Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
作者: Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, Junyang Lin
分类: cs.CL
发布日期: 2025-05-10
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出门控注意力机制,提升大语言模型非线性、稀疏性和长文本外推能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 门控注意力 大语言模型 注意力机制 长文本处理 稀疏性 非线性 注意力沉没
📋 核心要点
- 现有工作对门控机制在Transformer中的作用研究不足,缺乏系统性的分析。
- 提出一种简单的门控注意力机制,在缩放点积注意力后应用特定头的Sigmoid门控。
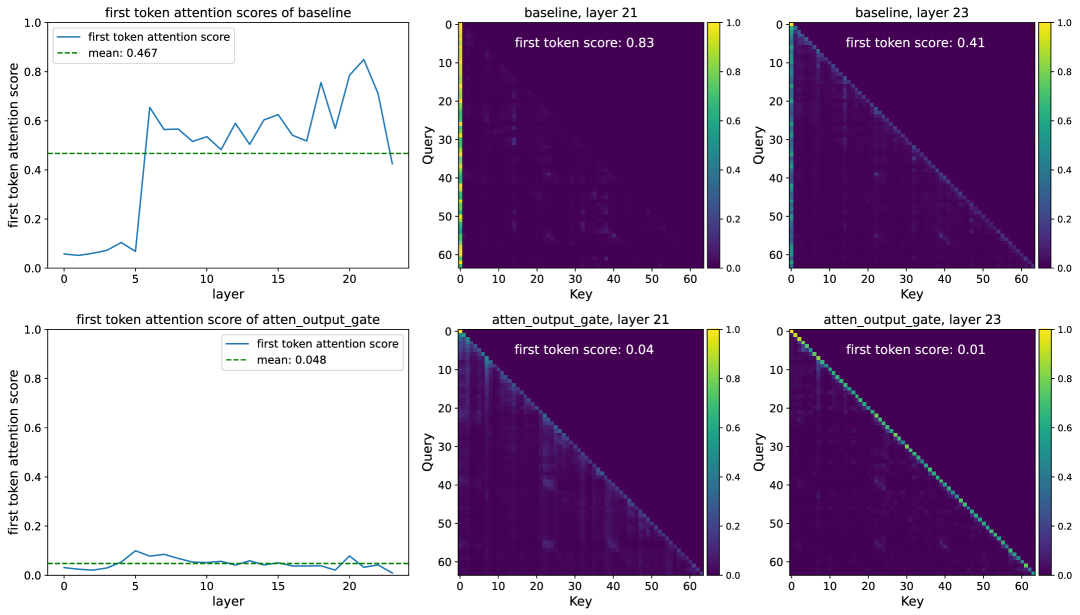
- 实验表明,该方法提升了模型性能、训练稳定性和长文本外推能力,并缓解了注意力沉没问题。
📝 摘要(中文)
本文深入研究了门控机制对softmax注意力变体的具体影响。通过对30个150亿参数的混合专家模型和17亿参数的稠密模型进行全面比较,这些模型均在3.5万亿token的数据集上训练。研究发现,在缩放点积注意力(SDPA)之后应用特定于头的sigmoid门控,能够持续提升性能,增强训练稳定性,容忍更大的学习率,并改善缩放特性。通过比较不同的门控位置和计算变体,作者将这种有效性归因于两个关键因素:在softmax注意力中的低秩映射上引入非线性,以及应用依赖于查询的稀疏门控分数来调节SDPA输出。值得注意的是,这种稀疏门控机制缓解了“注意力沉没”问题,并增强了长文本外推性能。作者开源了相关代码和模型,以促进未来的研究。
🔬 方法详解
问题定义:现有的大语言模型,特别是基于Transformer的模型,在处理长文本时容易出现“注意力沉没”问题,即模型倾向于关注少数几个token,而忽略其他token,导致信息丢失。此外,如何有效地引入非线性以及提升模型的稀疏性也是一个挑战。
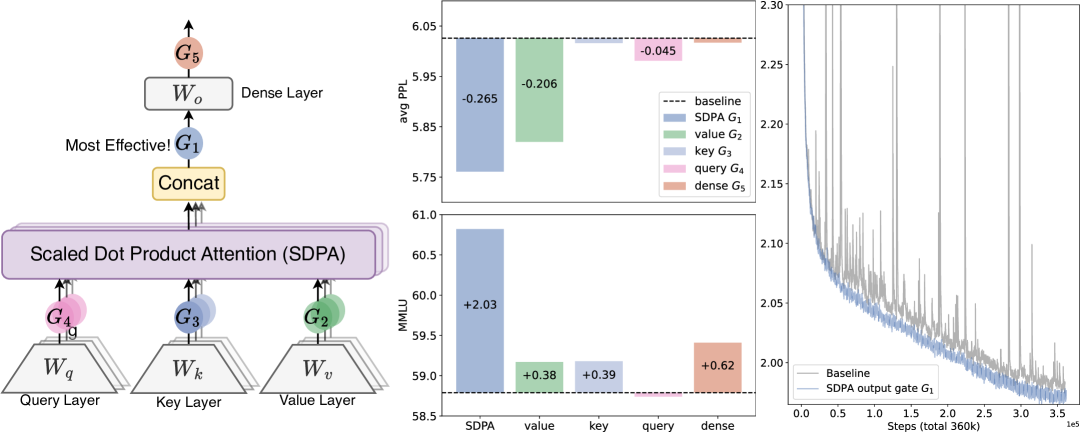
核心思路:论文的核心思路是在缩放点积注意力(SDPA)之后,引入一个特定于头的sigmoid门控。这个门控的作用是引入非线性,并根据查询(query)动态地调整每个头的输出,从而实现稀疏的注意力机制。这种设计旨在缓解注意力沉没问题,并提升模型对长文本的处理能力。
技术框架:该方法基于标准的Transformer架构,主要修改在于注意力机制部分。在计算出缩放点积注意力之后,不是直接将结果输入到后续层,而是先通过一个sigmoid门控。这个门控的输入是SDPA的输出,输出是一个介于0和1之间的值,用于调节SDPA的输出。整个流程可以概括为:Query, Key, Value -> Scaled Dot-Product Attention -> Sigmoid Gate -> Output。
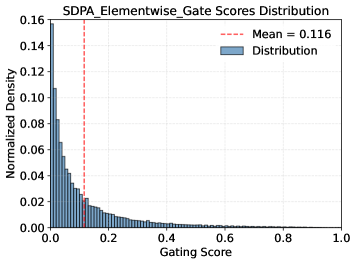
关键创新:该方法最重要的创新点在于引入了查询依赖的稀疏门控机制。与传统的注意力机制不同,该方法不是对所有token都给予相同的关注,而是根据查询动态地调整每个头的注意力权重,从而实现稀疏的注意力。这种稀疏性有助于缓解注意力沉没问题,并提升模型对长文本的处理能力。
关键设计:关键设计包括:1) 门控的位置:在SDPA之后应用门控。2) 门控的类型:使用sigmoid函数作为门控。3) 门控的输入:SDPA的输出作为门控的输入。4) 损失函数:使用标准的语言模型损失函数。5) 模型规模:实验使用了150亿参数的混合专家模型和17亿参数的稠密模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在3.5万亿token的数据集上训练后,应用门控注意力机制的150亿参数混合专家模型和17亿参数稠密模型均取得了性能提升。该方法还增强了训练稳定性,允许使用更大的学习率,并改善了模型的缩放特性。此外,该方法有效地缓解了“注意力沉没”问题,并提升了长文本外推性能。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的自然语言处理任务,例如文档摘要、机器翻译、问答系统等。通过缓解注意力沉没问题,该方法可以提升模型在长文本上的性能,从而提高这些应用的准确性和效率。此外,该方法还可以促进更大规模语言模型的训练和部署。
📄 摘要(原文)
Gating mechanisms have been widely utilized, from early models like LSTMs and Highway Networks to recent state space models, linear attention, and also softmax attention. Yet, existing literature rarely examines the specific effects of gating. In this work, we conduct comprehensive experiments to systematically investigate gating-augmented softmax attention variants. Specifically, we perform a comprehensive comparison over 30 variants of 15B Mixture-of-Experts (MoE) models and 1.7B dense models trained on a 3.5 trillion token dataset. Our central finding is that a simple modification-applying a head-specific sigmoid gate after the Scaled Dot-Product Attention (SDPA)-consistently improves performance. This modification also enhances training stability, tolerates larger learning rates, and improves scaling properties. By comparing various gating positions and computational variants, we attribute this effectiveness to two key factors: (1) introducing non-linearity upon the low-rank mapping in the softmax attention, and (2) applying query-dependent sparse gating scores to modulate the SDPA output. Notably, we find this sparse gating mechanism mitigates 'attention sink' and enhances long-context extrapolation performance, and we also release related $\href{https://github.com/qiuzh20/gated_attention}{codes}$ and $\href{https://huggingface.co/QwQZh/gated_attention}{models}$ to facilitate future research.