Truth or Twist? Optimal Model Selection for Reliable Label Flipping Evaluation in LLM-based Counterfactuals
作者: Qianli Wang, Van Bach Nguyen, Nils Feldhus, Luis Felipe Villa-Arenas, Christin Seifert, Sebastian Möller, Vera Schmitt
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-08-27)
备注: Accepted at INLG 2025, camera-ready version
💡 一句话要点
针对LLM生成对抗样本,提出基于独立Judge模型进行可靠性评估的模型选择方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗数据增强 标签翻转 模型评估 Judge模型
📋 核心要点
- 现有基于LLM的对抗数据增强方法在评估对抗样本有效性时,Judge模型的选择缺乏一致性标准,导致评估结果不稳定。
- 论文提出通过分析生成模型和Judge模型之间的关系,寻找能够提供更可靠标签翻转评估的Judge模型选择策略。
- 实验结果表明,与生成模型独立的Judge模型能提供与用户研究更一致的评估结果,从而提升模型性能和鲁棒性。
📝 摘要(中文)
本文研究了使用大型语言模型(LLM)进行对抗数据增强(CDA)时,评估标签翻转(label flipping)有效性的Judge模型选择问题。通过定义生成模型和Judge模型之间的四种关系(相同模型、同族模型、独立模型、蒸馏关系),并结合两个先进的LLM方法、三个数据集、四个生成模型和十五个Judge模型的大量实验以及用户研究(n=90),证明了与生成模型具有独立、非微调关系的Judge模型能够提供最可靠的标签翻转评估。这种关系与CDA的用户研究结果高度一致,能够提升模型性能和鲁棒性。然而,最佳Judge模型与用户研究结果之间仍存在较大差距,表明完全自动化的CDA流程可能不足,需要人工干预。
🔬 方法详解
问题定义:论文旨在解决在基于LLM的对抗数据增强(CDA)中,如何选择合适的Judge模型来评估生成的对抗样本的有效性,即标签翻转(label flipping)的可靠性问题。现有方法在选择Judge模型时缺乏明确的标准,导致评估结果不稳定,影响CDA的效果。不同的Judge模型可能会对同一个对抗样本给出不同的判断,使得难以确定对抗样本是否真正有效。
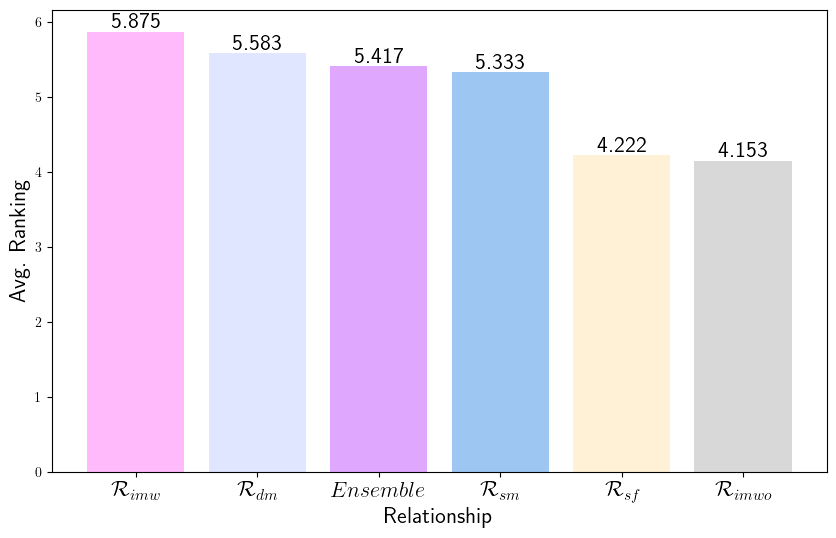
核心思路:论文的核心思路是分析生成对抗样本的生成模型与评估对抗样本的Judge模型之间的关系,并找出哪种关系能够提供最可靠的标签翻转评估。论文假设Judge模型与生成模型的关系会影响评估结果的可靠性,并提出四种关系类型:相同模型、同族模型、独立模型和蒸馏关系。通过实验验证,发现与生成模型独立的Judge模型能够提供与人工评估更一致的结果。
技术框架:论文的技术框架主要包括以下几个步骤:1) 定义生成模型和Judge模型之间的四种关系类型;2) 选择多个生成模型和Judge模型,以及多个数据集;3) 使用生成模型生成对抗样本;4) 使用不同的Judge模型评估对抗样本的标签翻转情况;5) 将Judge模型的评估结果与用户研究的结果进行比较,以确定哪种Judge模型能够提供最可靠的评估;6) 分析不同Judge模型对模型性能和鲁棒性的影响。
关键创新:论文的关键创新在于:1) 首次系统性地研究了Judge模型选择对LLM对抗样本评估的影响;2) 提出了生成模型和Judge模型之间的四种关系类型,为Judge模型的选择提供了理论基础;3) 通过大量的实验和用户研究,验证了与生成模型独立的Judge模型能够提供最可靠的评估结果。
关键设计:论文的关键设计包括:1) 选择了多种LLM作为生成模型和Judge模型,以保证实验结果的泛化性;2) 使用了多个数据集,以评估不同数据集上的效果;3) 采用了标签翻转作为评估对抗样本有效性的主要指标;4) 进行了用户研究,以验证Judge模型评估结果的可靠性。没有特别强调参数设置、损失函数或网络结构等技术细节,而是侧重于模型关系对评估结果的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与生成模型独立的Judge模型能够提供与用户研究结果最一致的标签翻转评估。使用这种Judge模型进行CDA可以显著提高模型的性能和鲁棒性。虽然最佳Judge模型与用户研究结果之间仍存在差距,但该研究为自动化CDA流程的改进提供了重要方向。
🎯 应用场景
该研究成果可应用于提升基于LLM的对抗数据增强技术的可靠性和有效性,从而提高LLM在各种自然语言处理任务中的性能和鲁棒性。例如,可以用于改进文本分类、情感分析、机器翻译等任务的模型训练,使其更能抵抗对抗攻击,并在真实场景中表现更稳定。此外,该研究也为构建更安全、更可靠的AI系统提供了理论指导。
📄 摘要(原文)
Counterfactual examples are widely employed to enhance the performance and robustness of large language models (LLMs) through counterfactual data augmentation (CDA). However, the selection of the judge model used to evaluate label flipping, the primary metric for assessing the validity of generated counterfactuals for CDA, yields inconsistent results. To decipher this, we define four types of relationships between the counterfactual generator and judge models: being the same model, belonging to the same model family, being independent models, and having an distillation relationship. Through extensive experiments involving two state-of-the-art LLM-based methods, three datasets, four generator models, and 15 judge models, complemented by a user study (n = 90), we demonstrate that judge models with an independent, non-fine-tuned relationship to the generator model provide the most reliable label flipping evaluations. Relationships between the generator and judge models, which are closely aligned with the user study for CDA, result in better model performance and robustness. Nevertheless, we find that the gap between the most effective judge models and the results obtained from the user study remains considerably large. This suggests that a fully automated pipeline for CDA may be inadequate and requires human intervention.