TopicVD: A Topic-Based Dataset of Video-Guided Multimodal Machine Translation for Documentaries
作者: Jinze Lv, Jian Chen, Zi Long, Xianghua Fu, Yin Chen
分类: cs.CL
发布日期: 2025-05-09
备注: NLDB 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出TopicVD数据集,用于纪录片视频引导的多模态机器翻译研究。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态机器翻译 视频引导翻译 纪录片翻译 跨模态注意力 领域自适应
📋 核心要点
- 现有多模态机器翻译数据集缺乏长视频和多样主题,难以满足纪录片翻译等实际需求。
- 论文构建TopicVD数据集,包含八个主题的纪录片视频和字幕,并保留上下文信息。
- 提出基于跨模态双向注意力的MMT模型,实验证明视觉信息和全局上下文能提升翻译效果。
📝 摘要(中文)
现有的大多数多模态机器翻译(MMT)数据集主要由静态图像或短视频片段组成,缺乏跨越不同领域和主题的广泛视频数据。这导致它们无法满足真实世界MMT任务的需求,例如纪录片翻译。本研究开发了TopicVD,一个基于主题的纪录片视频支持的多模态机器翻译数据集,旨在推进该领域的研究。我们从纪录片中收集了视频-字幕对,并将它们分为八个主题,例如经济和自然,以促进视频引导的MMT中领域自适应的研究。此外,我们保留了它们的上下文信息,以支持在视频引导的MMT中利用纪录片的全局上下文的研究。为了更好地捕捉文本和视频之间的共享语义,我们提出了一种基于跨模态双向注意力模块的MMT模型。在TopicVD数据集上的大量实验表明,视觉信息始终如一地提高了NMT模型在纪录片翻译中的性能。然而,MMT模型在领域外场景中的性能显著下降,突出了对有效领域自适应方法的需求。此外,实验表明全局上下文可以有效地提高翻译性能。
🔬 方法详解
问题定义:论文旨在解决纪录片视频引导的多模态机器翻译问题。现有方法主要基于静态图像或短视频,缺乏对纪录片长视频和多样主题的适配,难以有效利用视频信息提升翻译质量。此外,现有方法较少考虑纪录片的全局上下文信息,限制了翻译的准确性和连贯性。
核心思路:论文的核心思路是构建一个大规模、主题多样、包含全局上下文信息的纪录片视频数据集TopicVD,并在此基础上设计一个能够有效融合视频信息和全局上下文信息的MMT模型。通过TopicVD数据集的构建,为纪录片视频引导的多模态机器翻译研究提供了基础。通过提出的MMT模型,验证了视觉信息和全局上下文信息对翻译质量的提升作用。
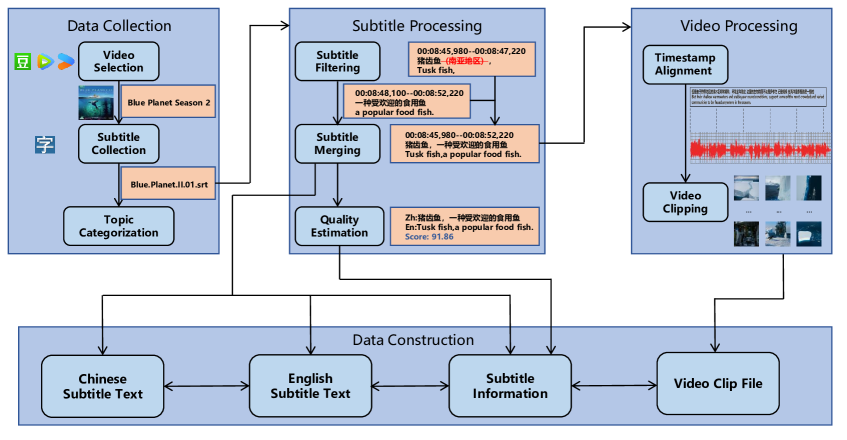
技术框架:论文的技术框架主要包括数据集构建和模型设计两部分。数据集构建方面,从纪录片中收集视频-字幕对,并按照主题进行分类,同时保留上下文信息。模型设计方面,提出了一种基于跨模态双向注意力模块的MMT模型,该模型能够同时利用视觉信息和全局上下文信息进行翻译。
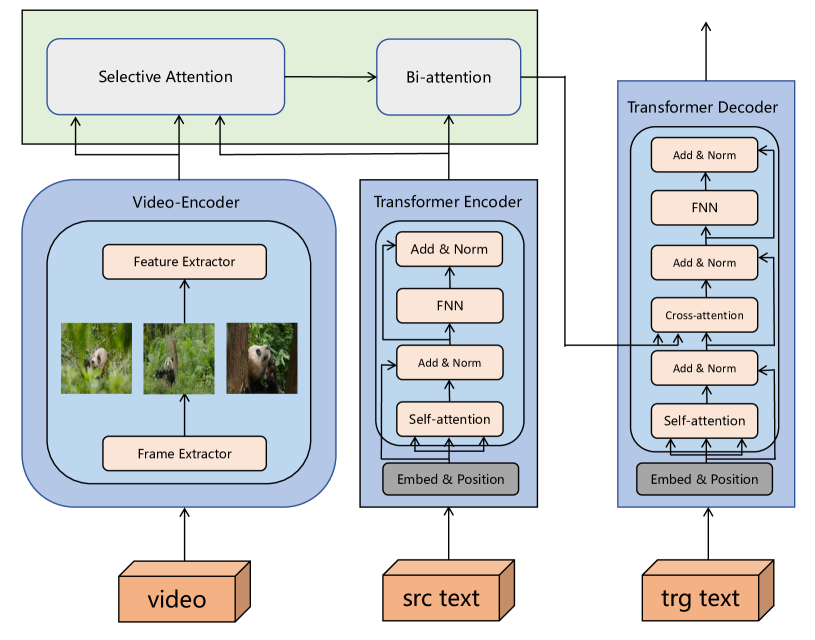
关键创新:论文的关键创新在于:1) 构建了TopicVD数据集,该数据集是首个专门针对纪录片视频引导的多模态机器翻译的数据集,具有主题多样、包含全局上下文信息等特点。2) 提出了基于跨模态双向注意力模块的MMT模型,该模型能够有效融合视觉信息和全局上下文信息,提升翻译质量。
关键设计:在模型设计方面,跨模态双向注意力模块是关键。该模块通过双向注意力机制,分别从文本到视频和从视频到文本两个方向学习模态间的关联。此外,模型还考虑了全局上下文信息,通过对整个纪录片视频进行编码,获取全局语义表示,并将其融入到翻译过程中。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在TopicVD数据集上,视觉信息能够持续提升NMT模型的翻译性能。然而,MMT模型在领域外场景下的性能显著下降,表明需要有效的领域自适应方法。此外,实验证明全局上下文能够有效提升翻译性能,验证了全局上下文信息的重要性。(具体性能数据未知)
🎯 应用场景
该研究成果可应用于纪录片、新闻视频等多媒体内容的自动翻译,提升跨语言信息传播效率。同时,该数据集和模型为多模态机器翻译领域的研究提供了新的资源和思路,有助于推动相关技术的发展,例如在线教育视频翻译、国际会议实时翻译等。
📄 摘要(原文)
Most existing multimodal machine translation (MMT) datasets are predominantly composed of static images or short video clips, lacking extensive video data across diverse domains and topics. As a result, they fail to meet the demands of real-world MMT tasks, such as documentary translation. In this study, we developed TopicVD, a topic-based dataset for video-supported multimodal machine translation of documentaries, aiming to advance research in this field. We collected video-subtitle pairs from documentaries and categorized them into eight topics, such as economy and nature, to facilitate research on domain adaptation in video-guided MMT. Additionally, we preserved their contextual information to support research on leveraging the global context of documentaries in video-guided MMT. To better capture the shared semantics between text and video, we propose an MMT model based on a cross-modal bidirectional attention module. Extensive experiments on the TopicVD dataset demonstrate that visual information consistently improves the performance of the NMT model in documentary translation. However, the MMT model's performance significantly declines in out-of-domain scenarios, highlighting the need for effective domain adaptation methods. Additionally, experiments demonstrate that global context can effectively improve translation performance. % Dataset and our implementations are available at https://github.com/JinzeLv/TopicVD