Scalable LLM Math Reasoning Acceleration with Low-rank Distillation
作者: Harry Dong, Bilge Acun, Beidi Chen, Yuejie Chi
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-08 (更新: 2025-09-30)
💡 一句话要点
Caprese:低秩蒸馏加速LLM数学推理,显著降低计算成本
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 高效推理 蒸馏学习 低秩适应 模型加速 模型压缩
📋 核心要点
- 现有高效推理方法在加速LLM推理的同时,往往会显著降低其在数学推理任务上的性能。
- Caprese通过低秩蒸馏,在少量额外参数和数据下,恢复高效推理方法损失的数学能力,同时保持语言能力。
- 实验表明,Caprese能有效减少活跃参数数量,降低推理延迟,并鼓励生成更简洁的答案,同时恢复数学推理性能。
📝 摘要(中文)
大型语言模型(LLM)的数学推理由于生成过程长,需要大量的计算资源和时间。虽然现有的许多高效推理方法在语言任务上表现出色,但在数学性能上往往会严重下降。本文提出了一种资源高效的蒸馏方法Caprese,旨在恢复部署高效推理方法后损失的能力,主要集中在前馈模块中。在原始权重保持不变的情况下,仅增加约1%的额外参数,并使用2万个合成训练样本,我们能够恢复思维LLM因高效推理而损失的大部分甚至全部数学能力,并且不损害指令LLM的语言任务。此外,Caprese减少了活跃参数的数量(Gemma 2 9B和Llama 3.1 8B减少约2B),并能干净地集成到现有模型层中,以减少延迟(time-to-next-token减少超过16%),同时鼓励响应简洁(减少高达8.5%的token)。
🔬 方法详解
问题定义:大型语言模型在数学推理任务中计算成本高昂,现有高效推理方法虽然能加速推理,但通常会牺牲数学推理的准确性。因此,如何在不显著降低数学推理性能的前提下,提升LLM的推理效率是一个关键问题。
核心思路:Caprese的核心思路是通过蒸馏学习,将原始模型的能力迁移到经过高效推理方法处理后的模型上,从而恢复其在数学推理任务中损失的性能。通过引入少量额外参数,并利用合成数据进行训练,使模型能够学习到原始模型的推理能力。
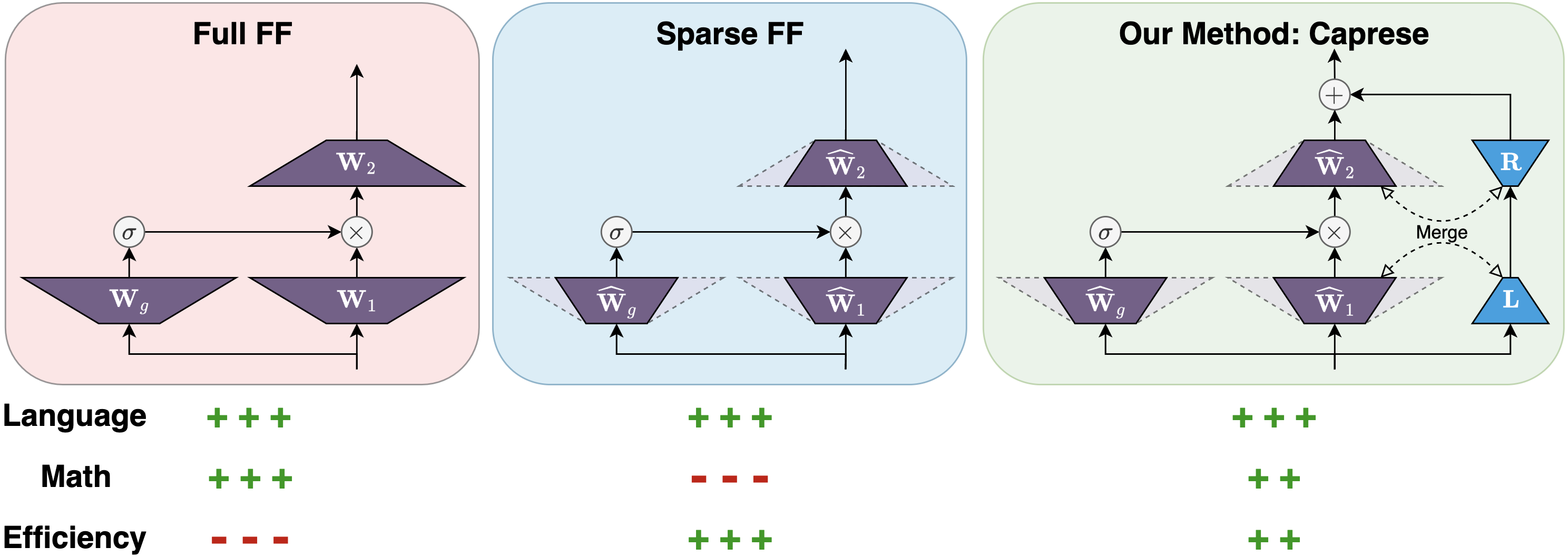
技术框架:Caprese主要针对LLM的前馈模块进行优化。整体流程包括:1) 使用高效推理方法(如剪枝、量化等)处理原始LLM;2) 在处理后的模型中引入少量低秩参数;3) 使用合成的数学推理数据集,通过蒸馏学习训练这些新增参数,使模型恢复数学推理能力。原始模型的权重保持不变,只训练新增的低秩参数。
关键创新:Caprese的关键创新在于其资源高效的蒸馏方法。它仅需少量额外参数(约1%)和少量合成训练样本(2万个),就能有效恢复高效推理方法带来的性能损失。此外,Caprese能够干净地集成到现有模型层中,减少了推理延迟。
关键设计:Caprese使用低秩适应(LoRA)的方式引入额外参数,这些参数被添加到前馈网络的权重矩阵中。损失函数采用标准的蒸馏损失,鼓励学生模型(经过高效推理处理的模型)的输出与教师模型(原始模型)的输出尽可能接近。合成数据集的设计至关重要,需要覆盖各种数学推理题型,并保证数据的质量。
🖼️ 关键图片

📊 实验亮点
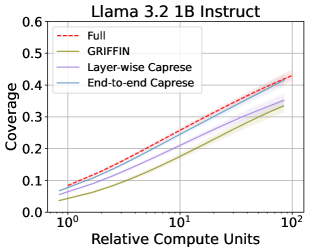
实验结果表明,Caprese能够显著恢复因高效推理方法损失的数学推理能力,同时不损害语言任务的性能。对于Gemma 2 9B和Llama 3.1 8B模型,Caprese减少了约2B的活跃参数,降低了超过16%的time-to-next-token延迟,并减少了高达8.5%的token生成数量。
🎯 应用场景
Caprese可应用于各种需要高效LLM推理的场景,例如移动设备上的本地推理、资源受限的边缘计算环境等。通过降低计算成本和延迟,Caprese使得LLM能够在更广泛的场景中部署,并加速数学、科学等领域的应用。
📄 摘要(原文)
Due to long generations, large language model (LLM) math reasoning demands significant computational resources and time. While many existing efficient inference methods have been developed with excellent performance preservation on language tasks, they often severely degrade math performance. In this paper, we propose Caprese, a resource-efficient distillation method to recover lost capabilities from deploying efficient inference methods, focused primarily in feedforward blocks. With original weights unperturbed, roughly 1% of additional parameters, and only 20K synthetic training samples, we are able to recover much if not all of the math capabilities lost from efficient inference for thinking LLMs and without harm to language tasks for instruct LLMs. Moreover, Caprese slashes the number of active parameters (~2B cut for Gemma 2 9B and Llama 3.1 8B) and integrates cleanly into existing model layers to reduce latency (>16% time-to-next-token reduction) while encouraging response brevity (up to 8.5% fewer tokens).