A Comprehensive Analysis of Large Language Model Outputs: Similarity, Diversity, and Bias
作者: Brandon Smith, Mohamed Reda Bouadjenek, Tahsin Alamgir Kheya, Phillip Dawson, Sunil Aryal
分类: cs.CL
发布日期: 2025-05-14
💡 一句话要点
大规模语言模型输出分析:相似性、多样性与偏见研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 文本生成 相似性分析 多样性评估 偏见分析 自然语言处理 伦理评估
📋 核心要点
- 现有LLM在文本生成等任务表现出色,但其输出的相似性、多样性和潜在伦理问题仍待深入研究。
- 该研究通过大规模实验,对比分析了多个主流LLM在不同任务下的输出,揭示了它们在相似性、多样性和偏见方面的差异。
- 实验结果表明,不同LLM的输出风格迥异,且在性别偏见等方面存在差异,为LLM的未来发展和伦理评估提供了重要参考。
📝 摘要(中文)
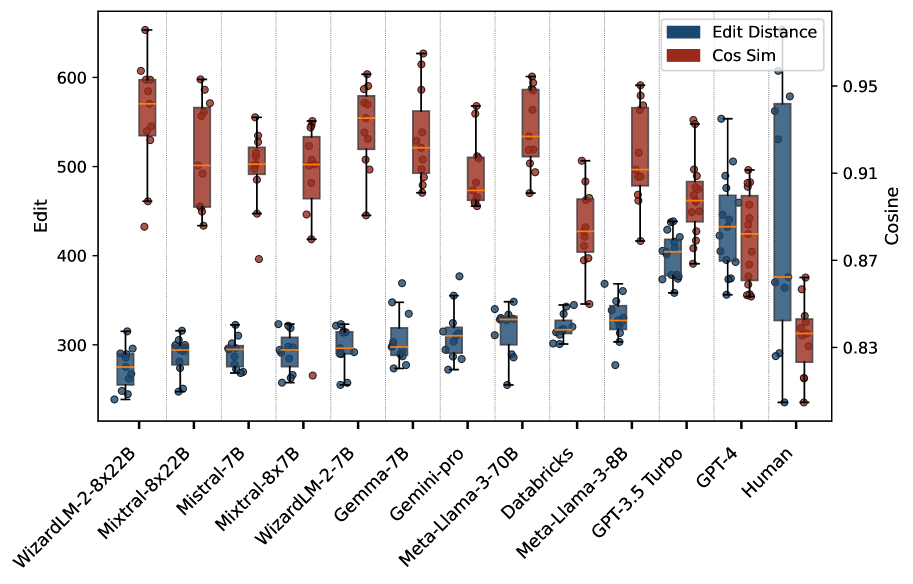
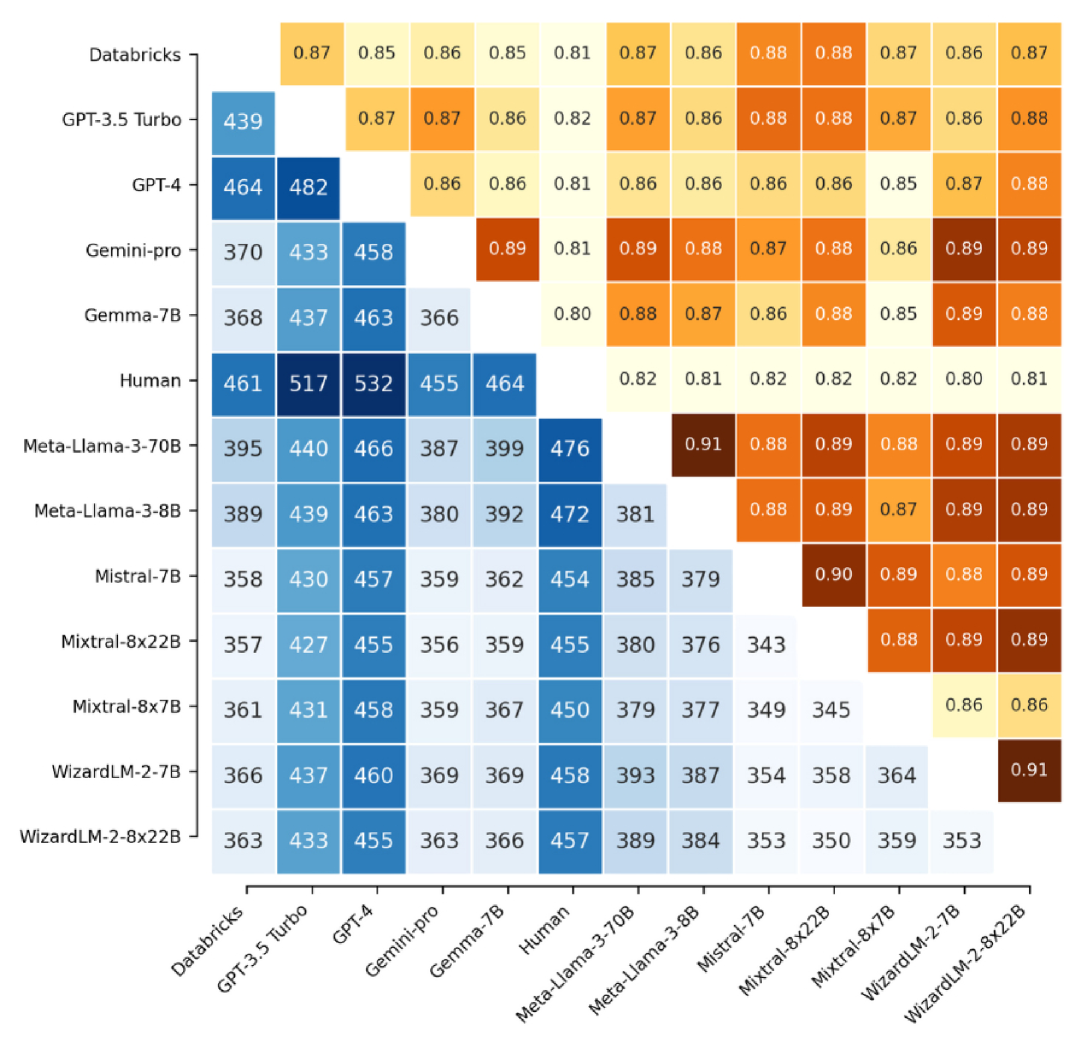
本文对大规模语言模型(LLMs)的输出进行了全面分析,重点关注其相似性、多样性和伦理影响。通过使用5000个提示词,涵盖生成、解释和重写等多种任务,生成了来自OpenAI、Google、Microsoft、Meta和Mistral等12个LLM的约300万个文本。研究发现,同一LLM的输出比人类文本更相似;WizardLM-2-8x22b生成高度相似的输出,而GPT-4的响应更多样;不同LLM的写作风格差异显著,Llama 3和Mistral的相似度较高,GPT-4则具有独特性;词汇和语气的差异突显了LLM生成内容的语言独特性;部分LLM在性别平衡和减少偏见方面表现更佳。这些结果为LLM输出的行为和多样性提供了新的见解,有助于指导未来的开发和伦理评估。
🔬 方法详解
问题定义:现有的大语言模型在自然语言处理任务中表现出色,但其输出的相似性、多样性和潜在的偏见问题仍然是研究的重点。现有方法缺乏对不同模型在各种任务下的输出进行系统性比较分析,难以全面评估其性能和伦理影响。
核心思路:该研究的核心思路是通过设计涵盖多种任务的大规模提示词集合,生成来自不同LLM的输出,并采用多种指标来量化评估这些输出的相似性、多样性和偏见程度。通过对比分析不同模型的表现,揭示其在生成内容方面的差异和优劣。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 设计包含生成、解释和重写等多种任务的5000个提示词;2) 使用这些提示词生成来自12个LLM(包括OpenAI、Google、Microsoft、Meta和Mistral等公司的模型)的输出,总计约300万个文本;3) 采用多种指标(如余弦相似度、词汇多样性、性别偏见评分等)来量化评估这些输出的相似性、多样性和偏见程度;4) 对比分析不同模型的评估结果,揭示其在生成内容方面的差异和优劣。
关键创新:该研究的关键创新在于其对大规模语言模型输出的全面分析,涵盖了相似性、多样性和偏见等多个维度。通过大规模实验和多种评估指标,揭示了不同模型在生成内容方面的差异和优劣,为LLM的未来发展和伦理评估提供了重要参考。
关键设计:该研究的关键设计包括:1) 提示词的设计,需要覆盖多种任务类型,以全面评估模型的生成能力;2) 评估指标的选择,需要能够有效量化输出的相似性、多样性和偏见程度;3) 模型选择,需要涵盖主流的LLM,以保证研究结果的代表性。
🖼️ 关键图片
📊 实验亮点
研究发现,同一LLM的输出比人类文本更相似;WizardLM-2-8x22b生成高度相似的输出,而GPT-4的响应更多样;不同LLM的写作风格差异显著,Llama 3和Mistral的相似度较高,GPT-4则具有独特性;部分LLM在性别平衡和减少偏见方面表现更佳。这些结果为LLM的开发和伦理评估提供了重要参考。
🎯 应用场景
该研究成果可应用于LLM的开发和评估,帮助开发者更好地了解模型的行为和特点,从而改进模型的设计和训练,提高其性能和伦理水平。此外,该研究还可以为用户选择合适的LLM提供参考,并促进LLM在各个领域的应用,如文本生成、机器翻译、智能客服等。
📄 摘要(原文)
Large Language Models (LLMs) represent a major step toward artificial general intelligence, significantly advancing our ability to interact with technology. While LLMs perform well on Natural Language Processing tasks -- such as translation, generation, code writing, and summarization -- questions remain about their output similarity, variability, and ethical implications. For instance, how similar are texts generated by the same model? How does this compare across different models? And which models best uphold ethical standards? To investigate, we used 5{,}000 prompts spanning diverse tasks like generation, explanation, and rewriting. This resulted in approximately 3 million texts from 12 LLMs, including proprietary and open-source systems from OpenAI, Google, Microsoft, Meta, and Mistral. Key findings include: (1) outputs from the same LLM are more similar to each other than to human-written texts; (2) models like WizardLM-2-8x22b generate highly similar outputs, while GPT-4 produces more varied responses; (3) LLM writing styles differ significantly, with Llama 3 and Mistral showing higher similarity, and GPT-4 standing out for distinctiveness; (4) differences in vocabulary and tone underscore the linguistic uniqueness of LLM-generated content; (5) some LLMs demonstrate greater gender balance and reduced bias. These results offer new insights into the behavior and diversity of LLM outputs, helping guide future development and ethical evaluation.