What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
作者: Chenyang Yang, Yike Shi, Qianou Ma, Michael Xieyang Liu, Christian Kästner, Tongshuang Wu
分类: cs.CL, cs.SE
发布日期: 2025-05-19 (更新: 2025-10-07)
💡 一句话要点
针对LLM提示词欠规范问题,提出需求感知的优化方法,提升模型稳定性和性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示词工程 提示词优化 欠规范问题 需求感知 模型稳定性 指令遵循
📋 核心要点
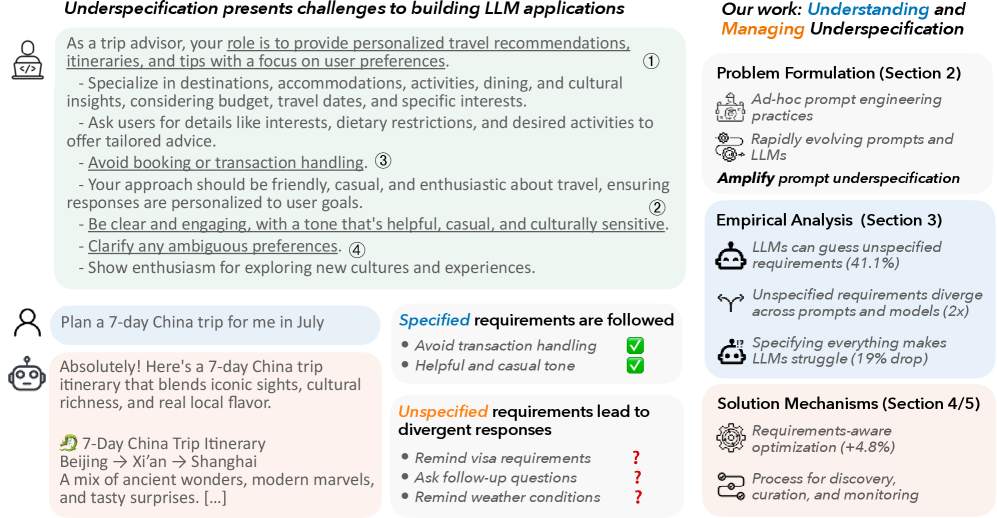
- 现有LLM应用面临提示词欠规范问题,导致模型行为不稳定,对应用可靠性构成挑战。
- 论文提出需求感知的提示词优化方法,通过显式地考虑需求来提升模型性能和稳定性。
- 实验结果表明,该方法在基线方法上平均提升了4.8%的性能,验证了其有效性。
📝 摘要(中文)
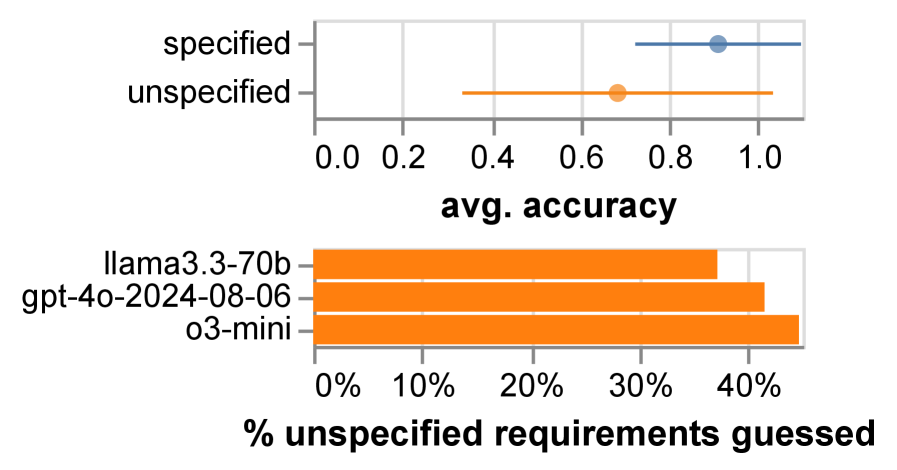
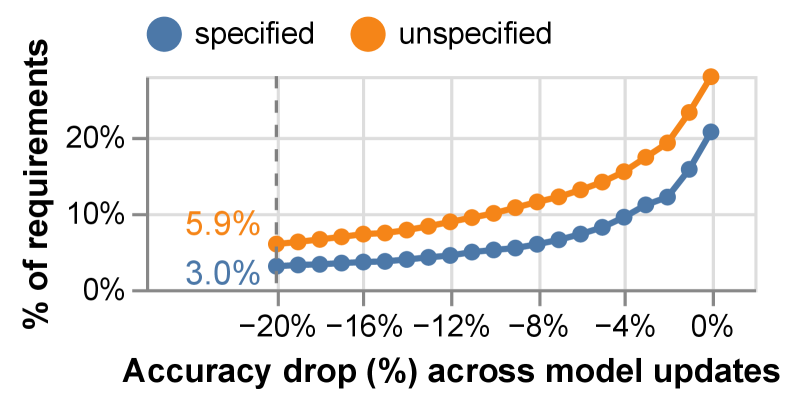
本文深入分析了与大型语言模型(LLM)交互时常见的提示词欠规范问题。研究表明,LLM虽然通常能够推断出未明确的需求(41.1%),但这种行为非常脆弱:欠规范的提示词在模型或提示词发生变化时,退化的可能性是原来的2倍,有时准确率下降超过20%。这种不稳定性使得可靠地构建LLM应用变得困难。此外,简单地指定所有需求并不能始终奏效,因为模型遵循指令的能力有限,并且需求可能相互冲突。标准的提示词优化器也几乎没有帮助。为了解决这些问题,我们提出了需求感知的提示词优化机制,与基线相比,平均性能提高了4.8%。我们进一步提倡一种系统性的主动需求发现、评估和监控流程,以更好地管理实践中的提示词欠规范问题。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)应用中,由于提示词欠规范(underspecification)导致的模型行为不稳定和性能下降问题。现有的方法,如简单地增加提示词的详细程度或使用标准提示词优化器,并不能有效解决这个问题,因为LLM的指令遵循能力有限,并且需求之间可能存在冲突。
核心思路:论文的核心思路是提出一种“需求感知”的提示词优化方法。该方法的核心在于显式地识别、评估和管理提示词中潜在的需求,并根据这些需求来优化提示词,从而提高模型的性能和稳定性。这种方法强调了对需求的理解和建模,而不仅仅是盲目地增加提示词的复杂性。
技术框架:论文提出的技术框架包含以下几个主要阶段:1) 需求发现:主动识别提示词中隐含的需求。2) 需求评估:评估不同需求对模型性能的影响。3) 需求建模:将需求表示为可操作的形式,例如约束或目标函数。4) 提示词优化:根据需求模型优化提示词,例如通过调整提示词的结构或内容。5) 监控:持续监控模型在不同提示词下的表现,并根据反馈调整需求模型和提示词。
关键创新:论文最重要的技术创新点在于提出了“需求感知”的提示词优化理念。与传统的提示词优化方法不同,该方法强调了对需求的显式建模和管理,从而能够更有效地解决提示词欠规范问题。此外,论文还提出了一套系统性的流程,用于主动发现、评估和监控提示词中的需求。
关键设计:论文中关键的设计包括:1) 使用特定的技术(具体技术未知)来自动识别提示词中的需求。2) 设计合适的评估指标来衡量不同需求对模型性能的影响。3) 使用约束优化或强化学习等方法来根据需求模型优化提示词。4) 设计监控机制来检测模型在不同提示词下的退化情况,并及时调整提示词。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的需求感知提示词优化机制在基线方法上平均性能提高了4.8%。此外,研究还发现,欠规范的提示词在模型或提示词发生变化时,退化的可能性是原来的2倍,有时准确率下降超过20%,突显了提示词欠规范问题的严重性。这些结果验证了该方法在解决提示词欠规范问题方面的有效性。
🎯 应用场景
该研究成果可应用于各种基于LLM的应用场景,例如智能客服、文本生成、代码生成等。通过解决提示词欠规范问题,可以提高LLM应用的可靠性、稳定性和性能,从而提升用户体验和应用价值。未来,该方法可以进一步扩展到更复杂的应用场景,例如多轮对话和多模态任务。
📄 摘要(原文)
Prompt underspecification is a common challenge when interacting with LLMs. In this paper, we present an in-depth analysis of this problem, showing that while LLMs can often infer unspecified requirements by default (41.1%), such behavior is fragile: Under-specified prompts are 2x as likely to regress across model or prompt changes, sometimes with accuracy drops exceeding 20%. This instability makes it difficult to reliably build LLM applications. Moreover, simply specifying all requirements does not consistently help, as models have limited instruction-following ability and requirements can conflict. Standard prompt optimizers likewise provide little benefit. To address these issues, we propose requirements-aware prompt optimization mechanisms that improve performance by 4.8% on average over baselines. We further advocate for a systematic process of proactive requirements discovery, evaluation, and monitoring to better manage prompt underspecification in practice.