KG-HTC: Integrating Knowledge Graphs into LLMs for Effective Zero-shot Hierarchical Text Classification
作者: Qianbo Zang, Christophe Zgrzendek, Igor Tchappi, Afshin Khadangi, Johannes Sedlmeir
分类: cs.CL
发布日期: 2025-05-08
🔗 代码/项目: GITHUB
💡 一句话要点
提出KG-HTC,通过融合知识图谱与LLM,有效解决零样本分层文本分类问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分层文本分类 知识图谱 大型语言模型 零样本学习 检索增强生成
📋 核心要点
- 现有分层文本分类方法依赖大量标注数据,但在实际应用中,标注数据往往稀缺,限制了模型的泛化能力。
- KG-HTC的核心思想是利用知识图谱为LLM提供结构化的语义信息,增强模型对标签含义的理解,从而实现零样本分类。
- 实验结果表明,KG-HTC在零样本分层文本分类任务上显著优于现有基线方法,尤其在深层标签分类上提升明显。
📝 摘要(中文)
分层文本分类(HTC)涉及将文档分配到分类体系中的标签。以往的HTC研究主要集中在监督方法上。然而,在实际场景中,由于缺乏标注数据,采用监督HTC可能具有挑战性。此外,HTC经常面临标签空间大和长尾分布的问题。本文提出了用于零样本分层文本分类的知识图谱(KG-HTC),旨在通过将知识图谱与大型语言模型(LLM)集成,在分类过程中提供结构化的语义上下文,从而解决HTC在应用中的这些挑战。我们的方法使用检索增强生成(RAG)方法从知识图谱中检索与输入文本相关的子图。KG-HTC可以增强LLM理解各个层次的标签语义。我们在三个开源HTC数据集WoS、DBpedia和Amazon上评估了KG-HTC。实验结果表明,KG-HTC在严格的零样本设置下显著优于三个基线,尤其是在层次结构的更深层次上取得了显著的改进。该评估证明了将结构化知识融入LLM以解决HTC在大型标签空间和长尾标签分布中的挑战的有效性。我们的代码可在https://github.com/QianboZang/KG-HTC获得。
🔬 方法详解
问题定义:论文旨在解决零样本分层文本分类(Zero-shot Hierarchical Text Classification, HTC)问题。现有监督学习方法在缺乏标注数据的情况下表现不佳,且HTC任务通常面临大规模标签空间和长尾分布的挑战,导致模型难以有效学习和泛化。
核心思路:论文的核心思路是将知识图谱(Knowledge Graph, KG)与大型语言模型(Large Language Model, LLM)相结合。通过知识图谱提供结构化的语义信息,增强LLM对标签含义的理解,从而在零样本场景下实现更准确的分层文本分类。这种方法旨在利用KG的先验知识弥补标注数据的不足。
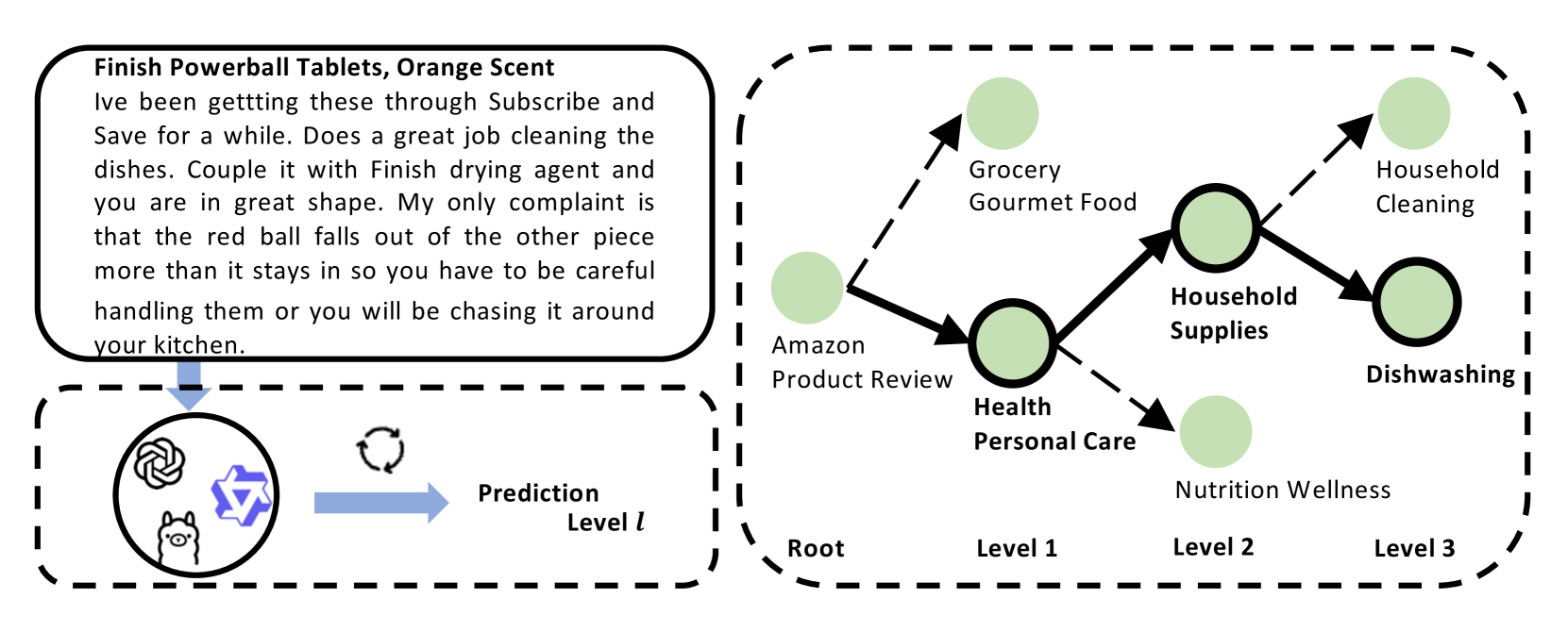
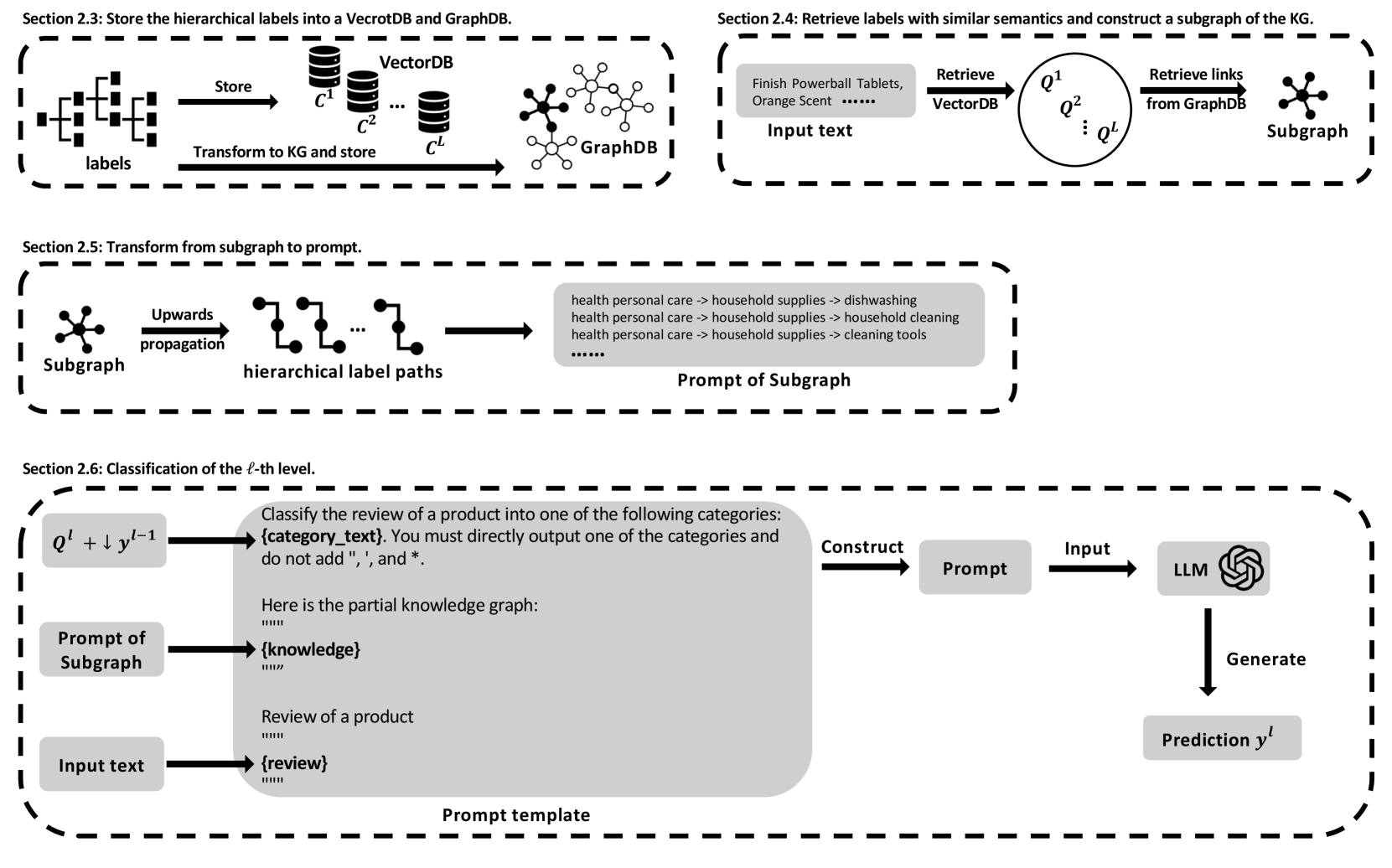
技术框架:KG-HTC的整体框架包含以下几个主要阶段:1) 文本输入:接收待分类的文本数据。2) 知识检索:使用检索增强生成(Retrieval-Augmented Generation, RAG)方法,从知识图谱中检索与输入文本相关的子图。3) 知识融合:将检索到的子图信息融入到LLM的输入中,为LLM提供上下文语义信息。4) 分层分类:LLM基于融合了知识图谱信息的输入,进行分层文本分类,预测文本所属的标签。
关键创新:KG-HTC的关键创新在于将知识图谱引入到零样本分层文本分类任务中,并设计了一种有效的知识融合方法。与传统方法相比,KG-HTC无需标注数据,能够利用知识图谱的结构化信息提升分类性能,尤其是在标签空间大和长尾分布的情况下。
关键设计:论文中涉及的关键设计包括:1) 知识图谱的选择与构建:选择合适的知识图谱,并根据任务需求进行裁剪和构建。2) RAG检索策略:设计高效的RAG检索策略,以准确检索与输入文本相关的子图。3) 知识融合方式:探索不同的知识融合方式,例如将子图信息作为LLM的额外输入,或者利用注意力机制将KG信息融入到LLM的表示中。4) 分层分类策略:设计合适的分层分类策略,例如自顶向下或自底向上,以提高分类的准确性和效率。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,KG-HTC在WoS、DBpedia和Amazon三个数据集上显著优于基线方法。尤其是在层次结构的更深层次上,KG-HTC取得了显著的改进,验证了将结构化知识融入LLM以解决HTC在大型标签空间和长尾标签分布中的挑战的有效性。具体的性能提升数据在摘要中未给出,属于未知信息。
🎯 应用场景
KG-HTC具有广泛的应用前景,例如新闻分类、产品分类、学术论文分类等。在这些场景中,往往缺乏足够的标注数据,且标签体系复杂。KG-HTC能够有效利用知识图谱的先验知识,提升分类性能,降低人工标注成本。未来,该方法有望应用于更多领域,例如智能客服、信息检索等,实现更智能化的文本理解和分类。
📄 摘要(原文)
Hierarchical Text Classification (HTC) involves assigning documents to labels organized within a taxonomy. Most previous research on HTC has focused on supervised methods. However, in real-world scenarios, employing supervised HTC can be challenging due to a lack of annotated data. Moreover, HTC often faces issues with large label spaces and long-tail distributions. In this work, we present Knowledge Graphs for zero-shot Hierarchical Text Classification (KG-HTC), which aims to address these challenges of HTC in applications by integrating knowledge graphs with Large Language Models (LLMs) to provide structured semantic context during classification. Our method retrieves relevant subgraphs from knowledge graphs related to the input text using a Retrieval-Augmented Generation (RAG) approach. Our KG-HTC can enhance LLMs to understand label semantics at various hierarchy levels. We evaluate KG-HTC on three open-source HTC datasets: WoS, DBpedia, and Amazon. Our experimental results show that KG-HTC significantly outperforms three baselines in the strict zero-shot setting, particularly achieving substantial improvements at deeper levels of the hierarchy. This evaluation demonstrates the effectiveness of incorporating structured knowledge into LLMs to address HTC's challenges in large label spaces and long-tailed label distributions. Our code is available at: https://github.com/QianboZang/KG-HTC.