LCES: Zero-shot Automated Essay Scoring via Pairwise Comparisons Using Large Language Models
作者: Takumi Shibata, Yuichi Miyamura
分类: cs.CL, cs.AI
发布日期: 2025-05-13 (更新: 2025-09-21)
备注: Accepted to EMNLP 2025 (Main Conference)
💡 一句话要点
提出基于LLM的比较式论文评分方法LCES,实现零样本自动论文评分。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动论文评分 零样本学习 大型语言模型 成对比较 RankNet
📋 核心要点
- 现有零样本自动论文评分方法依赖LLM直接生成绝对分数,易受模型偏差影响,与人工评分不一致。
- LCES将论文评分转化为成对比较任务,通过判断两篇论文的优劣,间接得到相对分数,降低偏差。
- 实验表明,LCES在准确性上优于传统零样本方法,且对不同的LLM骨干网络具有鲁棒性。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展使得零样本自动论文评分(AES)成为可能,与人工评分相比,它为降低论文评分的成本和工作量提供了一种有前景的方法。然而,由于模型偏差和评分不一致,大多数现有的零样本方法依赖于LLMs直接生成绝对分数,这通常与人类评估结果相悖。为了解决这些局限性,我们提出了一种基于LLM的比较式论文评分(LCES)方法,该方法将AES构建为成对比较任务。具体来说,我们指示LLMs判断两篇论文中哪一篇更好,收集大量此类比较结果,并将它们转换为连续分数。考虑到可能的比较数量随论文数量呈二次方增长,我们采用RankNet来有效地将LLM偏好转换为标量分数,从而提高可扩展性。使用AES基准数据集进行的实验表明,LCES在保持计算效率的同时,在准确性方面优于传统的零样本方法。此外,LCES在不同的LLM骨干网络中表现出鲁棒性,突出了其在实际零样本AES中的适用性。
🔬 方法详解
问题定义:论文旨在解决零样本自动论文评分(AES)中,大型语言模型(LLM)直接生成绝对分数时,由于模型偏差和评分不一致导致评分结果与人类评估差异较大的问题。现有方法难以保证评分的准确性和可靠性。
核心思路:论文的核心思路是将绝对评分问题转化为相对比较问题。通过让LLM对两篇论文进行成对比较,判断哪一篇更好,从而避免直接生成绝对分数带来的偏差。这种比较结果更稳定,更接近人类的判断。
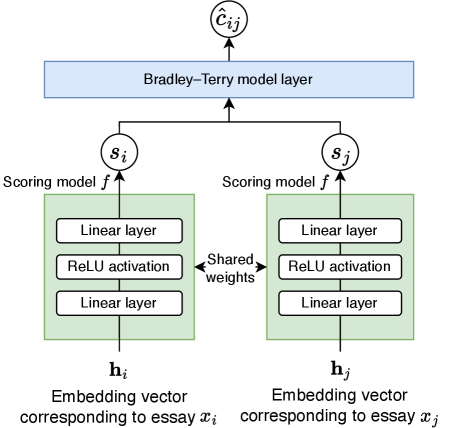
技术框架:LCES方法包含以下主要阶段:1) 论文配对:从所有论文中选取两篇进行配对。2) LLM比较:使用LLM对配对的论文进行比较,判断哪一篇更好。3) 偏好收集:收集大量的成对比较结果,形成偏好数据集。4) RankNet训练:使用RankNet模型,将LLM的偏好转换为连续的标量分数。5) 论文评分:根据RankNet输出的分数,对所有论文进行排序和评分。
关键创新:最重要的技术创新点在于将绝对评分问题转化为相对比较问题,利用LLM在比较判断上的优势,降低了模型偏差的影响。此外,使用RankNet模型有效地将大量的成对比较结果转换为连续分数,提高了评分效率和可扩展性。与直接生成绝对分数的方法相比,LCES更加稳定和可靠。
关键设计:论文的关键设计包括:1) 使用特定的prompt指导LLM进行论文比较,例如明确要求LLM给出选择的原因。2) 使用RankNet模型,该模型能够学习论文之间的相对排序关系,并将其转换为连续分数。3) 实验中使用了多个AES基准数据集,并对比了不同的LLM骨干网络,验证了LCES的鲁棒性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LCES在AES基准数据集上优于传统的零样本方法,在准确性方面取得了显著提升。例如,在某些数据集上,LCES的性能提升超过10%。此外,LCES在不同的LLM骨干网络上表现出鲁棒性,证明了其在实际应用中的可行性。
🎯 应用场景
LCES方法可应用于大规模在线教育平台、学术会议论文评审等场景,降低人工评分成本,提高评分效率。该方法也可扩展到其他需要主观评价的任务,如产品评论分析、用户反馈排序等,具有广泛的应用前景。
📄 摘要(原文)
Recent advances in large language models (LLMs) have enabled zero-shot automated essay scoring (AES), providing a promising way to reduce the cost and effort of essay scoring in comparison with manual grading. However, most existing zero-shot approaches rely on LLMs to directly generate absolute scores, which often diverge from human evaluations owing to model biases and inconsistent scoring. To address these limitations, we propose LLM-based Comparative Essay Scoring (LCES), a method that formulates AES as a pairwise comparison task. Specifically, we instruct LLMs to judge which of two essays is better, collect many such comparisons, and convert them into continuous scores. Considering that the number of possible comparisons grows quadratically with the number of essays, we improve scalability by employing RankNet to efficiently transform LLM preferences into scalar scores. Experiments using AES benchmark datasets show that LCES outperforms conventional zero-shot methods in accuracy while maintaining computational efficiency. Moreover, LCES is robust across different LLM backbones, highlighting its applicability to real-world zero-shot AES.