A Scaling Law for Token Efficiency in LLM Fine-Tuning Under Fixed Compute Budgets
作者: Ryan Lagasse, Aidan Kierans, Avijit Ghosh, Shiri Dori-Hacohen
分类: cs.CL, cs.AI
发布日期: 2025-05-09 (更新: 2025-06-02)
💡 一句话要点
提出一种考虑数据构成的LLM微调缩放律,提升固定计算资源下的token效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 缩放律 数据构成 token效率
📋 核心要点
- 现有LLM微调方法仅关注总token数,忽略了数据集容量(样本数量和平均token长度)对模型性能的关键影响。
- 论文提出一种新的缩放律,显式地将数据集容量纳入考虑,以优化固定计算预算下的LLM微调。
- 实验表明,数据构成显著影响token效率,验证了新缩放律的有效性,为资源受限场景下的LLM微调提供了指导。
📝 摘要(中文)
本文提出了一种在固定计算预算下微调大型语言模型(LLM)的缩放律,该缩放律明确考虑了数据的构成。传统方法仅通过总token数来衡量训练数据,但样本数量及其平均token长度(我们称之为“数据集容量”)在模型性能中起着决定性作用。我们的公式遵循既定程序进行调整。在BRICC数据集和MMLU数据集子集上的实验,以及在多种子采样策略下的评估表明,数据构成显著影响token效率。这些结果推动了在资源受限环境中进行实际LLM微调的改进缩放律。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的微调方法通常只关注训练数据的总token数量,而忽略了数据集的构成,即样本的数量以及每个样本的平均token长度。这种忽略导致在固定计算资源下,token效率低下,无法充分利用训练数据提升模型性能。尤其是在资源受限的场景下,如何更有效地利用有限的计算资源进行LLM微调是一个重要的挑战。
核心思路:论文的核心思路是,数据集的构成(样本数量和平均token长度)对LLM微调的性能有显著影响。因此,在设计缩放律时,需要将数据集容量纳入考虑,而不仅仅是总token数。通过优化数据集的构成,可以在固定计算预算下,提升token效率,从而提高模型性能。
技术框架:该研究主要通过实验分析来验证提出的缩放律。首先,选择合适的LLM模型和数据集(BRICC和MMLU的子集)。然后,设计不同的子采样策略,改变数据集的构成(样本数量和平均token长度),并在固定计算预算下进行微调。最后,评估微调后的模型性能,分析数据构成对token效率的影响,并据此调整缩放律的参数。
关键创新:论文的关键创新在于,提出了一个考虑数据构成的LLM微调缩放律。与现有方法相比,该缩放律不仅考虑了总token数,还显式地考虑了数据集容量(样本数量和平均token长度)。这种改进使得缩放律更加贴合实际的LLM微调场景,尤其是在资源受限的情况下,可以更好地指导数据选择和模型训练。
关键设计:论文的关键设计在于如何量化数据集的构成,并将其纳入缩放律中。具体的技术细节包括:如何定义和计算数据集容量(样本数量乘以平均token长度),如何选择合适的子采样策略来改变数据集的构成,以及如何调整缩放律的参数,以反映数据构成对token效率的影响。此外,实验中使用的具体模型架构、优化器、学习率等超参数设置也会影响最终结果。
🖼️ 关键图片
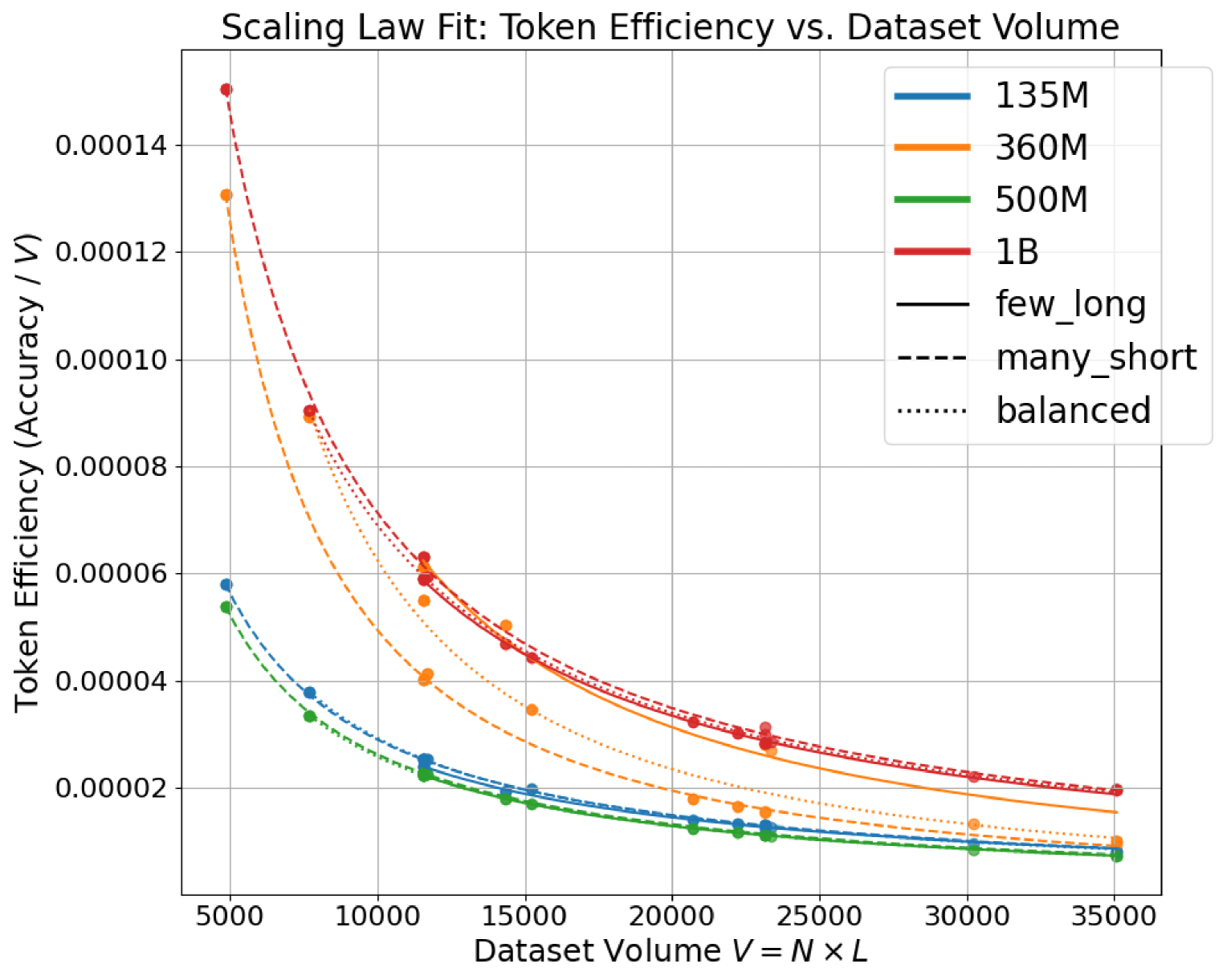
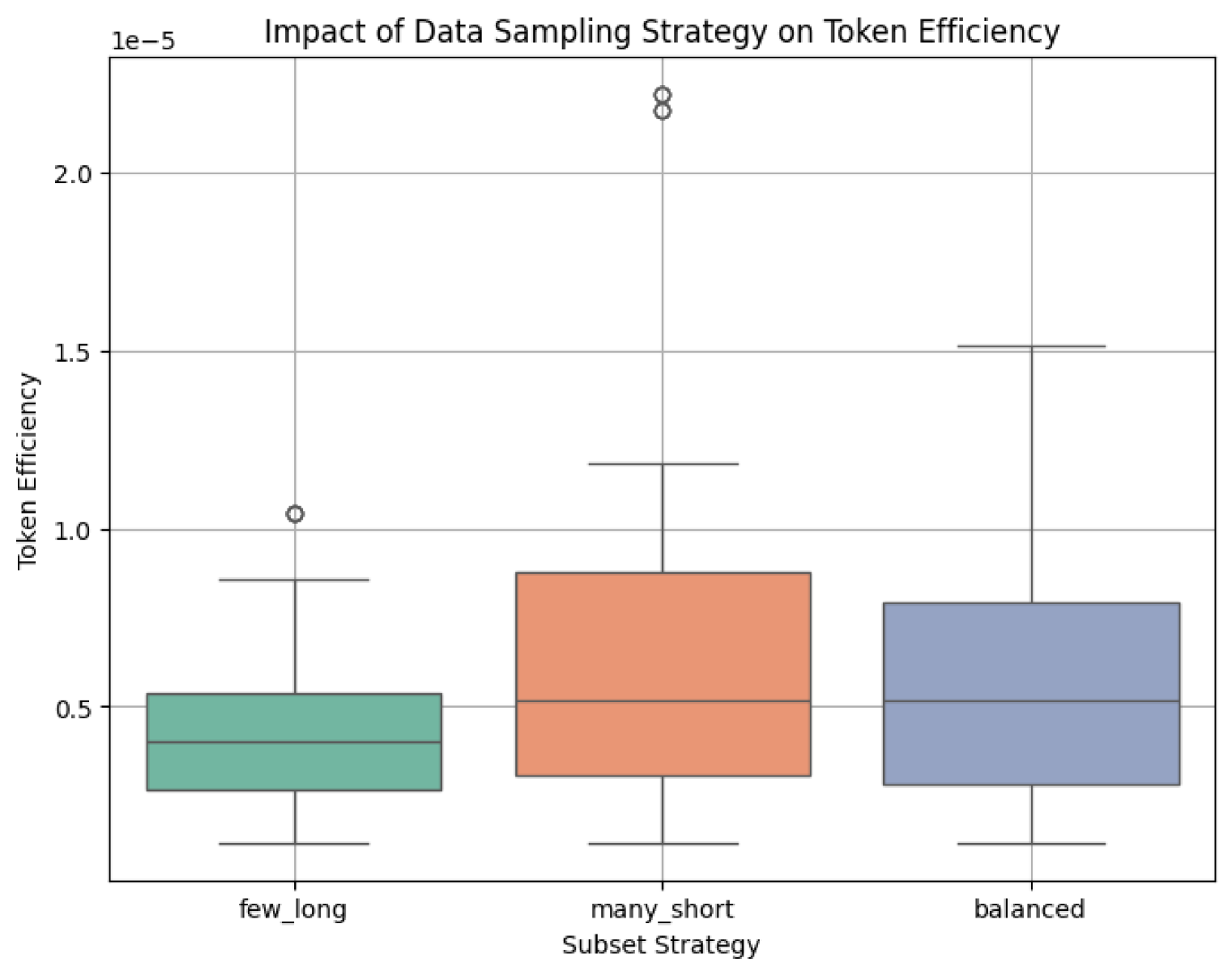
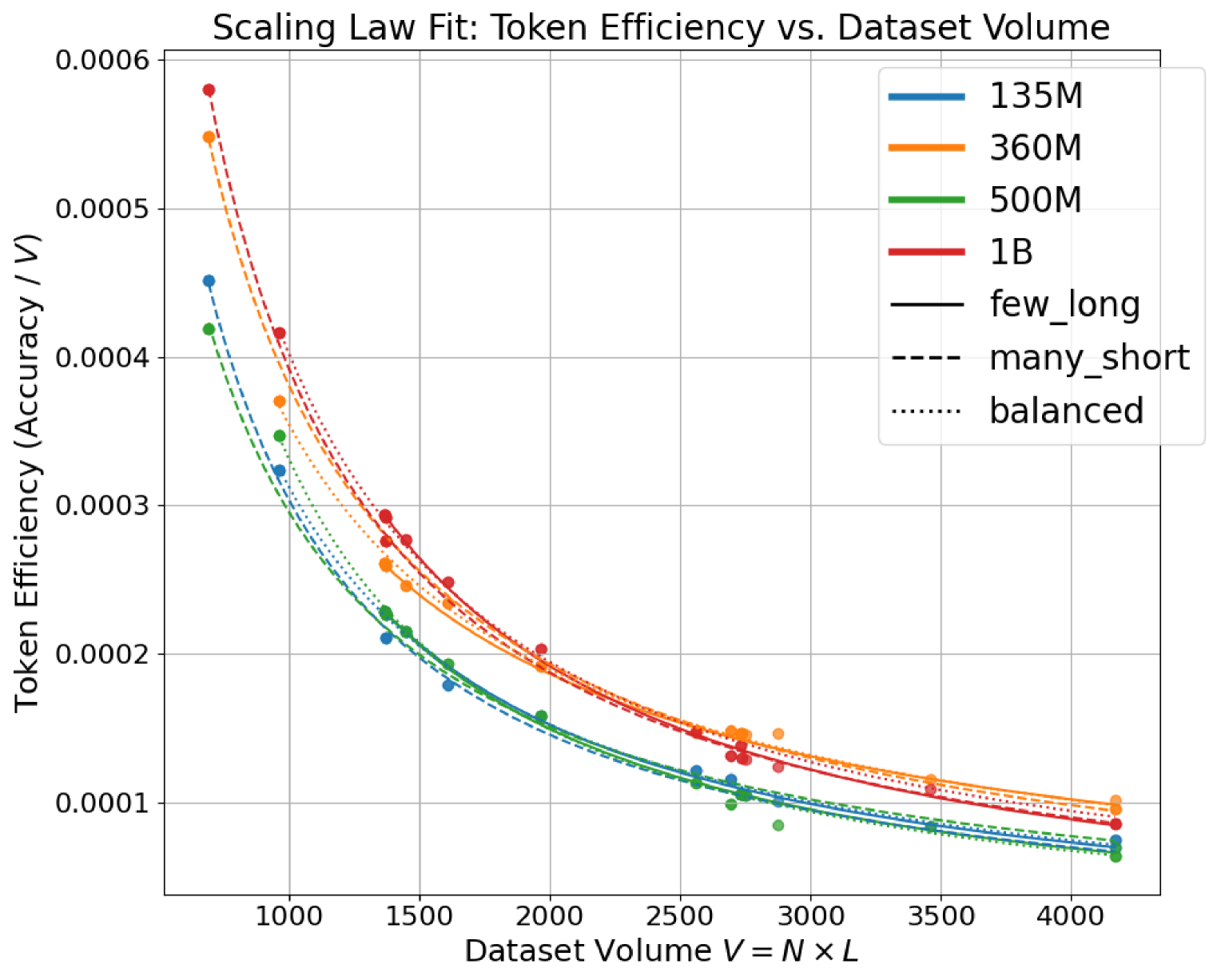
📊 实验亮点
实验结果表明,数据构成对token效率有显著影响。通过调整数据集的构成,可以在固定计算预算下提升模型性能。例如,在BRICC和MMLU数据集上的实验表明,与传统方法相比,使用考虑数据构成的缩放律进行微调,可以在相同的计算资源下获得更高的模型准确率。具体的性能提升幅度取决于数据集和模型,但总体趋势是,优化数据构成可以显著提升token效率。
🎯 应用场景
该研究成果可应用于各种需要对LLM进行微调的场景,尤其是在计算资源有限的情况下。例如,在移动设备或边缘设备上部署LLM时,可以利用该缩放律优化训练数据的选择,以在有限的计算资源下获得最佳的模型性能。此外,该研究还可以指导数据集的构建,帮助研究人员设计更有效的数据集,以提升LLM的训练效率。
📄 摘要(原文)
We introduce a scaling law for fine-tuning large language models (LLMs) under fixed compute budgets that explicitly accounts for data composition. Conventional approaches measure training data solely by total tokens, yet the number of examples and their average token length -- what we term \emph{dataset volume} -- play a decisive role in model performance. Our formulation is tuned following established procedures. Experiments on the BRICC dataset \cite{salavati2024reducing} and subsets of the MMLU dataset \cite{hendrycks2021measuringmassivemultitasklanguage}, evaluated under multiple subsampling strategies, reveal that data composition significantly affects token efficiency. These results motivate refined scaling laws for practical LLM fine-tuning in resource-constrained settings.