Sense and Sensitivity: Examining the Influence of Semantic Recall on Long Context Code Reasoning
作者: Adam Štorek, Mukur Gupta, Samira Hajizadeh, Prashast Srivastava, Suman Jana
分类: cs.CL, cs.LG, cs.SE
发布日期: 2025-05-19 (更新: 2026-01-22)
💡 一句话要点
揭示语义召回对长上下文代码推理的影响,提出SemTrace基准测试LLM的语义理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文理解 代码推理 语义召回 模式匹配 基准测试
📋 核心要点
- 现有代码理解基准测试可能允许LLM通过模式匹配捷径解决问题,无法有效评估其真正的语义理解能力。
- 提出语义召回敏感度指标,并设计反事实测量方法,用于评估LLM对代码运算语义的理解程度。
- 引入SemTrace基准,该基准通过不可预测的操作提高了语义召回敏感度,更有效地评估LLM的语义理解能力。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于理解大型代码库,但它们是否真正理解长代码上下文的运算语义,还是仅仅依赖于模式匹配的捷径,这一点尚不清楚。本文区分了词汇召回(逐字检索代码)和语义召回(理解运算语义)。通过评估10个最先进的LLM,发现前沿模型几乎实现了完美的、位置独立的词汇召回,但当代码位于长上下文的中心位置时,语义召回会严重下降。本文引入了语义召回敏感度,以衡量任务是否需要理解代码的运算语义,还是允许使用模式匹配的捷径。通过一种新颖的反事实测量方法,表明模型严重依赖模式匹配的捷径来解决现有的代码理解基准。本文提出了一项新的任务SemTrace,该任务通过不可预测的操作实现了高语义召回敏感度;LLM的准确性表现出严重的位置效应,当相关代码片段接近输入代码上下文的中间位置时,准确率中位数下降了92.73%,而CRUXEval的下降幅度为53.36%。研究结果表明,目前的评估大大低估了长上下文代码理解中的语义召回失败。
🔬 方法详解
问题定义:现有的大型语言模型在处理长上下文代码时,其代码理解能力,特别是对代码运算语义的理解,尚不明确。现有的代码理解基准测试可能存在漏洞,允许模型通过简单的模式匹配来解决问题,而无需真正理解代码的含义。这导致对LLM真实代码理解能力的过高估计。
核心思路:核心思路是区分词汇召回(简单的代码检索)和语义召回(理解代码的运算语义)。通过设计对语义召回敏感的任务,可以更准确地评估LLM是否真正理解代码,而不是仅仅依赖于模式匹配。通过反事实分析,可以量化模型在多大程度上依赖于模式匹配的捷径。
技术框架:论文提出了以下技术框架:1) 定义语义召回敏感度指标,用于衡量任务对语义理解的要求程度。2) 设计反事实测量方法,通过修改代码并观察模型行为的变化,来评估模型对模式匹配的依赖程度。3) 提出新的基准测试SemTrace,该基准测试包含一系列需要理解代码运算语义才能解决的任务。SemTrace的设计目标是最大化语义召回敏感度,减少模式匹配的可能性。
关键创新:关键创新在于提出了语义召回敏感度的概念,并设计了相应的测量方法。此外,SemTrace基准测试的设计也具有创新性,它通过引入不可预测的操作,使得模型难以通过简单的模式匹配来解决问题,从而更有效地评估了模型的语义理解能力。
关键设计:SemTrace基准测试的关键设计包括:1) 使用不可预测的操作,例如随机数生成和动态数据结构,来增加代码的复杂性。2) 将关键代码片段放置在长上下文的不同位置,以评估模型的位置敏感性。3) 使用多种编程语言,以增加基准测试的通用性。此外,反事实测量方法通过对代码进行细微的修改(例如,改变变量名或操作顺序),来观察模型行为的变化,从而推断模型对模式匹配的依赖程度。
🖼️ 关键图片
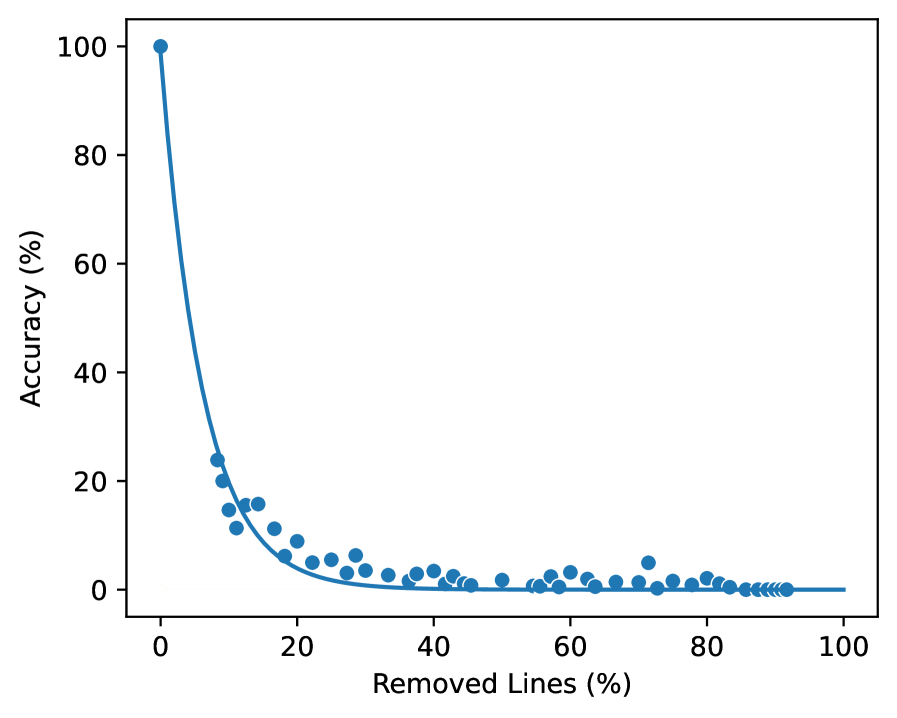

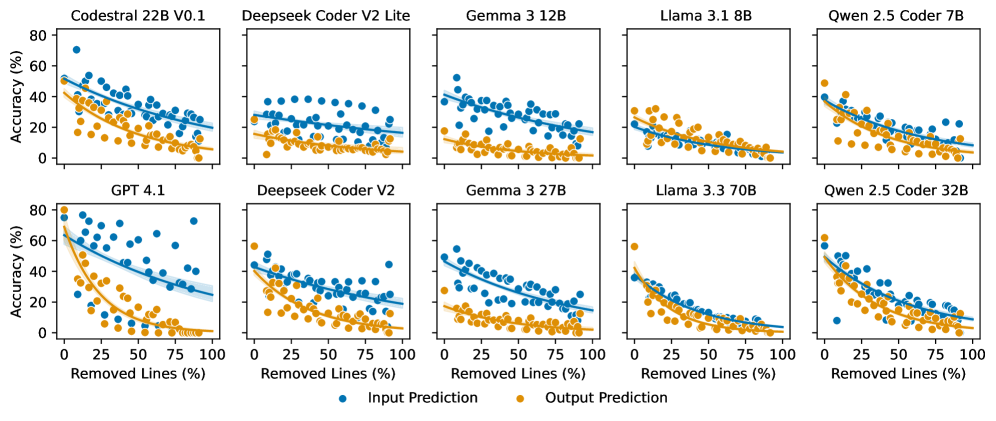
📊 实验亮点
实验结果表明,虽然LLM在词汇召回方面表现出色,但在语义召回方面存在显著不足,尤其是在长上下文的中间位置。SemTrace基准测试显示,当相关代码片段接近输入代码上下文的中间位置时,LLM的准确率中位数下降了92.73%,而CRUXEval的下降幅度仅为53.36%。这表明现有基准测试可能高估了LLM的代码理解能力。
🎯 应用场景
该研究成果可应用于提升代码自动补全、代码缺陷检测、代码翻译等任务的性能。通过更准确地评估LLM的代码理解能力,可以开发出更可靠、更智能的软件开发工具。此外,该研究也为未来LLM的架构设计和训练提供了新的思路,有助于构建更强大的代码理解模型。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed for understanding large codebases, but whether they understand operational semantics of long code context or rely on pattern matching shortcuts remains unclear. We distinguish between lexical recall (retrieving code verbatim) and semantic recall (understanding operational semantics). Evaluating 10 state-of-the-art LLMs, we find that while frontier models achieve near-perfect, position-independent lexical recall, semantic recall degrades severely when code is centrally positioned in long contexts. We introduce semantic recall sensitivity to measure whether tasks require understanding of code's operational semantics vs. permit pattern matching shortcuts. Through a novel counterfactual measurement method, we show that models rely heavily on pattern matching shortcuts to solve existing code understanding benchmarks. We propose a new task SemTrace, which achieves high semantic recall sensitivity through unpredictable operations; LLMs' accuracy exhibits severe positional effects, with median accuracy drops of 92.73% versus CRUXEval's 53.36% as the relevant code snippet approaches the middle of the input code context. Our findings suggest current evaluations substantially underestimate semantic recall failures in long context code understanding.