Enhanced Urdu Intent Detection with Large Language Models and Prototype-Informed Predictive Pipelines
作者: Faiza Hassan, Summra Saleem, Kashif Javed, Muhammad Nabeel Asim, Abdur Rehman, Andreas Dengel
分类: cs.CL, cs.AI
发布日期: 2025-05-08
备注: 42 pages, 10 figures(including 6 graphs)
💡 一句话要点
提出LLMPIA框架,提升大型语言模型在乌尔都语意图检测中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 意图检测 乌尔都语 大型语言模型 对比学习 原型学习 注意力机制
📋 核心要点
- 乌尔都语意图检测领域发展滞后,缺乏基于少量样本学习的意图检测预测器,传统预测器侧重于预测训练集中已有的类别。
- 利用对比学习方法,通过未标注的乌尔都语数据重新训练预训练语言模型,提升模型对乌尔都语的表征学习能力。
- 构建LLMPIA流水线,结合预训练语言模型和原型信息注意力机制,在两个公开数据集上取得了显著的性能提升。
📝 摘要(中文)
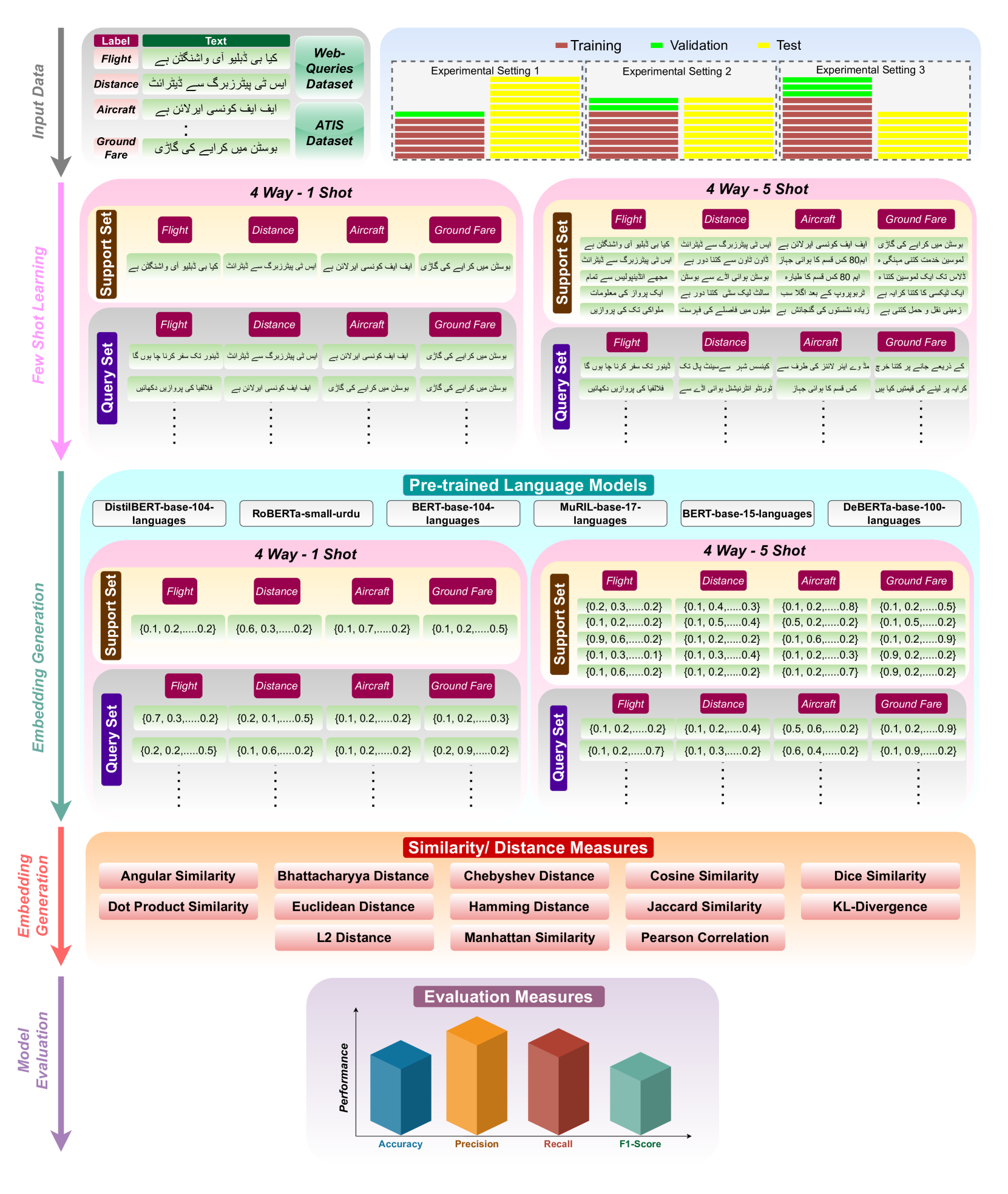
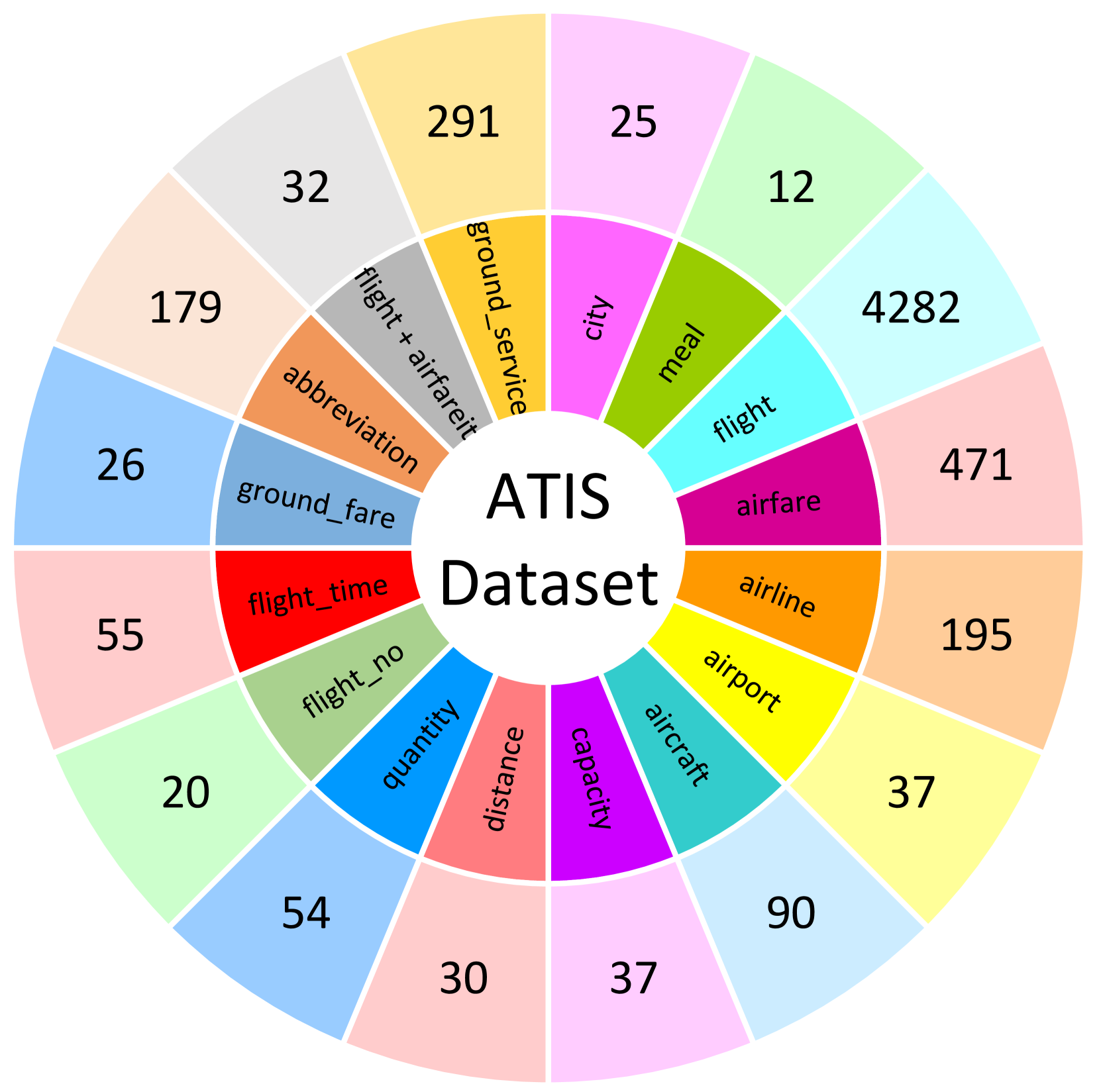
针对乌尔都语意图检测领域发展滞后的问题,本文提出了一种新颖的对比学习方法,利用未标注的乌尔都语数据重新训练预训练语言模型,增强其在下游意图检测任务中的表征学习能力。该方法结合了预训练语言模型和原型信息注意力机制的优势,构建了一个端到端的LLMPIA意图检测流水线。实验评估了6种不同的语言模型和13种不同的相似度计算方法在该流水线中的性能。在ATIS数据集上,LLMPIA在4-way 1-shot和4-way 5-shot设置下分别取得了83.28%和98.25%的F1-Score。在Web Queries数据集上,分别取得了76.23%和84.42%的F1-Score。在Web Queries数据集的同类训练和测试集设置的案例研究中,LLMPIA的F1-Score超过了现有最先进的预测器53.55%。
🔬 方法详解
问题定义:论文旨在解决乌尔都语意图检测任务中,现有方法性能不足的问题。现有方法主要集中在英语等主流语言,对乌尔都语的支持较弱,且缺乏利用少量样本学习的能力,难以泛化到未见过的类别。传统方法依赖于大量标注数据,成本高昂,且难以适应快速变化的意图类型。
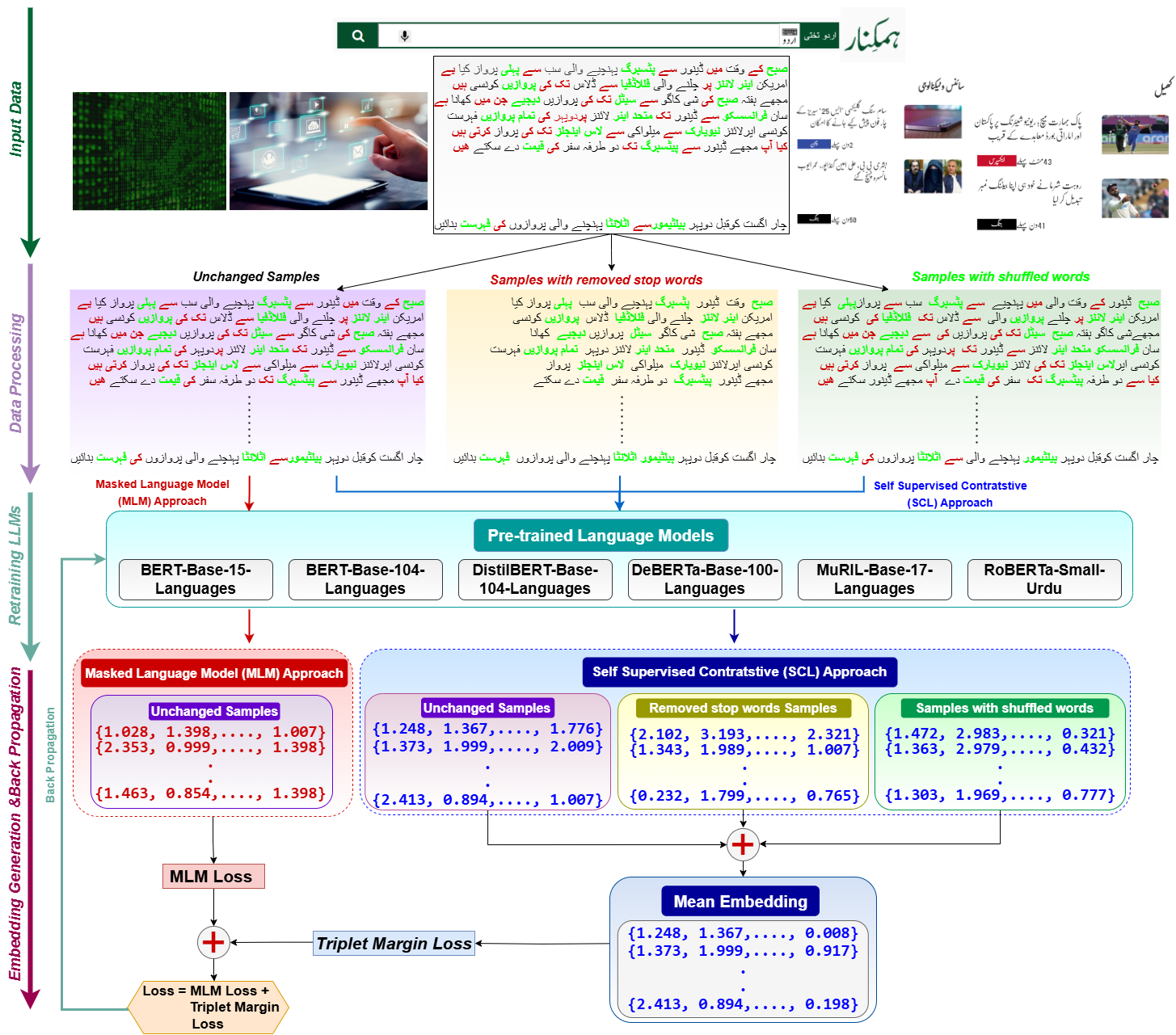
核心思路:论文的核心思路是利用对比学习,通过未标注的乌尔都语数据,增强预训练语言模型对乌尔都语的语义理解能力。同时,结合原型信息注意力机制,使模型能够更好地识别和区分不同的意图类别,从而提高意图检测的准确性和泛化能力。
技术框架:LLMPIA框架包含以下几个主要模块:1) 预训练语言模型:使用预训练的语言模型(如BERT、mBERT等)作为基础模型。2) 对比学习模块:利用未标注的乌尔都语数据,通过对比学习的方式,重新训练预训练语言模型,增强其对乌尔都语的语义表征能力。3) 原型生成模块:为每个意图类别生成原型向量,代表该类别的典型特征。4) 注意力机制模块:利用原型向量,对输入文本进行注意力加权,突出与意图相关的关键信息。5) 分类器:根据加权后的文本表示,预测输入文本的意图类别。
关键创新:论文的关键创新在于:1) 提出了基于对比学习的乌尔都语语言模型微调方法,有效利用了未标注数据。2) 结合了原型信息和注意力机制,提高了模型对意图的识别能力。3) 构建了一个端到端的LLMPIA流水线,简化了意图检测的流程。与现有方法相比,该方法能够更好地利用乌尔都语的语言特性,提高意图检测的准确性和泛化能力。
关键设计:论文探索了6种不同的语言模型和13种不同的相似度计算方法。对比学习的损失函数未知,原型向量的生成方法未知,注意力机制的具体实现方式未知。这些细节对最终性能有重要影响,但论文摘要中未详细说明。
🖼️ 关键图片
📊 实验亮点
LLMPIA框架在ATIS和Web Queries两个乌尔都语数据集上取得了显著的性能提升。在ATIS数据集上,4-way 1-shot和4-way 5-shot设置下分别取得了83.28%和98.25%的F1-Score。在Web Queries数据集上,分别取得了76.23%和84.42%的F1-Score。在Web Queries数据集的同类训练和测试集设置的案例研究中,LLMPIA的F1-Score超过了现有最先进的预测器53.55%。
🎯 应用场景
该研究成果可应用于乌尔都语语音助手、智能客服、信息检索等领域,提升乌尔都语用户的人机交互体验。通过准确理解用户意图,系统可以提供更个性化、更高效的服务,促进乌尔都语信息技术的发展。未来,该方法可以推广到其他低资源语言的意图检测任务中。
📄 摘要(原文)
Multifarious intent detection predictors are developed for different languages, including English, Chinese and French, however, the field remains underdeveloped for Urdu, the 10th most spoken language. In the realm of well-known languages, intent detection predictors utilize the strategy of few-shot learning and prediction of unseen classes based on the model training on seen classes. However, Urdu language lacks few-shot strategy based intent detection predictors and traditional predictors are focused on prediction of the same classes which models have seen in the train set. To empower Urdu language specific intent detection, this introduces a unique contrastive learning approach that leverages unlabeled Urdu data to re-train pre-trained language models. This re-training empowers LLMs representation learning for the downstream intent detection task. Finally, it reaps the combined potential of pre-trained LLMs and the prototype-informed attention mechanism to create a comprehensive end-to-end LLMPIA intent detection pipeline. Under the paradigm of proposed predictive pipeline, it explores the potential of 6 distinct language models and 13 distinct similarity computation methods. The proposed framework is evaluated on 2 public benchmark datasets, namely ATIS encompassing 5836 samples and Web Queries having 8519 samples. Across ATIS dataset under 4-way 1 shot and 4-way 5 shot experimental settings LLMPIA achieved 83.28% and 98.25% F1-Score and on Web Queries dataset produced 76.23% and 84.42% F1-Score, respectively. In an additional case study on the Web Queries dataset under same classes train and test set settings, LLMPIA outperformed state-of-the-art predictor by 53.55% F1-Score.