Language-Specific Latent Process Hinders Cross-Lingual Performance
作者: Zheng Wei Lim, Alham Fikri Aji, Trevor Cohn
分类: cs.CL
发布日期: 2025-05-19 (更新: 2025-09-26)
💡 一句话要点
揭示语言特定隐变量阻碍跨语言性能,提出引导方法提升小模型跨语言推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言学习 语言模型 表征相似性 隐变量 知识迁移
📋 核心要点
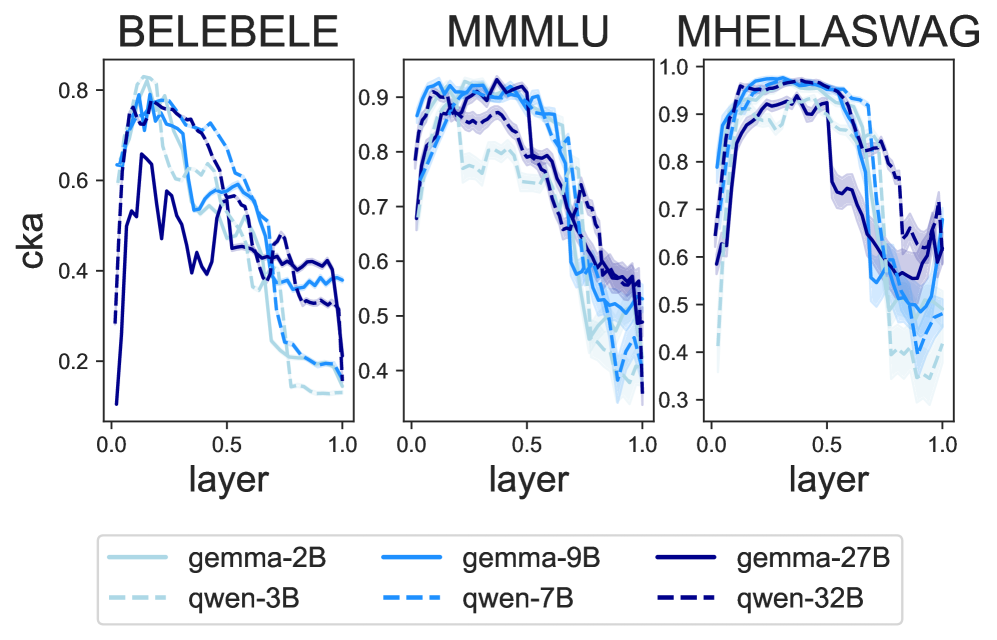
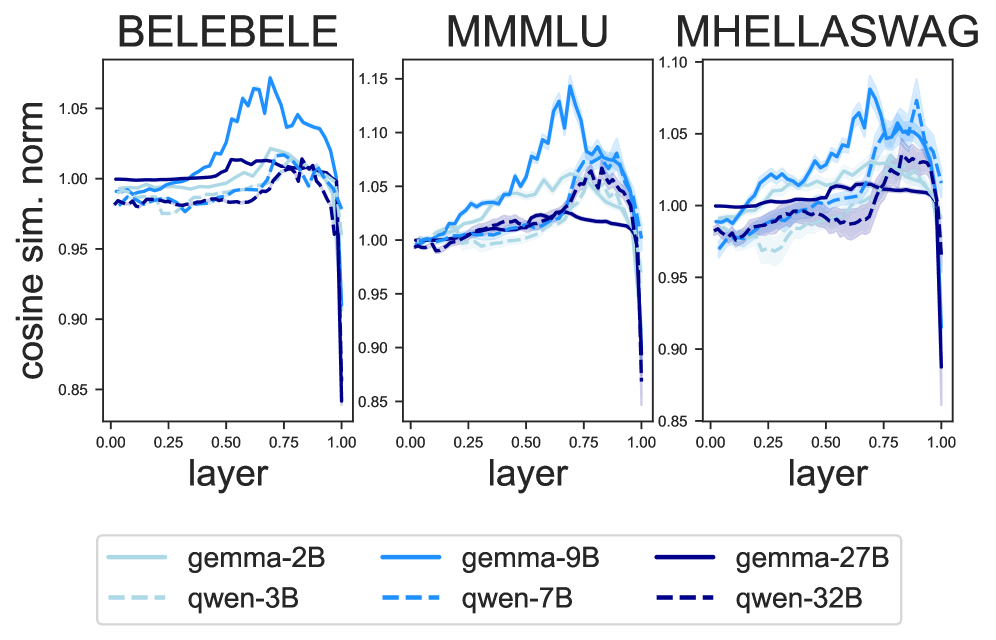
- 大型语言模型在跨语言任务中表现不一致,源于其对不同语言使用了不同的内部表征。
- 通过测量表征相似性和应用logit lens,论文揭示了模型在不同语言间推理时依赖非共享语义空间。
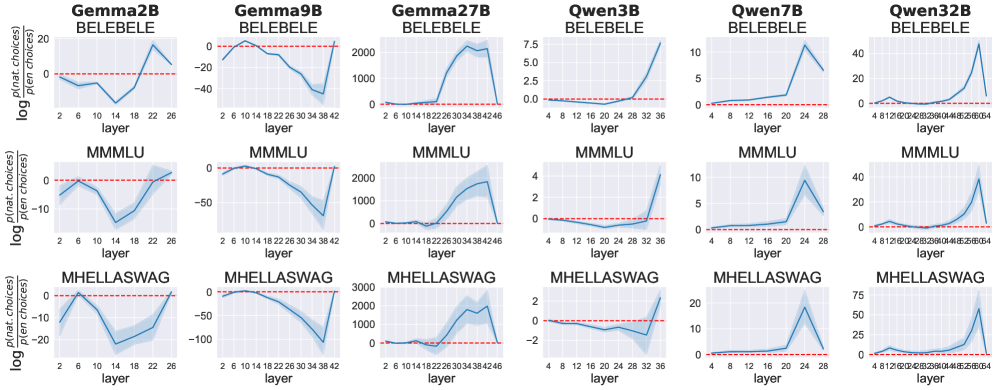
- 通过引导小模型的隐变量处理,使其更接近共享语义空间,从而提升跨语言推理性能和输出一致性。
📝 摘要(中文)
大型语言模型(LLM)在跨语言迁移方面表现出色,但当使用不同语言的相同查询提示时,会产生不一致的输出。为了理解语言模型如何从一种语言推广知识到其他语言,我们测量了语言之间的表征相似性,并应用logit lens来解释LLM解决多语言多项选择推理问题所采取的隐式步骤。我们的分析表明,LLM预测不一致且准确率较低,因为它们依赖于跨语言不相似的表征,而不是在共享语义空间中工作。虽然较大的模型更具多语言能力,但我们发现,与较小的模型相比,它们的隐藏状态更可能与共享表征分离,但仍然更能够检索嵌入在不同语言中的知识。最后,我们证明了可以通过引导小模型的潜在处理朝着共享语义空间的方向发展来促进知识共享。由于更多地从英语进行知识迁移以及与英语更好的输出一致性,这提高了模型的多语言推理性能。
🔬 方法详解
问题定义:大型语言模型在跨语言迁移学习中表现出能力,但对于相同语义的不同语言输入,其输出结果可能不一致。现有方法缺乏对这种不一致性的深入理解,以及如何有效提升跨语言知识共享的机制。论文旨在探究LLM在处理不同语言时内部表征的差异,并寻找提升跨语言性能的方法。
核心思路:论文的核心思路是,LLM在不同语言之间表现不一致,是因为它们在内部使用了语言特定的隐变量,导致不同语言的表征空间不一致。为了解决这个问题,论文提出通过引导模型的隐变量处理,使其更接近一个共享的语义空间,从而促进跨语言知识共享。
技术框架:论文主要包含以下几个阶段:1) 表征相似性测量:使用某种度量(具体方法未知)来量化不同语言在LLM内部表征上的相似程度。2) Logit Lens分析:利用logit lens技术来解释LLM在解决多语言多项选择推理问题时所采取的隐式步骤,从而理解其推理过程。3) 隐变量引导:设计一种方法来引导小模型的隐变量处理,使其更接近共享语义空间。4) 性能评估:在多语言推理任务上评估模型的性能,并比较引导前后的效果。
关键创新:论文的关键创新在于:1) 揭示了语言特定隐变量是阻碍跨语言性能的关键因素。2) 提出了一种通过引导隐变量处理来提升跨语言知识共享的方法。这种方法能够有效地提高小模型的跨语言推理性能和输出一致性。
关键设计:论文的关键设计细节包括:1) 如何定义和测量不同语言之间的表征相似性(具体方法未知)。2) 如何设计隐变量引导方法,使其能够有效地将模型的隐变量处理拉向共享语义空间(具体方法未知)。3) 如何选择合适的多语言推理任务来评估模型的性能。
🖼️ 关键图片
📊 实验亮点
论文通过实验证明,引导小模型的隐变量处理使其更接近共享语义空间,可以显著提升其跨语言推理性能和输出一致性。具体提升幅度未知,但结果表明,即使是较小的模型,通过合适的引导策略,也能有效地进行跨语言知识迁移。
🎯 应用场景
该研究成果可应用于提升多语言自然语言处理系统的性能,例如多语言机器翻译、跨语言信息检索和多语言对话系统。通过提高模型在不同语言之间的知识共享能力,可以构建更加鲁棒和一致的多语言应用,从而更好地服务于全球用户。
📄 摘要(原文)
Large language models (LLMs) are demonstrably capable of cross-lingual transfer, but can produce inconsistent output when prompted with the same queries written in different languages. To understand how language models are able to generalize knowledge from one language to the others, we measure representation similarity between languages, and apply the logit lens to interpret the implicit steps taken by LLMs to solve multilingual multi-choice reasoning questions. Our analyses reveal LLMs predict inconsistently and are less accurate because they rely on representations that are dissimilar across languages, rather than working in a shared semantic space. While larger models are more multilingual, we show their hidden states are more likely to dissociate from the shared representation compared to smaller models, but are nevertheless more capable of retrieving knowledge embedded across different languages. Finally, we demonstrate that knowledge sharing in small models can be facilitated by steering their latent processing towards the shared semantic space. This improves the models' multilingual reasoning performance, as a result of more knowledge transfer from, and better output consistency with English.