EEG-to-Text Translation: A Model for Deciphering Human Brain Activity
作者: Saydul Akbar Murad, Ashim Dahal, Nick Rahimi
分类: cs.CL, cs.AI
发布日期: 2025-05-20 (更新: 2025-12-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出R1 Translator模型,提升脑电信号到文本的解码性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑电信号 文本解码 LSTM Transformer 脑机接口
📋 核心要点
- 现有脑电信号到文本解码模型性能受限,无法充分捕捉脑电信号的复杂时序依赖关系,导致生成文本质量不高。
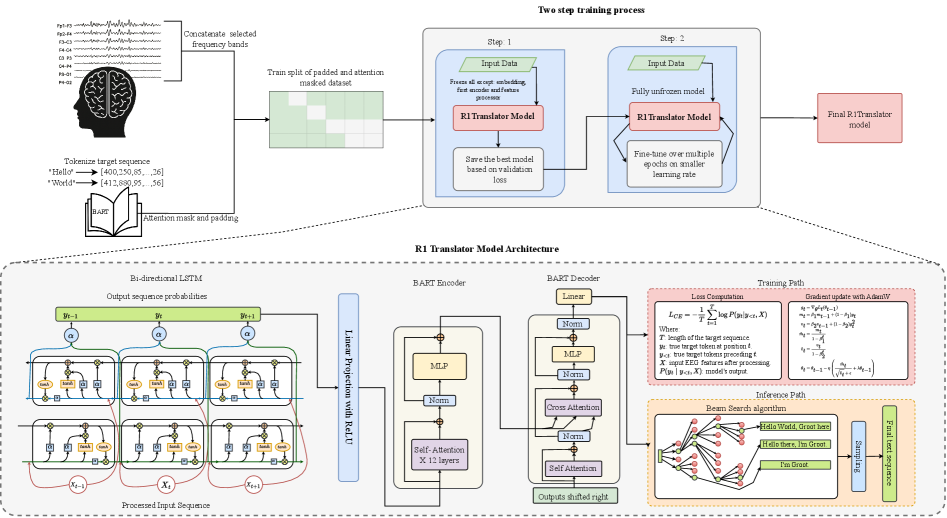
- 提出R1 Translator模型,结合双向LSTM编码器和预训练Transformer解码器,利用LSTM提取脑电信号的时序特征,再由Transformer生成文本。
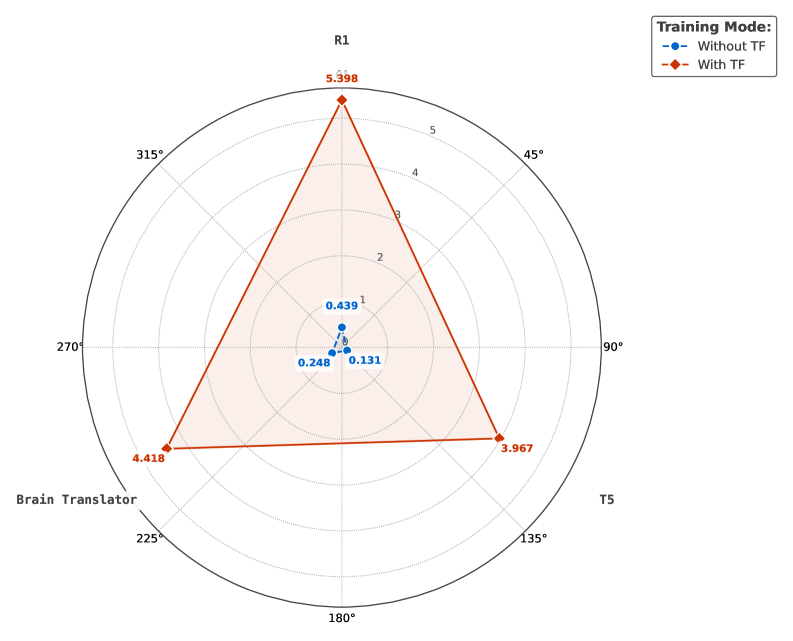
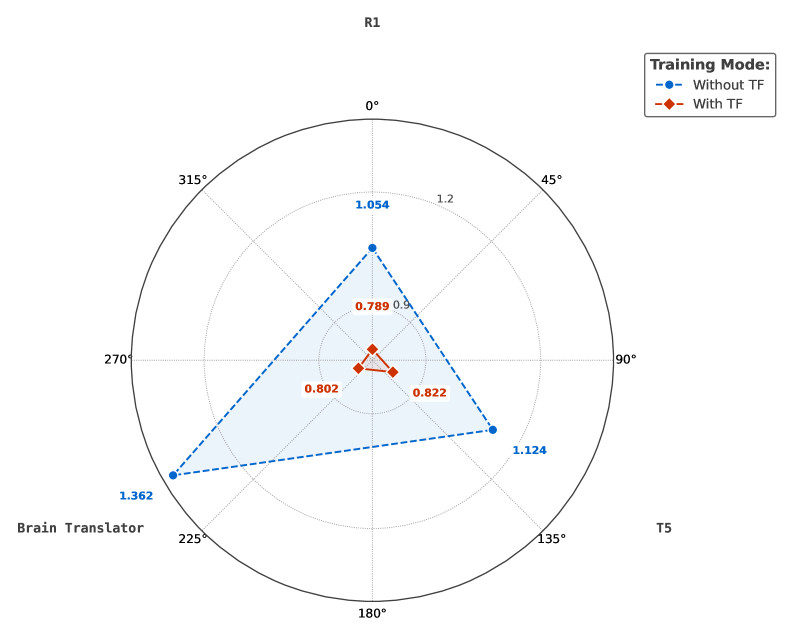
- 实验结果表明,R1 Translator在ROUGE-1、ROUGE-L、CER和WER等指标上均优于T5和Brain Translator,显著提升了解码性能。
📝 摘要(中文)
随着Gemini、GPT等大型语言模型的快速发展,弥合人脑与语言处理之间的差距已成为一个重要的研究领域。为了应对这一挑战,研究人员开发了各种模型来将脑电信号解码为文本。然而,这些模型仍然面临着显著的性能限制。为了克服这些缺点,我们提出了一种新的模型R1 Translator,旨在提高脑电信号到文本解码的性能。R1 Translator模型结合了双向LSTM编码器和预训练的基于Transformer的解码器,利用脑电特征来产生高质量的文本输出。该模型通过LSTM处理脑电嵌入以捕获序列依赖关系,然后将其馈送到Transformer解码器以进行有效的文本生成。R1 Translator在ROUGE指标上表现出色,优于T5和Brain Translator。具体而言,R1的ROUGE-1得分为38.00%(P),比T5(34.89%)高出9%,比Brain(35.69%)高出3%。它在ROUGE-L方面也处于领先地位,F1得分为32.51%,比T5高出3%(29.67%),比Brain高出2%(30.38%)。在CER方面,R1的CER为0.5795,比T5(0.5917)低2%,比Brain(0.6001)低4%。此外,R1在WER方面表现更好,得分为0.7280,比T5(0.7610)高出4.3%,比Brain(0.7553)高出3.6%。代码可在https://github.com/Mmurrad/EEG-To-text 获取。
🔬 方法详解
问题定义:论文旨在解决脑电信号到文本的转换问题,即如何准确地将脑电信号解码成有意义的文本。现有方法,如基于T5和Brain Translator的模型,在捕捉脑电信号的复杂时序依赖关系方面存在不足,导致生成文本的质量和准确性有待提高。
核心思路:论文的核心思路是结合循环神经网络(LSTM)和Transformer模型的优势。LSTM擅长处理序列数据,能够有效地捕捉脑电信号的时序依赖关系;Transformer模型具有强大的文本生成能力。通过将两者结合,可以更有效地将脑电信号解码成高质量的文本。
技术框架:R1 Translator模型主要由两个模块组成:双向LSTM编码器和预训练的Transformer解码器。首先,脑电信号经过预处理和嵌入后,输入到双向LSTM编码器中,提取脑电信号的时序特征。然后,LSTM编码器的输出被输入到预训练的Transformer解码器中,生成最终的文本。
关键创新:该模型最重要的创新点在于结合了LSTM和Transformer的优势,利用LSTM捕捉脑电信号的时序依赖关系,并利用Transformer生成高质量的文本。与现有方法相比,R1 Translator能够更有效地利用脑电信号的信息,从而提高解码的准确性和流畅性。
关键设计:模型使用了双向LSTM来更好地捕捉上下文信息。Transformer解码器使用了预训练模型,可以加速训练并提高生成文本的质量。损失函数使用了交叉熵损失函数,用于优化文本生成过程。具体的LSTM层数、Transformer层数、嵌入维度等参数设置未知,可能在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
R1 Translator在ROUGE-1指标上达到了38.00%(P),比T5高出9%,比Brain高出3%。在ROUGE-L指标上,F1得分为32.51%,比T5高出3%,比Brain高出2%。在CER指标上,R1达到了0.5795,比T5低2%,比Brain低4%。在WER指标上,R1达到了0.7280,比T5低4.3%,比Brain低3.6%。这些结果表明,R1 Translator在脑电信号到文本的解码任务上取得了显著的性能提升。
🎯 应用场景
该研究成果可应用于辅助沟通、脑机接口、神经疾病诊断等领域。例如,可以帮助失语症患者通过脑电信号表达意愿,实现无障碍交流。此外,该技术还可以用于监测大脑活动,辅助诊断癫痫等神经系统疾病,并为开发更先进的脑机接口设备提供技术支持。
📄 摘要(原文)
With the rapid advancement of large language models like Gemini, GPT, and others, bridging the gap between the human brain and language processing has become an important area of focus. To address this challenge, researchers have developed various models to decode EEG signals into text. However, these models still face significant performance limitations. To overcome these shortcomings, we propose a new model, R1 Translator, which aims to improve the performance of EEG-to-text decoding. The R1 Translator model combines a bidirectional LSTM encoder with a pretrained transformer-based decoder, utilizing EEG features to produce high-quality text outputs. The model processes EEG embeddings through the LSTM to capture sequential dependencies, which are then fed into the transformer decoder for effective text generation. The R1 Translator excels in ROUGE metrics, outperforming both T5 (previous research) and Brain Translator. Specifically, R1 achieves a ROUGE-1 score of 38.00% (P), which is up to 9% higher than T5 (34.89%) and 3% better than Brain (35.69%). It also leads in ROUGE-L, with a F1 score of 32.51%, outperforming T5 by 3% (29.67%) and Brain by 2% (30.38%). In terms of CER, R1 achieves a CER of 0.5795, which is 2% lower than T5 (0.5917) and 4% lower than Brain (0.6001). Additionally, R1 performs better in WER with a score of 0.7280, outperforming T5 by 4.3% (0.7610) and Brain by 3.6% (0.7553). Code is available at https://github.com/Mmurrad/EEG-To-text.