Sparse Attention Remapping with Clustering for Efficient LLM Decoding on PIM
作者: Zehao Fan, Garrett Gagnon, Zhenyu Liu, Liu Liu
分类: cs.CL, cs.LG
发布日期: 2025-05-09
💡 一句话要点
提出STARC,一种基于聚类的稀疏注意力重映射方法,用于PIM上高效LLM解码。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 存内处理 PIM 大型语言模型 LLM 稀疏注意力 KV缓存 数据映射
📋 核心要点
- 现有LLM解码在内存访问和KV缓存管理上存在瓶颈,尤其是在长上下文场景下,导致内存带宽压力巨大。
- STARC通过语义聚类KV对,并将其映射到与PIM bank结构对齐的连续内存区域,实现集群粒度的选择性注意力和并行处理。
- 实验表明,STARC在HBM-PIM系统上显著降低了注意力层延迟和能耗,同时保持了与现有稀疏注意力方法相当的模型精度。
📝 摘要(中文)
基于Transformer的模型是现代机器学习的基础,但其执行,特别是在大型语言模型(LLM)的自回归解码过程中,由于频繁的内存访问和不断增长的键值(KV)缓存,给内存系统带来了巨大的压力。这在内存带宽上造成了瓶颈,尤其是在上下文长度增加时。存内处理(PIM)架构是一种有前景的解决方案,它提供高内部带宽和靠近内存的计算并行性。然而,目前的PIM设计主要针对密集注意力进行了优化,并且难以应对现代KV缓存稀疏技术引入的动态、不规则的访问模式。因此,它们受到工作负载不平衡的影响,降低了吞吐量和资源利用率。在这项工作中,我们提出STARC,一种新颖的稀疏优化数据映射方案,专门为在PIM架构上高效LLM解码而定制。STARC通过语义相似性对KV对进行聚类,并将它们映射到与PIM bank结构对齐的连续内存区域。在解码过程中,查询通过与预先计算的质心匹配,以集群粒度检索相关token,从而实现选择性注意力和并行处理,而无需频繁的重新聚类或数据移动开销。在HBM-PIM系统上的实验表明,与常见的token级稀疏方法相比,STARC将注意力层延迟降低了19%--31%,能耗降低了19%--27%。在1024的KV缓存预算下,与完整KV缓存检索相比,它实现了高达54%--74%的延迟降低和45%--67%的能耗降低。同时,STARC保持了与最先进的稀疏注意力方法相当的模型精度,证明了其在PIM架构上实现高效和硬件友好的长上下文LLM推理的有效性。
🔬 方法详解
问题定义:论文旨在解决LLM在PIM架构上进行高效解码的问题。现有方法,特别是针对密集注意力的PIM设计,无法有效处理KV缓存稀疏化带来的动态、不规则内存访问模式,导致工作负载不平衡和资源利用率降低。
核心思路:核心思路是通过语义相似性对KV对进行聚类,并将相似的KV对映射到连续的内存区域,以便在解码时能够以集群为单位进行检索。这种方法旨在减少不必要的内存访问,并提高PIM架构的并行处理能力。
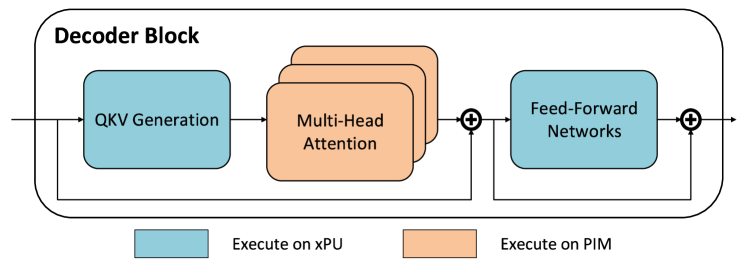
技术框架:STARC的技术框架主要包含以下几个阶段:1) KV对聚类:使用语义相似性度量(具体方法未知)将KV对聚类成不同的簇。2) 数据映射:将每个簇的KV对映射到PIM的连续内存区域,并与PIM bank结构对齐。3) 解码:在解码过程中,查询首先与预先计算的簇质心进行匹配,选择相关的簇。然后,仅从选定的簇中检索KV对,进行注意力计算。
关键创新:STARC的关键创新在于其稀疏优化数据映射方案,该方案专门为PIM架构上的高效LLM解码而设计。与传统的token级稀疏方法相比,STARC通过聚类减少了不必要的内存访问,并提高了PIM架构的并行处理能力。与动态聚类方法相比,STARC避免了频繁的重新聚类和数据移动开销。
关键设计:论文中提到使用预计算的簇质心进行查询匹配,但未详细说明聚类算法、相似性度量、簇的数量、以及质心的计算方法等关键技术细节。这些参数和算法的选择可能会对性能产生重要影响,具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与常见的token级稀疏方法相比,STARC将注意力层延迟降低了19%--31%,能耗降低了19%--27%。在1024的KV缓存预算下,与完整KV缓存检索相比,STARC实现了高达54%--74%的延迟降低和45%--67%的能耗降低。同时,STARC保持了与最先进的稀疏注意力方法相当的模型精度。
🎯 应用场景
STARC的研究成果可应用于各种需要高效LLM推理的场景,例如边缘设备上的自然语言处理、低功耗服务器上的语言模型部署等。通过优化内存访问和提高计算并行性,STARC能够降低LLM推理的延迟和能耗,从而扩展LLM的应用范围,并促进其在资源受限环境中的部署。
📄 摘要(原文)
Transformer-based models are the foundation of modern machine learning, but their execution, particularly during autoregressive decoding in large language models (LLMs), places significant pressure on memory systems due to frequent memory accesses and growing key-value (KV) caches. This creates a bottleneck in memory bandwidth, especially as context lengths increase. Processing-in-memory (PIM) architectures are a promising solution, offering high internal bandwidth and compute parallelism near memory. However, current PIM designs are primarily optimized for dense attention and struggle with the dynamic, irregular access patterns introduced by modern KV cache sparsity techniques. Consequently, they suffer from workload imbalance, reducing throughput and resource utilization. In this work, we propose STARC, a novel sparsity-optimized data mapping scheme tailored specifically for efficient LLM decoding on PIM architectures. STARC clusters KV pairs by semantic similarity and maps them to contiguous memory regions aligned with PIM bank structures. During decoding, queries retrieve relevant tokens at cluster granularity by matching against precomputed centroids, enabling selective attention and parallel processing without frequent reclustering or data movement overhead. Experiments on the HBM-PIM system show that, compared to common token-wise sparsity methods, STARC reduces attention-layer latency by 19%--31% and energy consumption by 19%--27%. Under a KV cache budget of 1024, it achieves up to 54%--74% latency reduction and 45%--67% energy reduction compared to full KV cache retrieval. Meanwhile, STARC maintains model accuracy comparable to state-of-the-art sparse attention methods, demonstrating its effectiveness in enabling efficient and hardware-friendly long-context LLM inference on PIM architectures.