Qwen3 Technical Report
作者: An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Lianghao Deng, Mei Li, Mingfeng Xue, Mingze Li, Pei Zhang, Peng Wang, Qin Zhu, Rui Men, Ruize Gao, Shixuan Liu, Shuang Luo, Tianhao Li, Tianyi Tang, Wenbiao Yin, Xingzhang Ren, Xinyu Wang, Xinyu Zhang, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yinger Zhang, Yu Wan, Yuqiong Liu, Zekun Wang, Zeyu Cui, Zhenru Zhang, Zhipeng Zhou, Zihan Qiu
分类: cs.CL
发布日期: 2025-05-14
💡 一句话要点
Qwen3:融合思考与非思考模式的大语言模型,提升性能、效率和多语言能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 混合专家模型 思考模式 非思考模式 思考预算 多语言支持 知识蒸馏 动态模式切换
📋 核心要点
- 现有大语言模型在复杂推理和快速响应之间难以兼顾,需要切换不同模型。
- Qwen3融合思考与非思考模式,并引入思考预算机制,动态分配计算资源。
- 实验表明,Qwen3在代码生成、数学推理等任务上达到SOTA,并扩展至119种语言。
📝 摘要(中文)
本文介绍了Qwen3,Qwen模型系列的最新版本。Qwen3包含一系列旨在提升性能、效率和多语言能力的大语言模型(LLM)。Qwen3系列包括稠密模型和混合专家(MoE)架构,参数规模从0.6亿到2350亿不等。Qwen3的一个关键创新是将思考模式(用于复杂的多步骤推理)和非思考模式(用于快速的、上下文驱动的响应)集成到一个统一的框架中。这消除了在不同模型之间切换的需要——例如,针对聊天优化的模型(如GPT-4o)和专门的推理模型(如QwQ-32B)——并能够基于用户查询或聊天模板进行动态模式切换。同时,Qwen3引入了一种思考预算机制,允许用户在推理过程中自适应地分配计算资源,从而根据任务复杂性平衡延迟和性能。此外,通过利用旗舰模型的知识,我们显著减少了构建较小规模模型所需的计算资源,同时确保了其极具竞争力的性能。经验评估表明,Qwen3在各种基准测试中取得了最先进的结果,包括代码生成、数学推理、Agent任务等,与更大的MoE模型和专有模型相比具有竞争力。与之前的Qwen2.5相比,Qwen3将多语言支持从29种扩展到119种语言和方言,通过改进的跨语言理解和生成能力增强了全球可访问性。为了促进可重复性和社区驱动的研究和开发,所有Qwen3模型均在Apache 2.0下公开提供。
🔬 方法详解
问题定义:现有的大语言模型通常针对特定任务进行优化,例如聊天或推理,导致需要在不同模型之间切换以满足不同的需求。此外,计算资源的分配通常是静态的,无法根据任务的复杂性进行调整,从而影响效率和性能。
核心思路:Qwen3的核心思路是将思考模式(用于复杂推理)和非思考模式(用于快速响应)集成到一个统一的框架中,并引入思考预算机制,允许用户根据任务的复杂性动态地分配计算资源。这样可以避免在不同模型之间切换,并提高计算效率。
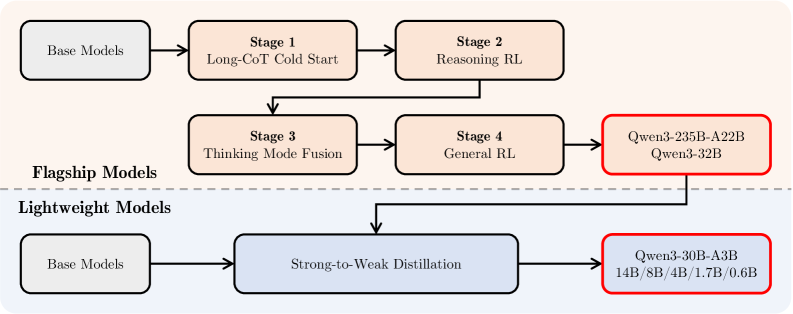
技术框架:Qwen3的技术框架包括一个统一的模型架构,该架构能够支持思考和非思考两种模式。该框架还包括一个思考预算机制,允许用户在推理过程中自适应地分配计算资源。此外,Qwen3还利用了知识蒸馏技术,将旗舰模型的知识转移到较小规模的模型中,从而减少了计算资源的需求。
关键创新:Qwen3最重要的技术创新点是将思考和非思考模式集成到一个统一的框架中,并引入思考预算机制。这种方法与现有方法的本质区别在于,它能够动态地调整模型的行为,以适应不同的任务需求,从而提高效率和性能。
关键设计:Qwen3的关键设计包括:1) 统一的模型架构,该架构能够支持思考和非思考两种模式;2) 思考预算机制,允许用户在推理过程中自适应地分配计算资源;3) 知识蒸馏技术,将旗舰模型的知识转移到较小规模的模型中;4) 扩展至119种语言的多语言支持。
🖼️ 关键图片
📊 实验亮点
Qwen3在代码生成、数学推理、Agent任务等多个基准测试中取得了最先进的结果,与更大的MoE模型和专有模型相比具有竞争力。此外,Qwen3将多语言支持从29种扩展到119种语言和方言,显著提升了跨语言理解和生成能力。
🎯 应用场景
Qwen3的应用场景广泛,包括智能客服、代码生成、数学推理、Agent任务等。其动态模式切换和思考预算机制使其能够适应不同的任务需求,提高效率和性能。扩展的多语言支持使其在全球范围内具有广泛的应用前景,促进跨语言交流和协作。
📄 摘要(原文)
In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.