KG 中挖掘了 14 万条 KG 路径,从中修剪了噪声路径,整理出了一个高质量的 2.59 万条子集。我们的基线评估表明,在多种语言和多个模型中,KG-RAG 在语义相似度评分方面提高了约 0.12 到 0.36 个点,在 NLI 推理方面提高了 0.16 到 0.36 个点,在 KG-RAG 中幻觉检测方面提高了 0.29 到 0.42 个点,证明了 KG 集成的潜力。我们预计 MultiHal 将促进未来对基于图的幻觉缓解和事实核查任务的研究。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成文本时出现的“幻觉”问题,即生成不真实或与已知事实相悖的内容。现有评估方法主要集中在英语数据集,且忽略了结构化知识图谱(KG)的利用,导致无法有效评估LLMs在多语言环境下的事实性。
核心思路:论文的核心思路是利用知识图谱(KG)作为外部知识源,为LLMs提供结构化的事实信息,从而减少幻觉的产生。同时,构建一个多语言的评估基准,以更全面地评估LLMs在不同语言环境下的事实性。
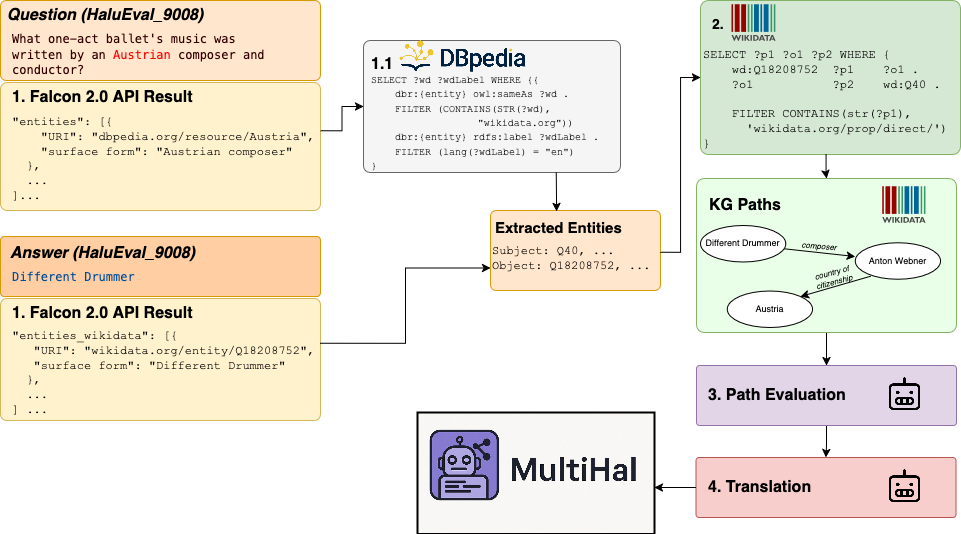
技术框架:MultiHal的数据构建流程包括:1) 从开放域KG中挖掘KG路径;2) 对KG路径进行清洗和过滤,去除噪声路径,保留高质量的KG路径;3) 基于KG路径构建多语言的问答对,作为评估数据。评估阶段,使用KG-RAG方法,将KG信息融入到LLM的生成过程中,并使用语义相似度、NLI推理和幻觉检测等指标评估生成文本的事实性。
关键创新:MultiHal的关键创新在于:1) 构建了一个多语言、多跳的KG-based幻觉评估基准,弥补了现有benchmark在多语言性和KG利用方面的不足;2) 提出了基于KG-RAG的幻觉缓解方法,通过将KG信息融入到LLM的生成过程中,提高了生成文本的事实性。
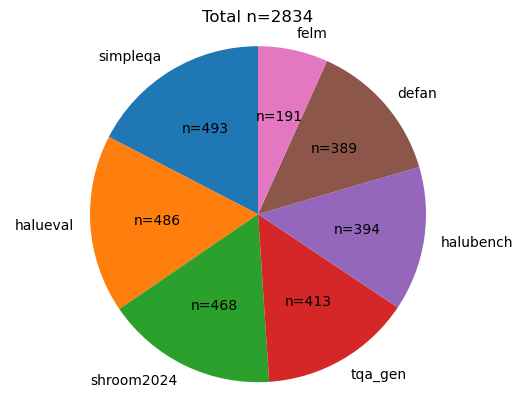
关键设计:数据收集方面,论文从开放域KG中挖掘了14万条KG路径,并通过一系列过滤规则,最终筛选出2.59万条高质量的KG路径。评估指标方面,论文采用了语义相似度、NLI推理和幻觉检测等多种指标,以全面评估生成文本的事实性。KG-RAG的具体实现细节未知,论文中没有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在多种语言和多个模型中,基于MultiHal的KG-RAG方法在语义相似度评分方面提高了约 0.12 到 0.36 个点,在 NLI 推理方面提高了 0.16 到 0.36 个点,在 KG-RAG 中幻觉检测方面提高了 0.29 到 0.42 个点。这些结果证明了KG集成在缓解LLM幻觉方面的有效性。
🎯 应用场景
该研究成果可应用于提升LLM在问答系统、对话系统、知识图谱补全等领域的性能。通过利用知识图谱减少LLM的幻觉,可以提高生成内容的可靠性和准确性,增强用户信任度。未来,该研究可进一步扩展到更多语言和领域,促进LLM在实际应用中的广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) have inherent limitations of faithfulness and factuality, commonly referred to as hallucinations. Several benchmarks have been developed that provide a test bed for factuality evaluation within the context of English-centric datasets, while relying on supplementary informative context like web links or text passages but ignoring the available structured factual resources. To this end, Knowledge Graphs (KGs) have been identified as a useful aid for hallucination mitigation, as they provide a structured way to represent the facts about entities and their relations with minimal linguistic overhead. We bridge the lack of KG paths and multilinguality for factual language modeling within the existing hallucination evaluation benchmarks and propose a KG-based multilingual, multihop benchmark called MultiHal framed for generative text evaluation. As part of our data collection pipeline, we mined 140k KG-paths from open-domain KGs, from which we pruned noisy KG-paths, curating a high-quality subset of 25.9k. Our baseline evaluation shows an absolute scale improvement by approximately 0.12 to 0.36 points for the semantic similarity score, 0.16 to 0.36 for NLI entailment and 0.29 to 0.42 for hallucination detection in KG-RAG over vanilla QA across multiple languages and multiple models, demonstrating the potential of KG integration. We anticipate MultiHal will foster future research towards several graph-based hallucination mitigation and fact-checking tasks.