Product of Experts with LLMs: Boosting Performance on ARC Is a Matter of Perspective
作者: Daniel Franzen, Jan Disselhoff, David Hartmann
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-08 (更新: 2025-06-11)
备注: ICML 2025 camera-ready; 15 pages, 6 figures, 5 tables
💡 一句话要点
利用专家乘积与LLM提升ARC性能:视角是关键
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 抽象推理 大型语言模型 数据增强 深度优先搜索 专家乘积 ARC-AGI LLM评分
📋 核心要点
- ARC-AGI挑战LLM的抽象推理能力,现有方法难以有效解决。
- 利用任务特定数据增强、深度优先搜索和LLM评分,生成并选择高质量候选解。
- 在ARC-AGI上达到71.6%的准确率,显著优于其他公开方法,且推理成本极低。
📝 摘要(中文)
抽象与推理语料库(ARC-AGI)对大型语言模型(LLM)提出了重大挑战,暴露了它们在抽象推理能力方面的局限性。本文通过在训练、生成和评分阶段利用任务特定的数据增强,并采用深度优先搜索算法来生成多样化、高概率的候选解决方案。此外,我们不仅将LLM用作生成器,还用作评分器,利用其输出概率来选择最有希望的解决方案。我们的方法在公共ARC-AGI评估集上实现了71.6%的分数(解决了400个任务中的286.5个),展示了公开方法中的最先进性能。虽然同期闭源工作报告了更高的分数,但我们的方法以其透明性、可重复性和极低的推理成本而著称,在现成硬件上的平均每个任务成本仅为2美分左右(我们假设Nvidia 4090 GPU的价格为每小时36美分)。
🔬 方法详解
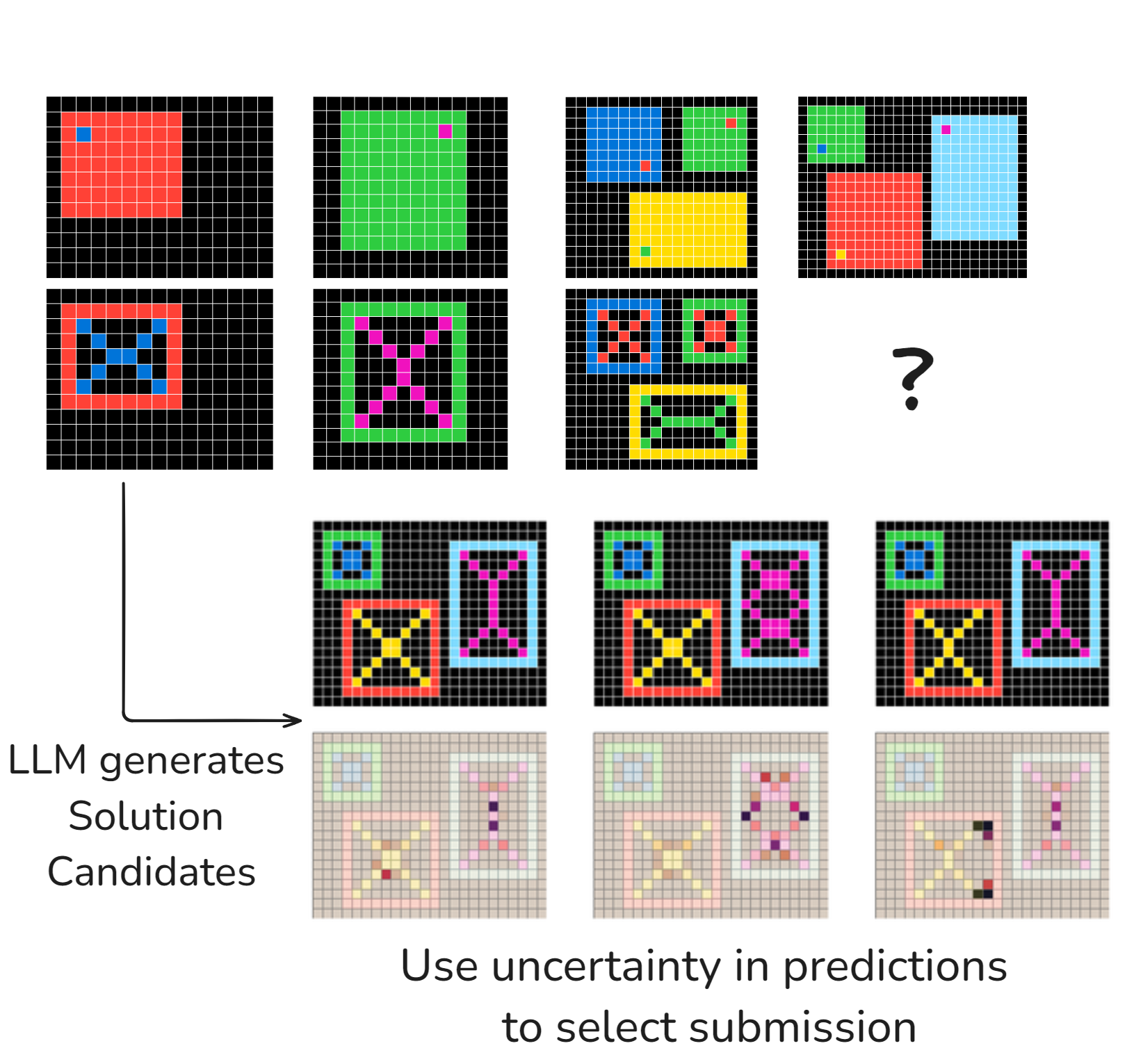
问题定义:论文旨在解决ARC-AGI(Abstraction and Reasoning Corpus)中LLM抽象推理能力不足的问题。现有方法在处理此类任务时,难以生成高质量的候选解,并且缺乏有效的评估机制,导致性能受限。
核心思路:论文的核心思路是利用“专家乘积”的思想,将LLM既作为生成器,又作为评分器,并结合任务特定的数据增强和深度优先搜索,从而生成多样化且高质量的候选解,并通过LLM的概率输出来选择最优解。这种设计旨在充分利用LLM的生成和评估能力,从而提高解决ARC-AGI任务的成功率。
技术框架:整体框架包含三个主要阶段:1) 数据增强:对训练数据进行任务特定的增强,以提高模型的泛化能力。2) 候选解生成:使用深度优先搜索算法,结合LLM生成器,生成多个候选解决方案。3) 候选解评分与选择:利用LLM作为评分器,根据其输出概率对候选解进行排序,并选择概率最高的解作为最终答案。
关键创新:最重要的技术创新点在于将LLM同时用作生成器和评分器,并结合任务特定的数据增强和深度优先搜索。这种方法能够有效地利用LLM的知识和推理能力,生成高质量的候选解,并通过LLM自身的评估机制来选择最优解,从而显著提高了解决ARC-AGI任务的性能。与现有方法相比,该方法更加注重利用LLM自身的特性,而非依赖外部的评估指标。
关键设计:论文中关键的设计包括:1) 任务特定的数据增强策略,旨在提高模型对不同类型ARC任务的适应性。2) 深度优先搜索算法,用于生成多样化的候选解。3) 利用LLM输出概率作为评分标准,避免了引入额外的评分模型或人工标注。4) 推理成本的优化,使得该方法能够在普通硬件上高效运行。
🖼️ 关键图片


📊 实验亮点
该方法在公共ARC-AGI评估集上取得了71.6%的准确率(286.5/400),显著优于其他公开可用的方法,达到了当前最优水平。同时,该方法具有极低的推理成本,平均每个任务仅需约2美分,使其在实际应用中更具优势。与闭源方法相比,该方法具有更高的透明性和可重复性。
🎯 应用场景
该研究成果可应用于提升AI系统的抽象推理能力,尤其是在需要复杂逻辑推理和模式识别的领域,如自动化程序生成、智能游戏AI、以及需要从少量示例中学习的通用人工智能任务。该方法较低的推理成本使其更易于部署和应用。
📄 摘要(原文)
The Abstraction and Reasoning Corpus (ARC-AGI) poses a significant challenge for large language models (LLMs), exposing limitations in their abstract reasoning abilities. In this work, we leverage task-specific data augmentations throughout the training, generation, and scoring phases, and employ a depth-first search algorithm to generate diverse, high-probability candidate solutions. Furthermore, we utilize the LLM not only as a generator but also as a scorer, using its output probabilities to select the most promising solutions. Our method achieves a score of 71.6% (286.5/400 solved tasks) on the public ARC-AGI evaluation set, demonstrating state-of-the-art performance among publicly available approaches. While concurrent closed-source work has reported higher scores, our method distinguishes itself through its transparency, reproducibility, and remarkably low inference cost, averaging only around 2ct per task on readily available hardware (we assume a price of 36ct/hour for a Nvidia 4090 GPU).