Game-RL: Synthesizing Multimodal Verifiable Game Data to Boost VLMs' General Reasoning
作者: Jingqi Tong, Jixin Tang, Hangcheng Li, Yurong Mou, Ming Zhang, Jun Zhao, Yanbo Wen, Fan Song, Jiahao Zhan, Yuyang Lu, Chaoran Tao, Zhiyuan Guo, Jizhou Yu, Tianhao Cheng, Zhiheng Xi, Changhao Jiang, Zhangyue Yin, Yining Zheng, Weifeng Ge, Guanhua Chen, Tao Gui, Xipeng Qiu, Qi Zhang, Xuanjing Huang
分类: cs.CL
发布日期: 2025-05-20 (更新: 2025-12-11)
备注: 69 pages, 24 figures
💡 一句话要点
提出Game-RL框架,利用可验证游戏数据提升视觉语言模型通用推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 强化学习 视频游戏 通用推理 多模态学习
📋 核心要点
- 现有视觉语言强化学习主要集中于特定领域,缺乏对通用推理能力的提升。
- Game-RL利用视频游戏提供的丰富视觉元素和可验证机制,构建多样化游戏任务。
- 实验表明,仅在GameQA上进行RL训练即可显著提升多个VLM在多个视觉语言基准上的性能。
📝 摘要(中文)
视觉语言强化学习(RL)主要集中在狭窄领域,例如几何或图表推理。这使得更广泛的训练场景和资源未被充分探索,限制了视觉语言模型(VLMs)通过RL进行探索和学习。我们发现视频游戏本身提供了丰富的视觉元素和易于验证的机制。为了充分利用视频游戏中多模态和可验证的奖励,我们提出了Game-RL,构建了多样化的游戏任务用于RL训练,以提高VLMs的通用推理能力。为了获得训练数据,我们提出了一种新颖的方法Code2Logic,该方法调整游戏代码以合成游戏推理任务数据,从而获得包含30个游戏和158个任务的GameQA数据集,并具有可控的难度等级。出乎意料的是,仅在GameQA上进行RL训练就能使多个VLM在7个不同的视觉语言基准测试中实现性能提升,证明了Game-RL在增强VLM的通用推理能力方面的价值。此外,这表明视频游戏可以作为有价值的场景和资源来提高通用推理能力。我们的代码、数据集和模型可在GitHub存储库中找到。
🔬 方法详解
问题定义:现有视觉语言强化学习方法主要集中在几何、图表等特定领域,缺乏对更广泛场景和资源的探索,限制了视觉语言模型(VLM)通用推理能力的提升。现有方法难以充分利用视频游戏等富含视觉信息和可验证反馈的资源。
核心思路:论文的核心思路是利用视频游戏作为训练VLM的理想环境。视频游戏具有丰富的视觉元素、可控的游戏机制以及易于验证的奖励信号,可以为VLM提供多样化和可验证的训练数据,从而提升其通用推理能力。通过设计合适的任务和奖励机制,可以引导VLM学习如何在复杂环境中进行推理和决策。
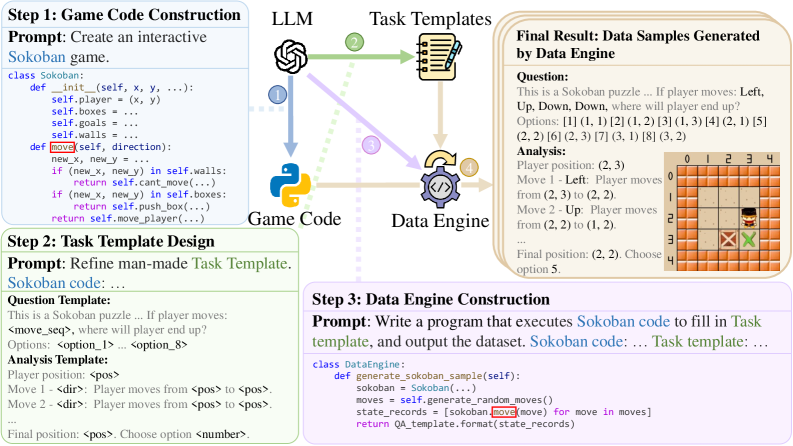
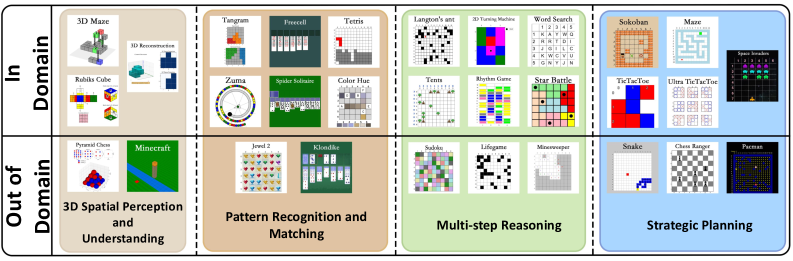
技术框架:Game-RL框架主要包含两个核心部分:一是GameQA数据集的构建,二是基于GameQA数据集的强化学习训练。GameQA数据集通过Code2Logic方法,将游戏代码转化为逻辑推理任务数据,包含30个游戏和158个任务。然后,利用这些数据对VLM进行强化学习训练,目标是让VLM学会根据游戏中的视觉信息和任务描述,进行推理并做出正确的决策。
关键创新:论文的关键创新在于提出了Code2Logic方法,该方法能够自动地将游戏代码转化为逻辑推理任务数据,从而大规模生成用于VLM训练的数据集。与传统的人工标注数据相比,Code2Logic方法具有更高的效率和可扩展性,并且可以生成具有可控难度等级的数据。此外,Game-RL框架本身也是一个创新,它将视频游戏作为VLM训练的理想环境,为VLM的通用推理能力提升提供了新的思路。
关键设计:Code2Logic方法的核心在于如何将游戏代码中的逻辑关系提取出来,并转化为自然语言描述的任务。具体来说,该方法首先分析游戏代码中的变量、函数和控制流,然后根据这些信息生成任务描述和答案。例如,对于一个需要收集特定物品的游戏任务,Code2Logic方法会提取出物品的名称、位置和数量等信息,然后生成类似“收集3个苹果”的任务描述。在强化学习训练方面,论文采用了标准的策略梯度算法,并设计了合适的奖励函数,以鼓励VLM学习如何完成游戏任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,仅使用GameQA数据集进行RL训练,即可显著提升多个VLM在7个不同的视觉语言基准测试上的性能。例如,在某个基准测试中,模型的准确率提升了超过5个百分点。这些结果表明,Game-RL框架和GameQA数据集对于提升VLM的通用推理能力具有重要价值,并且视频游戏可以作为VLM训练的有效资源。
🎯 应用场景
该研究成果可应用于提升视觉语言模型在各种实际场景中的推理能力,例如智能助手、自动驾驶、机器人导航等。通过利用视频游戏等虚拟环境进行训练,可以降低数据获取成本,并提高模型的泛化能力。未来,该方法有望扩展到更多类型的虚拟环境和任务,为人工智能的发展提供更强大的支持。
📄 摘要(原文)
Vision-language reinforcement learning (RL) has primarily focused on narrow domains (e.g. geometry or chart reasoning). This leaves broader training scenarios and resources underexplored, limiting the exploration and learning of Vision Language Models (VLMs) through RL. We find video games inherently provide rich visual elements and mechanics that are easy to verify. To fully use the multimodal and verifiable reward in video games, we propose Game-RL, constructing diverse game tasks for RL training to boost VLMs general reasoning ability. To obtain training data, we propose Code2Logic, a novel approach that adapts game code to synthesize game reasoning task data, thus obtaining the GameQA dataset of 30 games and 158 tasks with controllable difficulty gradation. Unexpectedly, RL training solely on GameQA enables multiple VLMs to achieve performance improvements across 7 diverse vision-language benchmarks, demonstrating the value of Game-RL for enhancing VLMs' general reasoning. Furthermore, this suggests that video games may serve as valuable scenarios and resources to boost general reasoning abilities. Our code, dataset and models are available at the GitHub repository.