Evaluating the Effectiveness of Black-Box Prompt Optimization as the Scale of LLMs Continues to Grow
作者: Ziyu Zhou, Yihang Wu, Jingyuan Yang, Zhan Xiao, Rongjun Li
分类: cs.CL
发布日期: 2025-05-13
💡 一句话要点
评估黑盒提示优化方法在大规模LLM上的有效性,发现其收益递减
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示优化 黑盒优化 反向缩放 自然语言处理
📋 核心要点
- 现有黑盒提示优化方法主要针对小规模LLM,在大规模LLM上的有效性未知。
- 论文研究黑盒提示优化方法在超大规模LLM上的性能,并探究模型规模的影响。
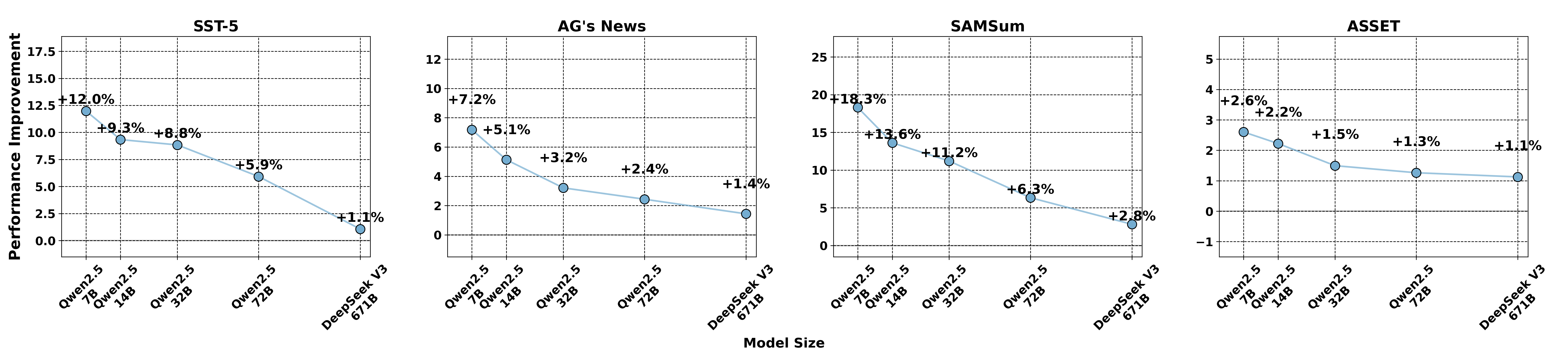
- 实验表明,黑盒提示优化方法在大规模LLM上的收益有限,并存在反向缩放规律。
📝 摘要(中文)
黑盒提示优化方法作为一种改进输入提示以更好对齐大型语言模型(LLMs)的策略,已被广泛研究并取得了令人鼓舞的结果。然而,现有研究主要集中在较小规模的模型(如7B、14B)或早期版本的LLM(如GPT-3.5)上。随着LLM规模的持续增长,例如DeepSeek V3 (671B),这些黑盒优化技术是否能继续为如此规模的模型带来显著的性能提升仍然是一个悬而未决的问题。为了解决这个问题,我们选择了三种著名的黑盒优化方法,并在四个NLU和NLG数据集上评估它们在大型LLM(DeepSeek V3和Gemini 2.0 Flash)上的表现。结果表明,这些黑盒提示优化方法对这些大型LLM的改进有限。此外,我们假设模型规模是导致观察到的收益有限的主要因素。为了验证这一假设,我们对不同规模的LLM(Qwen 2.5系列,从7B到72B)进行了实验,并观察到一种反向缩放规律,即黑盒优化方法的有效性随着模型规模的增加而降低。
🔬 方法详解
问题定义:论文旨在研究现有的黑盒提示优化方法在超大规模语言模型(LLMs)上的有效性。现有方法主要针对较小规模的LLM进行优化,而随着模型规模的增长,这些方法是否仍然有效是一个未解决的问题。现有方法的痛点在于,它们可能无法充分利用超大规模LLM的潜力,或者可能因为模型规模的增加而导致优化效果下降。
核心思路:论文的核心思路是通过实验评估黑盒提示优化方法在不同规模LLM上的性能,并分析模型规模对优化效果的影响。通过对比不同规模模型的优化结果,论文旨在揭示黑盒提示优化方法与模型规模之间的关系,并验证是否存在反向缩放规律。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择三种具有代表性的黑盒提示优化方法;2) 在四个NLU和NLG数据集上评估这些方法在不同规模LLM上的性能,包括DeepSeek V3 (671B), Gemini 2.0 Flash, 和 Qwen 2.5系列 (7B-72B);3) 分析实验结果,对比不同规模模型的优化效果,并验证是否存在反向缩放规律。
关键创新:论文最重要的技术创新点在于发现了黑盒提示优化方法在超大规模LLM上存在反向缩放规律。这意味着随着模型规模的增加,黑盒提示优化方法的有效性会降低。这一发现挑战了以往的研究结果,并为未来的提示优化研究提供了新的方向。
关键设计:论文的关键设计包括:1) 选择了三种常用的黑盒提示优化方法,保证了实验结果的代表性;2) 选择了不同规模的LLM,以便研究模型规模对优化效果的影响;3) 选择了四个不同的NLU和NLG数据集,以评估优化方法在不同任务上的泛化能力。论文没有详细说明具体的参数设置、损失函数或网络结构,因为重点在于评估现有方法的有效性,而不是提出新的优化方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,黑盒提示优化方法在DeepSeek V3和Gemini 2.0 Flash等大型LLM上的改进有限。更重要的是,论文发现了反向缩放规律,即黑盒优化方法的有效性随着模型规模的增加而降低。例如,在Qwen 2.5系列模型上,7B模型的优化效果明显优于72B模型。这些发现表明,对于超大规模LLM,需要重新思考提示优化策略。
🎯 应用场景
该研究结果对LLM的应用具有重要意义。它表明,对于超大规模LLM,简单的黑盒提示优化可能不再有效,需要开发更有效的优化策略。这有助于更好地利用超大规模LLM的潜力,提高其在各种自然语言处理任务中的性能,例如机器翻译、文本摘要、问答系统等。未来的研究可以探索更复杂的提示优化方法,或者结合模型微调等技术,以进一步提高超大规模LLM的性能。
📄 摘要(原文)
Black-Box prompt optimization methods have emerged as a promising strategy for refining input prompts to better align large language models (LLMs), thereby enhancing their task performance. Although these methods have demonstrated encouraging results, most studies and experiments have primarily focused on smaller-scale models (e.g., 7B, 14B) or earlier versions (e.g., GPT-3.5) of LLMs. As the scale of LLMs continues to increase, such as with DeepSeek V3 (671B), it remains an open question whether these black-box optimization techniques will continue to yield significant performance improvements for models of such scale. In response to this, we select three well-known black-box optimization methods and evaluate them on large-scale LLMs (DeepSeek V3 and Gemini 2.0 Flash) across four NLU and NLG datasets. The results show that these black-box prompt optimization methods offer only limited improvements on these large-scale LLMs. Furthermore, we hypothesize that the scale of the model is the primary factor contributing to the limited benefits observed. To explore this hypothesis, we conducted experiments on LLMs of varying sizes (Qwen 2.5 series, ranging from 7B to 72B) and observed an inverse scaling law, wherein the effectiveness of black-box optimization methods diminished as the model size increased.