Concept-Level Explainability for Auditing & Steering LLM Responses
作者: Kenza Amara, Rita Sevastjanova, Mennatallah El-Assady
分类: cs.CL, cs.AI
发布日期: 2025-05-12 (更新: 2025-05-19)
备注: 9 pages, 7 figures, Submission to Neurips 2025
💡 一句话要点
提出ConceptX,通过概念级解释性实现LLM响应的审核与引导。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM解释性 概念级归因 安全性审计 偏见缓解 行为引导 提示工程 语义相似度
📋 核心要点
- 现有token级别归因方法在解释LLM生成文本时,难以捕捉整体语义,缺乏上下文感知。
- ConceptX通过识别提示中的关键概念,并根据输出语义相似性赋予其重要性,实现概念级解释。
- 实验表明,ConceptX在忠实性、人类对齐方面优于token级别方法,并有效提升了LLM的安全性和对齐性。
📝 摘要(中文)
随着大型语言模型(LLMs)的广泛部署,对其安全性和对齐的担忧日益增加。一种引导LLM行为的方法,例如减轻偏见或防御越狱攻击,是识别提示中哪些部分影响了模型输出的特定方面。Token级别的归因方法提供了一个有希望的解决方案,但仍然在文本生成方面存在困难,它分别解释输出中每个token的存在,而不是整个LLM响应的潜在语义。我们引入ConceptX,一种模型无关的概念级解释性方法,它识别提示中的概念,即语义丰富的token,并根据输出的语义相似性为它们分配重要性。与当前的token级别方法不同,ConceptX还提供通过就地token替换来保持上下文完整性,并支持灵活的解释目标,例如性别偏见。ConceptX能够进行审核,通过揭示偏见的来源,以及引导,通过修改提示来改变情感或降低LLM响应的有害性,而无需重新训练。在三个LLM上,ConceptX在忠实性和人类对齐方面都优于token级别的方法,如TokenSHAP。引导任务的情感转移提升了0.252,而随机编辑为0.131,并且攻击成功率从0.463降低到0.242,优于归因和释义基线。虽然提示工程和自我解释方法有时会产生更安全的回应,但ConceptX提供了一种透明且忠实的替代方案,用于提高LLM的安全性和对齐性,证明了基于归因的解释性在指导LLM行为方面的实际价值。
🔬 方法详解
问题定义:现有token级别的归因方法在解释LLM生成文本时,主要痛点在于无法捕捉到token之间的语义关联,导致解释结果缺乏整体性和上下文感知。此外,这些方法通常难以直接用于引导LLM的行为,例如减轻偏见或防御恶意攻击。
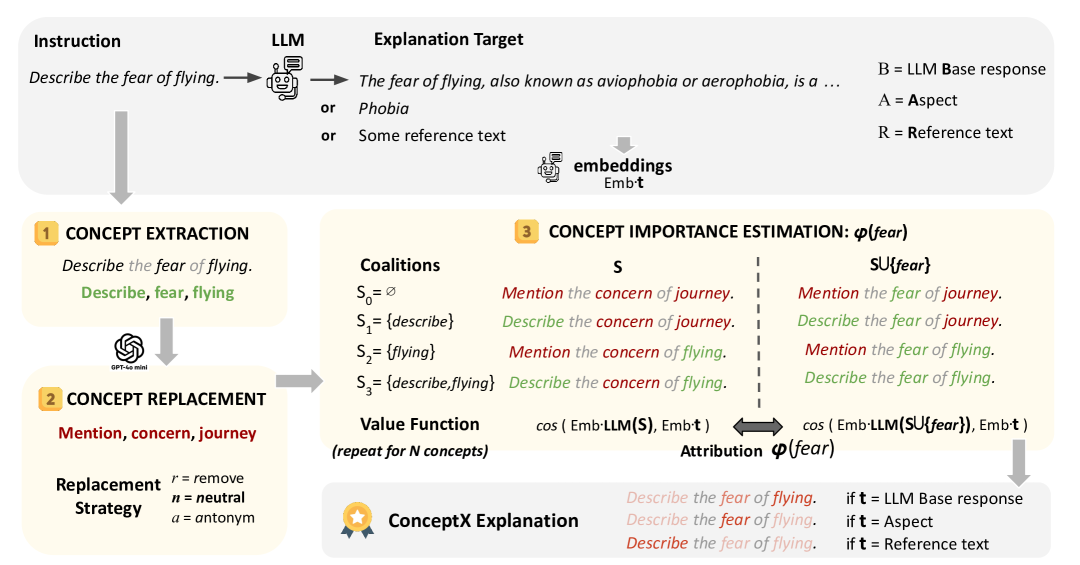
核心思路:ConceptX的核心思路是将解释粒度从token级别提升到概念级别。通过识别提示中的关键概念(即语义丰富的token),并根据这些概念对LLM输出的影响程度进行重要性排序,从而提供更具语义性和可操作性的解释。这种方法能够更好地理解LLM的推理过程,并为引导LLM行为提供更有效的手段。
技术框架:ConceptX的整体框架包括以下几个主要阶段:1) 概念识别:识别提示文本中具有重要语义信息的token,作为候选概念。2) 概念替换:通过就地替换候选概念,生成多个修改后的提示。3) LLM推理:使用原始提示和修改后的提示,分别输入LLM进行推理,得到相应的输出。4) 语义相似度计算:计算原始输出和修改后输出之间的语义相似度,衡量每个概念对输出的影响程度。5) 重要性排序:根据语义相似度差异,对概念进行重要性排序,得到概念级别的解释结果。
关键创新:ConceptX最重要的技术创新点在于其概念级别的解释框架。与传统的token级别方法相比,ConceptX能够更好地捕捉token之间的语义关联,提供更具语义性和可操作性的解释结果。此外,ConceptX还支持就地token替换,保持上下文完整性,并支持灵活的解释目标,例如性别偏见。
关键设计:ConceptX的关键设计包括:1) 概念识别策略:可以使用不同的方法来识别提示中的概念,例如基于词性标注、命名实体识别或预训练语言模型。2) 语义相似度度量:可以使用不同的语义相似度度量方法,例如余弦相似度、BERTScore或Sentence-BERT。3) 重要性评分函数:根据语义相似度差异,计算每个概念的重要性得分。具体实现细节未在论文中详细说明,可能需要根据具体应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
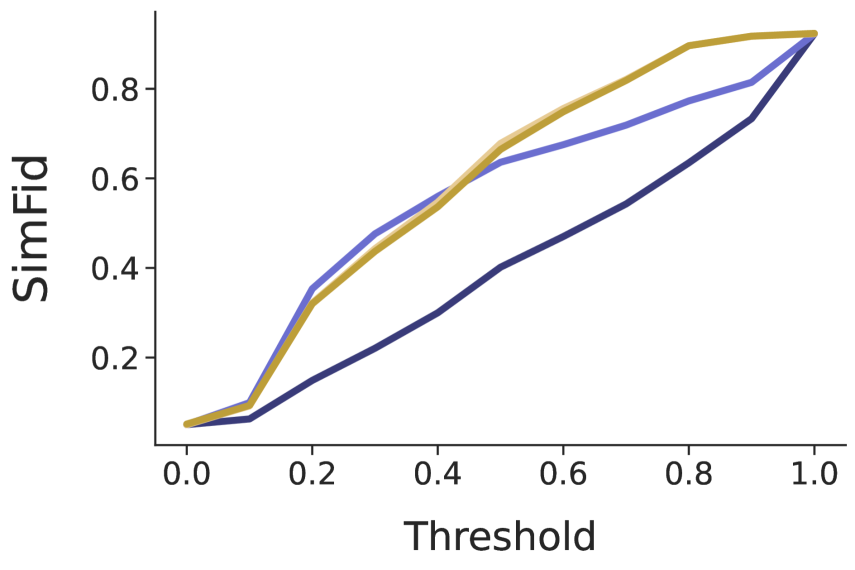
ConceptX在三个LLM上的实验结果表明,其在忠实性和人类对齐方面均优于token级别的TokenSHAP方法。在引导任务中,ConceptX使情感转移提升了0.252,而随机编辑仅为0.131。此外,ConceptX还将攻击成功率从0.463降低到0.242,优于归因和释义基线。
🎯 应用场景
ConceptX可应用于LLM的安全性审计、偏见缓解和行为引导。例如,可以利用ConceptX识别提示中导致有害输出的关键概念,并修改提示以降低LLM的攻击成功率。此外,ConceptX还可以用于提高LLM的透明度和可信度,帮助用户更好地理解LLM的推理过程。
📄 摘要(原文)
As large language models (LLMs) become widely deployed, concerns about their safety and alignment grow. An approach to steer LLM behavior, such as mitigating biases or defending against jailbreaks, is to identify which parts of a prompt influence specific aspects of the model's output. Token-level attribution methods offer a promising solution, but still struggle in text generation, explaining the presence of each token in the output separately, rather than the underlying semantics of the entire LLM response. We introduce ConceptX, a model-agnostic, concept-level explainability method that identifies the concepts, i.e., semantically rich tokens in the prompt, and assigns them importance based on the outputs' semantic similarity. Unlike current token-level methods, ConceptX also offers to preserve context integrity through in-place token replacements and supports flexible explanation goals, e.g., gender bias. ConceptX enables both auditing, by uncovering sources of bias, and steering, by modifying prompts to shift the sentiment or reduce the harmfulness of LLM responses, without requiring retraining. Across three LLMs, ConceptX outperforms token-level methods like TokenSHAP in both faithfulness and human alignment. Steering tasks boost sentiment shift by 0.252 versus 0.131 for random edits and lower attack success rates from 0.463 to 0.242, outperforming attribution and paraphrasing baselines. While prompt engineering and self-explaining methods sometimes yield safer responses, ConceptX offers a transparent and faithful alternative for improving LLM safety and alignment, demonstrating the practical value of attribution-based explainability in guiding LLM behavior.