Integrating Video and Text: A Balanced Approach to Multimodal Summary Generation and Evaluation
作者: Galann Pennec, Zhengyuan Liu, Nicholas Asher, Philippe Muller, Nancy F. Chen
分类: cs.CL, cs.CV
发布日期: 2025-05-10 (更新: 2025-10-31)
💡 一句话要点
提出一种平衡视频与文本的多模态摘要生成与评估方法,提升视觉信息相关性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态摘要 视频摘要 视觉-语言模型 零样本学习 剧本生成 多模态评估 长视频理解
📋 核心要点
- 现有视觉-语言模型在处理长视频等多模态输入时,难以有效平衡视觉和文本信息,导致摘要质量下降。
- 该论文提出一种零样本方法,通过构建剧本表示,整合视频关键帧、对话和角色信息,生成更全面的摘要。
- 实验结果表明,该方法在包含更多相关视觉信息的同时,显著减少了所需的视频输入量,并在多模态评估指标上优于现有方法。
📝 摘要(中文)
视觉-语言模型(VLMs)在总结复杂的多模态输入(如完整的电视剧集)时,常常难以平衡视觉和文本信息。本文提出了一种零样本视频到文本的摘要生成方法,该方法构建剧集的剧本表示,有效地将关键视频时刻、对话和角色信息整合到一个统一的文档中。与以往方法不同,我们仅使用音频、视频和文本记录作为输入,同时以零样本方式生成剧本并识别角色。此外,我们强调现有的摘要评估指标可能无法评估摘要中的多模态内容。为此,我们引入了MFactSum,一种多模态指标,用于评估摘要在视觉和文本模态方面的质量。使用MFactSum,我们在SummScreen3D数据集上评估了我们的剧本摘要,结果表明,与Gemini 1.5等最先进的VLM相比,我们的方法生成的摘要包含多20%的相关视觉信息,同时仅需输入75%的视频。
🔬 方法详解
问题定义:现有视觉-语言模型在处理长视频摘要任务时,面临着视觉和文本信息融合困难的问题。传统的摘要评估指标也难以准确衡量多模态摘要的质量,无法有效反映视觉信息的相关性。
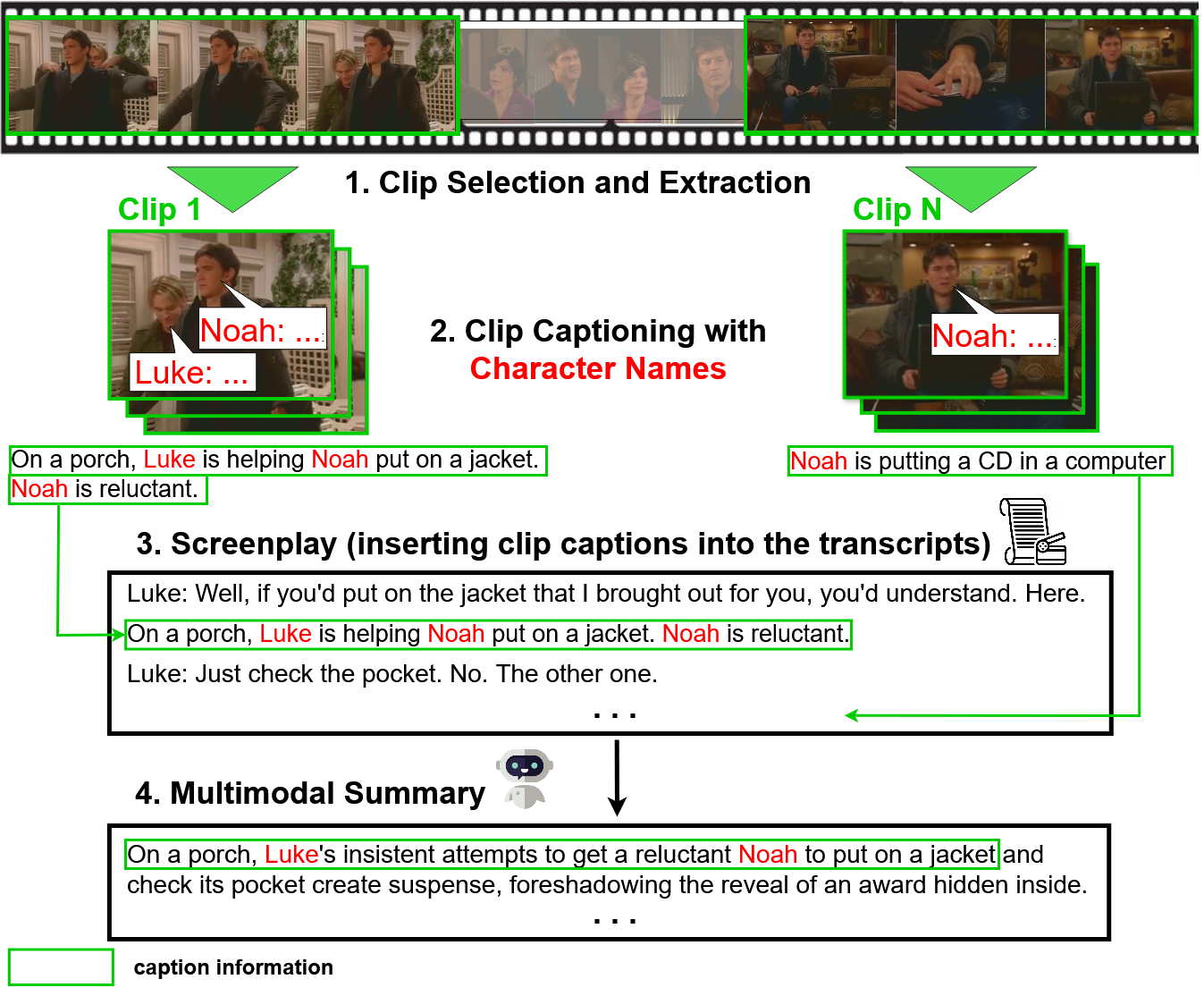
核心思路:该论文的核心思路是构建一个中间表示——剧本,将视频的关键帧、对话和角色信息整合到一起,从而更好地利用视觉信息。同时,设计新的多模态评估指标,更准确地评估摘要的质量。
技术框架:该方法主要包含两个阶段:一是剧本生成阶段,利用音频、视频和文本记录,以零样本方式生成剧本并识别角色。二是摘要生成阶段,利用生成的剧本作为输入,生成最终的摘要。同时,论文还提出了新的多模态评估指标MFactSum。
关键创新:该方法的主要创新点在于:1) 提出了一种新的剧本表示方法,能够有效地整合视频和文本信息。2) 提出了一种新的多模态评估指标MFactSum,能够更准确地评估摘要的质量。3) 实现了零样本的剧本生成和角色识别。
关键设计:剧本生成模块的具体实现细节未知,但根据摘要描述,其关键在于如何有效地从音频、视频和文本记录中提取关键信息,并将其整合到剧本中。MFactSum指标的设计也至关重要,需要能够准确衡量摘要在视觉和文本模态方面的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在SummScreen3D数据集上优于现有的最先进的VLM模型,如Gemini 1.5。具体来说,该方法生成的摘要包含多20%的相关视觉信息,同时仅需输入75%的视频。使用提出的MFactSum指标进行评估,也显示了该方法的优越性。
🎯 应用场景
该研究成果可应用于视频内容理解、智能视频编辑、影视剧内容分析等领域。例如,可以用于自动生成影视剧的剧情梗概、角色介绍,或者用于智能剪辑,提取视频中的关键片段。未来,该技术有望在教育、娱乐、新闻等领域发挥重要作用。
📄 摘要(原文)
Vision-Language Models (VLMs) often struggle to balance visual and textual information when summarizing complex multimodal inputs, such as entire TV show episodes. In this paper, we propose a zero-shot video-to-text summarization approach that builds its own screenplay representation of an episode, effectively integrating key video moments, dialogue, and character information into a unified document. Unlike previous approaches, we simultaneously generate screenplays and name the characters in zero-shot, using only the audio, video, and transcripts as input. Additionally, we highlight that existing summarization metrics can fail to assess the multimodal content in summaries. To address this, we introduce MFactSum, a multimodal metric that evaluates summaries with respect to both vision and text modalities. Using MFactSum, we evaluate our screenplay summaries on the SummScreen3D dataset, demonstrating superiority against state-of-the-art VLMs such as Gemini 1.5 by generating summaries containing 20% more relevant visual information while requiring 75% less of the video as input.