DRP: Distilled Reasoning Pruning with Skill-aware Step Decomposition for Efficient Large Reasoning Models
作者: Yuxuan Jiang, Dawei Li, Frank Ferraro
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-08-22)
💡 一句话要点
提出DRP:一种基于技能感知步骤分解的推理蒸馏剪枝方法,用于提升大型推理模型的效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 推理蒸馏 模型剪枝 链式思考 数学推理
📋 核心要点
- 现有大型推理模型存在推理过程冗长、效率低下的问题,限制了其在资源受限场景下的应用。
- DRP通过教师模型进行技能感知的步骤分解和内容剪枝,然后将精简的推理路径蒸馏到学生模型中,实现高效推理。
- 实验表明,DRP在数学推理任务上显著提高了token效率,同时保持甚至提升了准确率,具有实际应用价值。
📝 摘要(中文)
大型推理模型(LRMs)通过长链式思考(CoT)推理在复杂推理任务中取得了成功,但其推理过程通常包含冗长的推理轨迹,导致效率低下。为了解决这个问题,我们提出了蒸馏推理剪枝(DRP),这是一个混合框架,结合了推理时剪枝和基于调优的蒸馏,这两种广泛使用的有效推理策略。DRP使用教师模型执行技能感知的步骤分解和内容剪枝,然后将剪枝后的推理路径提炼到学生模型中,使其能够高效且准确地进行推理。在几个具有挑战性的数学推理数据集上,我们发现使用DRP训练的模型在不牺牲准确性的前提下,在token效率方面取得了显著的提高。具体来说,DRP将GSM8K上的平均token使用量从917减少到328,同时将准确率从91.7%提高到94.1%,并在AIME上实现了43%的token减少,且没有性能下降。进一步的分析表明,将训练CoT的推理结构与学生的推理能力对齐,对于有效的知识转移和性能提升至关重要。
🔬 方法详解
问题定义:论文旨在解决大型推理模型在复杂推理任务中推理过程冗长、计算效率低下的问题。现有的链式思考(CoT)方法虽然提高了推理准确性,但同时也引入了大量的冗余信息,增加了计算成本和延迟,限制了其在实际应用中的部署。
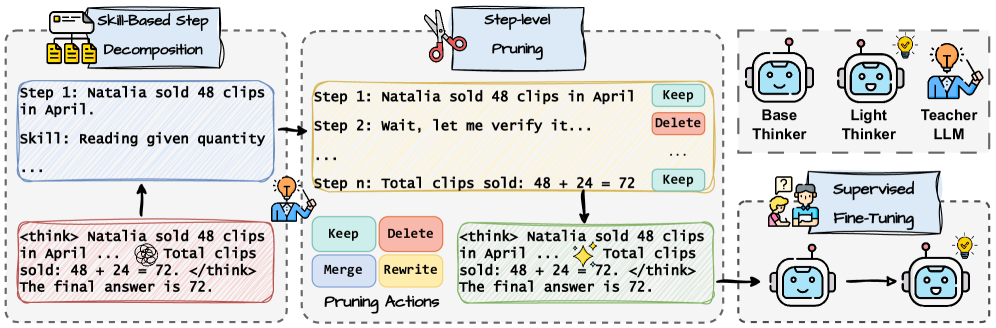
核心思路:论文的核心思路是结合推理时剪枝和基于调优的蒸馏,通过教师模型指导学生模型学习更精简、更有效的推理路径。具体来说,教师模型负责进行技能感知的步骤分解和内容剪枝,去除不必要的推理步骤,然后将剪枝后的推理路径作为目标,训练学生模型,使其能够模仿教师模型的精简推理过程。
技术框架:DRP框架包含两个主要阶段:1) 教师模型进行技能感知的步骤分解和内容剪枝;2) 学生模型通过蒸馏学习教师模型剪枝后的推理路径。教师模型首先将复杂的推理过程分解为一系列更小的、技能相关的步骤,然后根据每个步骤的重要性进行内容剪枝,去除冗余信息。学生模型则通过最小化与教师模型剪枝后推理路径的差异来学习精简的推理策略。
关键创新:DRP的关键创新在于技能感知的步骤分解和内容剪枝策略,以及将剪枝后的推理路径作为蒸馏目标。传统的蒸馏方法通常直接将教师模型的输出作为目标,而DRP则更加关注推理过程的结构和效率,通过剪枝去除冗余信息,从而提高学生模型的推理效率。
关键设计:论文中关键的设计包括:1) 如何定义和衡量推理步骤的技能相关性,以便进行有效的步骤分解;2) 如何设计内容剪枝策略,以去除冗余信息,同时保持推理的准确性;3) 如何选择合适的蒸馏损失函数,以确保学生模型能够有效地学习教师模型的精简推理路径。具体的损失函数和网络结构细节在论文中进行了详细描述,但摘要中未明确给出。
🖼️ 关键图片


📊 实验亮点
DRP在GSM8K数据集上将平均token使用量从917减少到328,同时将准确率从91.7%提高到94.1%。在AIME数据集上,DRP实现了43%的token减少,且没有性能下降。这些结果表明,DRP能够显著提高大型推理模型的效率,同时保持甚至提升其准确性。
🎯 应用场景
DRP具有广泛的应用前景,可用于优化各种需要复杂推理的大型语言模型,例如数学问题求解、代码生成、知识图谱推理等。通过提高推理效率,DRP可以降低计算成本,缩短响应时间,并使这些模型能够在资源受限的设备上运行,从而扩展其应用范围。
📄 摘要(原文)
While Large Reasoning Models (LRMs) have demonstrated success in complex reasoning tasks through long chain-of-thought (CoT) reasoning, their inference often involves excessively verbose reasoning traces, resulting in substantial inefficiency. To address this, we propose Distilled Reasoning Pruning (DRP), a hybrid framework that combines inference-time pruning with tuning-based distillation, two widely used strategies for efficient reasoning. DRP uses a teacher model to perform skill-aware step decomposition and content pruning, and then distills the pruned reasoning paths into a student model, enabling it to reason both efficiently and accurately. Across several challenging mathematical reasoning datasets, we find that models trained with DRP achieve substantial improvements in token efficiency without sacrificing accuracy. Specifically, DRP reduces average token usage on GSM8K from 917 to 328 while improving accuracy from 91.7% to 94.1%, and achieves a 43% token reduction on AIME with no performance drop. Further analysis shows that aligning the reasoning structure of training CoTs with the student's reasoning capacity is critical for effective knowledge transfer and performance gains.