SMOTExT: SMOTE meets Large Language Models
作者: Mateusz Bystroński, Mikołaj Hołysz, Grzegorz Piotrowski, Nitesh V. Chawla, Tomasz Kajdanowicz
分类: cs.CL
发布日期: 2025-05-19
💡 一句话要点
SMOTExT:结合SMOTE与大语言模型,解决NLP模型训练中的数据稀缺和类别不平衡问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据增强 类别不平衡 SMOTE 大语言模型 xRAG 文本生成 隐私保护机器学习
📋 核心要点
- NLP模型训练面临数据稀缺和类别不平衡的挑战,尤其是在专业领域或低资源环境中。
- SMOTExT通过在BERT嵌入空间中插值生成合成文本数据,并利用xRAG架构解码为连贯文本,实现数据增强。
- 初步实验表明,仅使用生成数据训练的模型性能与使用原始数据训练的模型相当,为隐私保护机器学习提供了可能。
📝 摘要(中文)
本文提出了一种名为SMOTExT的新技术,该技术将合成少数类过采样技术(SMOTE)的思想应用于文本数据。该方法通过在两个现有样本的基于BERT的嵌入之间进行插值来生成新的合成样本,然后使用xRAG架构将生成的潜在点解码为文本。通过利用xRAG的跨模态检索-生成框架,可以有效地将插值向量转换为连贯的文本。虽然这只是初步工作,仅由定性输出支持,但该方法在少样本设置中显示出知识蒸馏和数据增强的强大潜力。值得注意的是,我们的方法也显示出隐私保护机器学习的前景:在早期实验中,仅在生成数据上训练的模型获得了与在原始数据集上训练的模型相当的性能。这为数据保护约束下安全有效的学习提供了一条可行的途径。
🔬 方法详解
问题定义:NLP模型,尤其是在特定领域或低资源场景下,面临着数据稀缺和类别不平衡的问题。传统方法难以有效解决这些问题,导致模型泛化能力不足,对少数类的识别效果差。
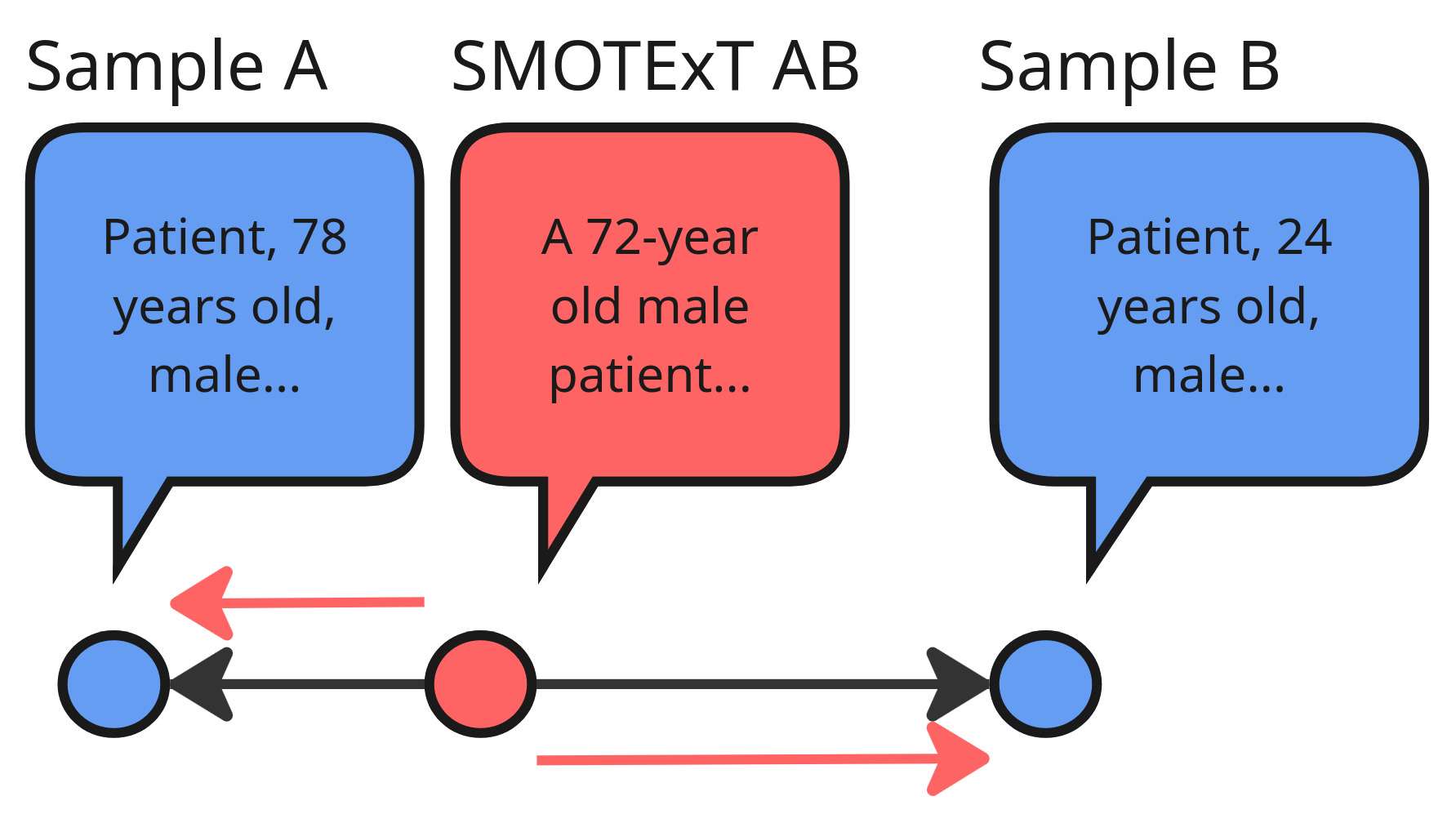
核心思路:SMOTExT的核心思想是将SMOTE算法从数值数据扩展到文本数据。通过在文本的嵌入空间中进行插值,生成新的合成文本样本,从而缓解数据稀缺和类别不平衡问题。这种方法利用了预训练语言模型的语义理解能力,保证了生成样本的质量。
技术框架:SMOTExT主要包含以下几个阶段:1) 使用BERT等预训练语言模型将现有文本样本编码为嵌入向量。2) 选择两个相似的样本,并在它们的嵌入向量之间进行插值,生成新的合成嵌入向量。3) 使用xRAG架构将合成嵌入向量解码为自然语言文本。xRAG作为一个跨模态检索-生成框架,负责将嵌入向量转化为连贯且有意义的文本。
关键创新:SMOTExT的关键创新在于将SMOTE算法与预训练语言模型相结合,实现了文本数据的合成过采样。与传统的文本数据增强方法(如同义词替换、随机插入等)相比,SMOTExT能够生成语义上更丰富、更具多样性的新样本。此外,利用xRAG架构进行解码,保证了生成文本的流畅性和可读性。
关键设计:在嵌入向量插值过程中,可以调整插值比例,控制生成样本与原始样本的相似度。xRAG架构的选择也很重要,需要根据具体的任务和数据集进行调整。损失函数的设计需要考虑生成文本的质量和多样性,例如可以使用语言模型损失和对比学习损失。
🖼️ 关键图片
📊 实验亮点
初步实验表明,使用SMOTExT生成的数据训练的模型,其性能可以与使用原始数据训练的模型相媲美。这表明SMOTExT在数据增强和隐私保护方面具有显著潜力。虽然目前仅有定性结果,但这些结果为未来的研究方向提供了有力的支持。
🎯 应用场景
SMOTExT可应用于各种NLP任务,尤其是在数据稀缺或类别不平衡的场景下,例如罕见疾病诊断、小语种翻译、金融欺诈检测等。该方法还可以用于知识蒸馏,通过生成大量合成数据来训练更小的模型。此外,其在隐私保护机器学习方面也具有潜力,可以在不暴露原始数据的情况下训练模型。
📄 摘要(原文)
Data scarcity and class imbalance are persistent challenges in training robust NLP models, especially in specialized domains or low-resource settings. We propose a novel technique, SMOTExT, that adapts the idea of Synthetic Minority Over-sampling (SMOTE) to textual data. Our method generates new synthetic examples by interpolating between BERT-based embeddings of two existing examples and then decoding the resulting latent point into text with xRAG architecture. By leveraging xRAG's cross-modal retrieval-generation framework, we can effectively turn interpolated vectors into coherent text. While this is preliminary work supported by qualitative outputs only, the method shows strong potential for knowledge distillation and data augmentation in few-shot settings. Notably, our approach also shows promise for privacy-preserving machine learning: in early experiments, training models solely on generated data achieved comparable performance to models trained on the original dataset. This suggests a viable path toward safe and effective learning under data protection constraints.