Large Language Models Meet Stance Detection: A Survey of Tasks, Methods, Applications, Challenges and Future Directions
作者: Lata Pangtey, Anukriti Bhatnagar, Shubhi Bansal, Shahid Shafi Dar, Nagendra Kumar
分类: cs.CL, cs.LG, cs.SI
发布日期: 2025-05-13 (更新: 2026-01-19)
💡 一句话要点
综述:大型语言模型在立场检测中的应用、方法、挑战与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 立场检测 自然语言处理 综述 深度学习
📋 核心要点
- 现有立场检测综述缺乏对大型语言模型(LLM)应用的全面覆盖,限制了研究人员对该领域最新进展的理解。
- 本文系统分析了LLM在立场检测中的应用,并提出了一个新颖的分类方法,涵盖学习方法、数据模态和目标关系三个维度。
- 本文讨论了评估技术、分析了基准数据集和性能趋势,并强调了不同架构的优势和局限性,为未来研究提供了指导。
📝 摘要(中文)
立场检测对于理解社交媒体、新闻文章和在线评论等平台上的主观内容至关重要。大型语言模型(LLMs)通过引入上下文理解、跨领域泛化和多模态分析等方面的新能力,彻底改变了立场检测。本文旨在弥补现有综述缺乏对LLM在立场检测中应用的全面覆盖的不足,系统地分析了立场检测,全面考察了LLM在该领域中的最新进展,包括基本概念、方法、数据集、应用和新兴挑战。我们提出了一种新颖的基于LLM的立场检测方法分类,该分类沿三个关键维度构建:1)学习方法,包括监督、无监督、少样本和零样本;2)数据模态,如单模态、多模态和混合模态;3)目标关系,包括目标内、跨目标和多目标场景。此外,我们还讨论了评估技术,分析了基准数据集和性能趋势,强调了不同架构的优势和局限性。讨论了在错误信息检测、政治分析、公共健康监测和社交媒体管理等方面的关键应用。最后,我们指出了诸如隐式立场表达、文化偏见和计算约束等关键挑战,同时概述了有希望的未来方向,包括可解释的立场推理、低资源适应和实时部署框架。我们的综述强调了新兴趋势、开放挑战和未来方向,以指导研究人员和从业人员开发由大型语言模型驱动的下一代立场检测系统。
🔬 方法详解
问题定义:论文旨在解决现有立场检测综述对大型语言模型(LLM)应用覆盖不足的问题。现有方法难以全面了解LLM在立场检测中的最新进展,包括其在不同学习范式、数据模态和目标关系中的应用。
核心思路:论文的核心思路是对基于LLM的立场检测方法进行系统性的分类和分析,从而为研究人员提供一个全面的视角,了解LLM在立场检测中的应用现状、挑战和未来方向。通过构建一个多维度的分类框架,论文旨在揭示不同方法的优势和局限性,并为未来的研究提供指导。
技术框架:论文的技术框架主要包括以下几个阶段:1)文献收集与筛选:收集近年来发表的关于LLM在立场检测中应用的相关论文;2)分类框架构建:基于学习方法、数据模态和目标关系三个维度,构建一个多维度的分类框架;3)方法分析与比较:对不同类别的方法进行详细分析和比较,包括其原理、优势、局限性等;4)应用场景分析:分析LLM在立场检测中的应用场景,包括错误信息检测、政治分析、公共健康监测等;5)挑战与未来方向:总结当前面临的挑战,并展望未来的发展方向。
关键创新:论文的关键创新在于提出了一个新颖的基于LLM的立场检测方法分类框架,该框架从学习方法、数据模态和目标关系三个维度对现有方法进行了系统性的划分。与现有综述相比,该框架更加全面和细致,能够更好地反映LLM在立场检测中的应用现状。此外,论文还对不同类别的方法进行了详细的分析和比较,为研究人员提供了更深入的理解。
关键设计:论文的关键设计在于分类框架的构建。具体来说,学习方法维度包括监督、无监督、少样本和零样本学习;数据模态维度包括单模态、多模态和混合模态;目标关系维度包括目标内、跨目标和多目标场景。这些维度的选择是基于对现有研究的深入分析,能够较好地反映LLM在立场检测中的应用特点。
🖼️ 关键图片
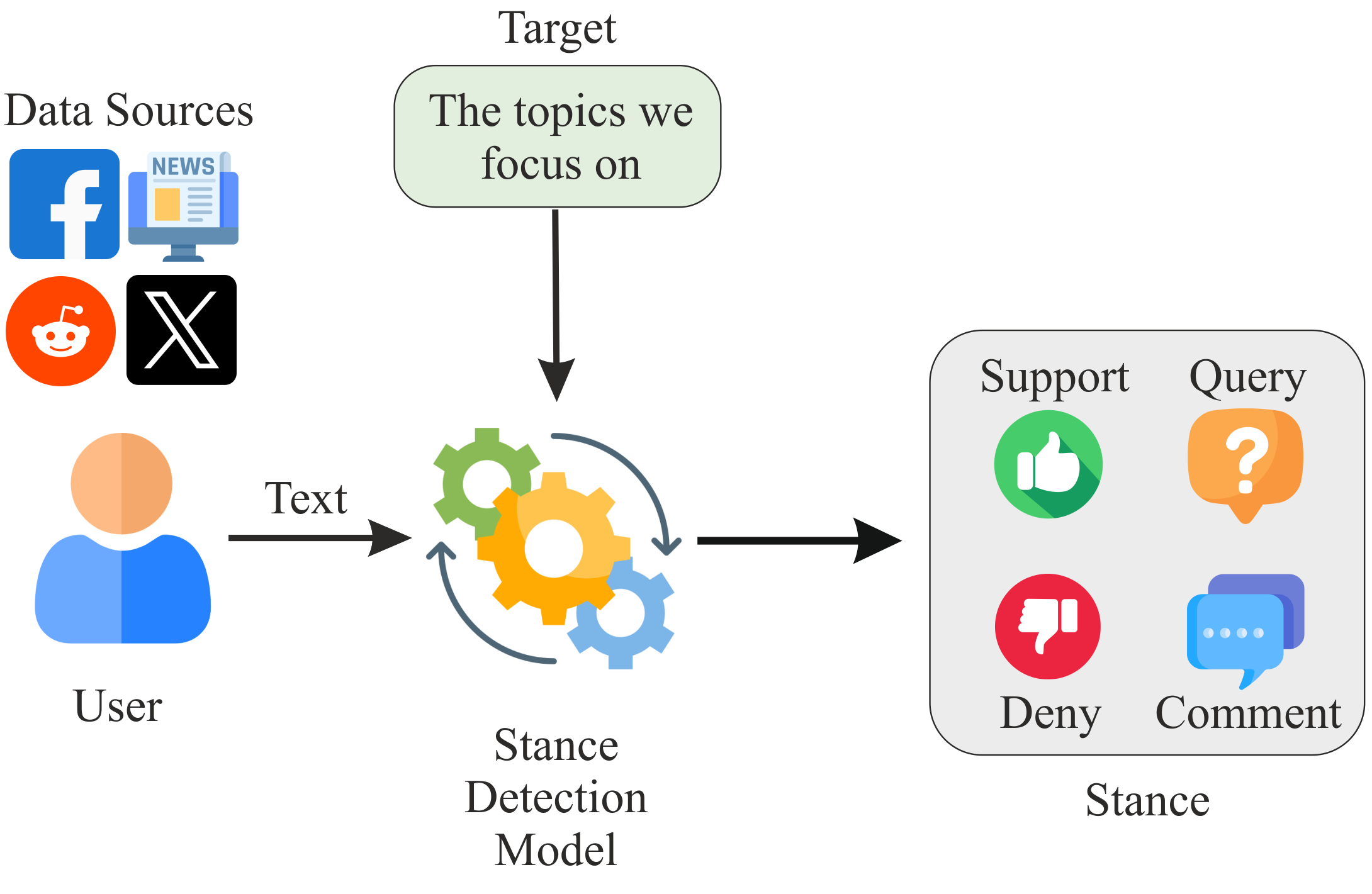

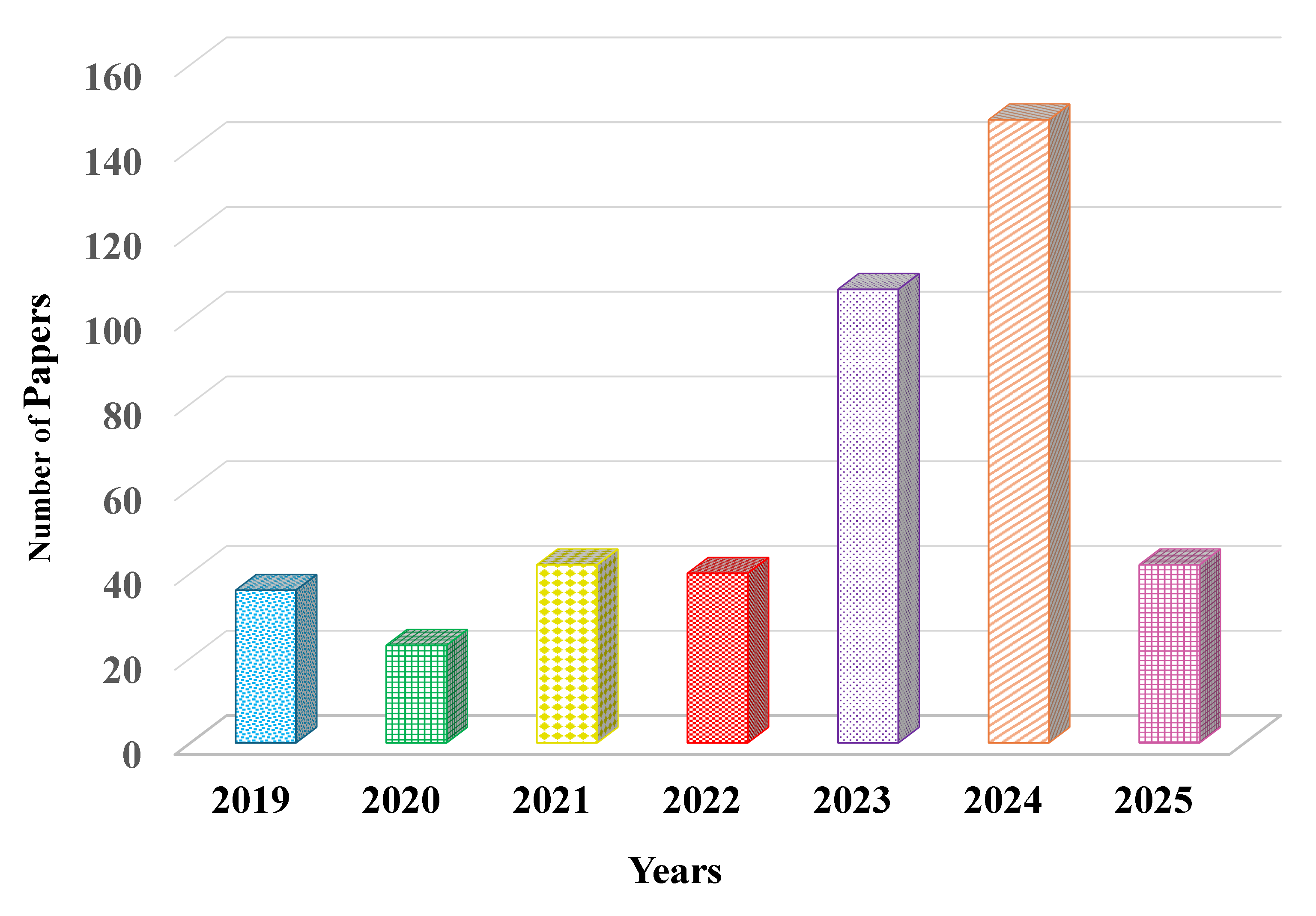
📊 实验亮点
该综述论文系统地分析了大型语言模型在立场检测领域的应用,并提出了一个新颖的分类框架,涵盖了学习方法、数据模态和目标关系三个维度。通过对现有方法的详细分析和比较,论文总结了不同方法的优势和局限性,并指出了未来研究的潜在方向。该研究为研究人员和从业人员提供了一个全面的视角,了解LLM在立场检测中的应用现状、挑战和未来方向。
🎯 应用场景
该研究成果可应用于多个领域,包括:1) 错误信息检测,帮助识别和过滤社交媒体上的虚假信息;2) 政治分析,分析公众对政治事件和人物的立场;3) 公共健康监测,了解公众对健康政策和疫苗接种的看法;4) 社交媒体管理,自动识别和处理仇恨言论和不当内容。该研究有助于提高信息过滤的准确性和效率,为决策提供更可靠的依据。
📄 摘要(原文)
Stance detection is essential for understanding subjective content across various platforms such as social media, news articles, and online reviews. Recent advances in Large Language Models (LLMs) have revolutionized stance detection by introducing novel capabilities in contextual understanding, cross-domain generalization, and multimodal analysis. Despite these progressions, existing surveys often lack comprehensive coverage of approaches that specifically leverage LLMs for stance detection. To bridge this critical gap, our review article conducts a systematic analysis of stance detection, comprehensively examining recent advancements of LLMs transforming the field, including foundational concepts, methodologies, datasets, applications, and emerging challenges. We present a novel taxonomy for LLM-based stance detection approaches, structured along three key dimensions: 1) learning methods, including supervised, unsupervised, few-shot, and zero-shot; 2) data modalities, such as unimodal, multimodal, and hybrid; and 3) target relationships, encompassing in-target, cross-target, and multi-target scenarios. Furthermore, we discuss the evaluation techniques and analyze benchmark datasets and performance trends, highlighting the strengths and limitations of different architectures. Key applications in misinformation detection, political analysis, public health monitoring, and social media moderation are discussed. Finally, we identify critical challenges such as implicit stance expression, cultural biases, and computational constraints, while outlining promising future directions, including explainable stance reasoning, low-resource adaptation, and real-time deployment frameworks. Our survey highlights emerging trends, open challenges, and future directions to guide researchers and practitioners in developing next-generation stance detection systems powered by large language models.