Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
作者: Yudong Wang, Zixuan Fu, Jie Cai, Peijun Tang, Hongya Lyu, Yewei Fang, Zhi Zheng, Jie Zhou, Guoyang Zeng, Chaojun Xiao, Xu Han, Zhiyuan Liu
分类: cs.CL
发布日期: 2025-05-08
备注: The datasets are available on https://huggingface.co/datasets/openbmb/UltraFineWeb
💡 一句话要点
Ultra-FineWeb:高效数据过滤与验证,提升大语言模型训练数据质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据过滤 数据验证 高质量数据 预训练语料库
📋 核心要点
- 现有模型驱动的数据过滤方法缺乏高效的数据验证策略,难以快速评估数据质量并及时反馈。
- 论文提出一种高效的验证策略,并优化正负样本选择,构建高效数据过滤流程,提升过滤效率和分类器质量。
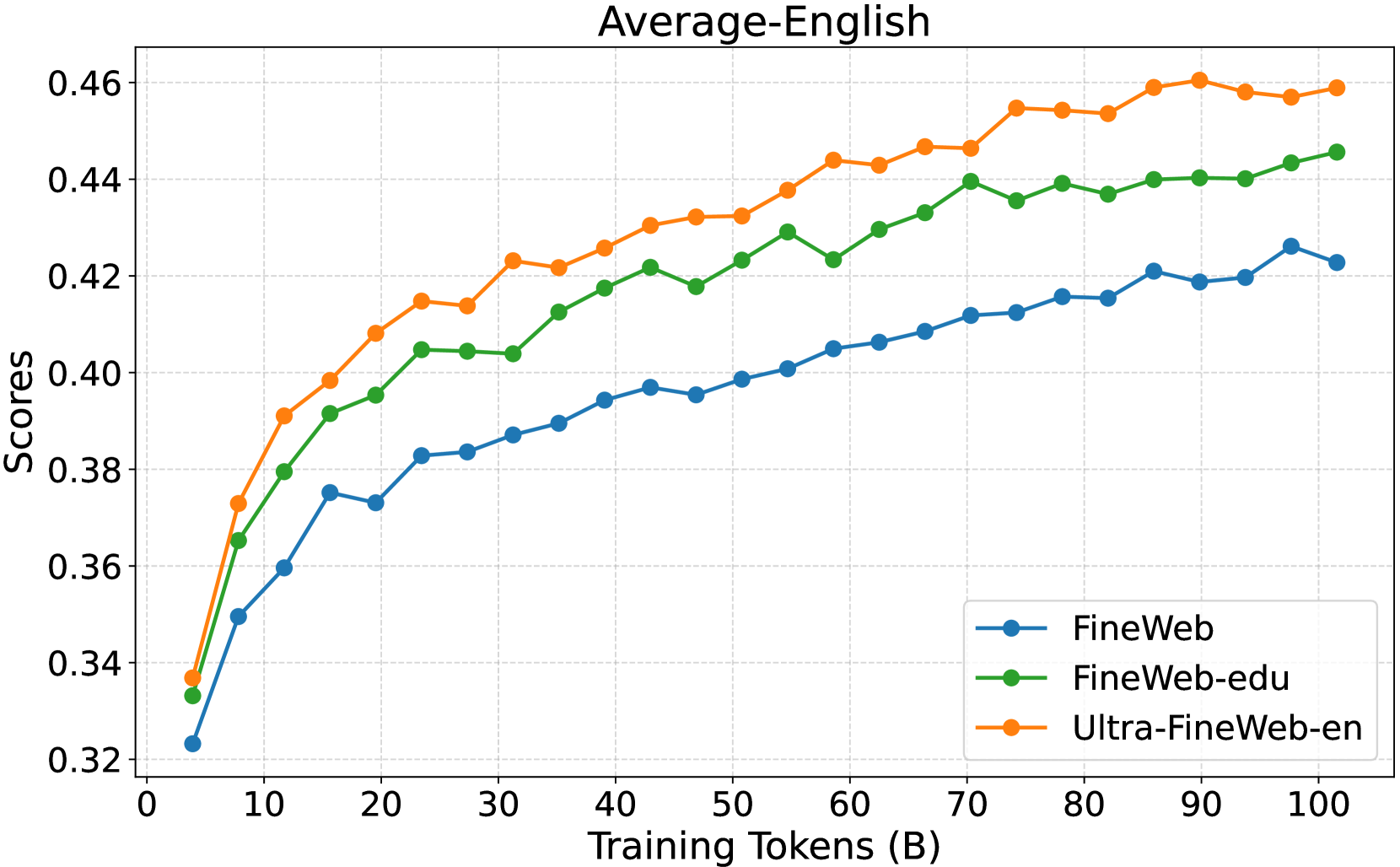
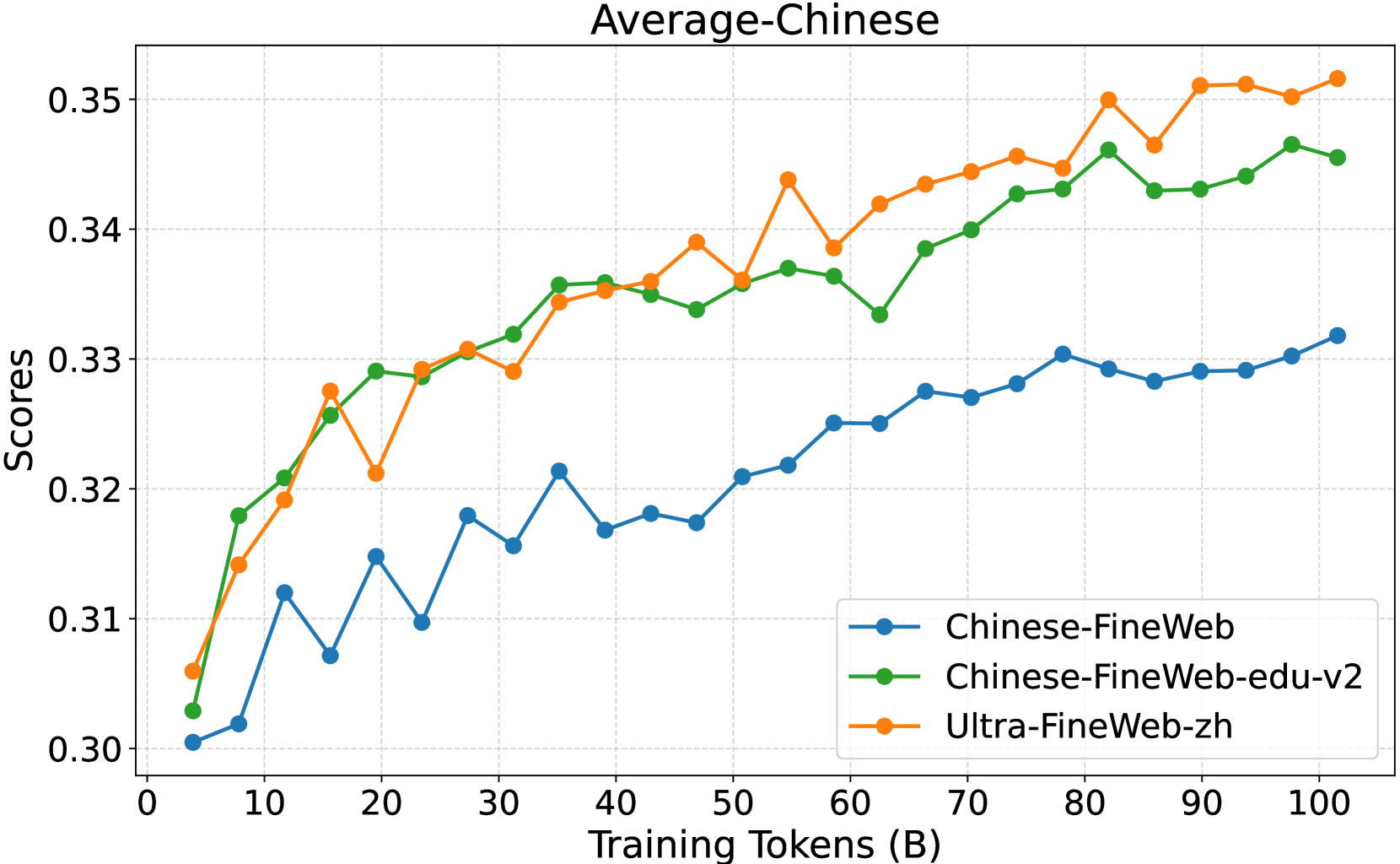
- 实验结果表明,使用Ultra-FineWeb训练的LLM在多个基准测试中性能显著提升,验证了流程的有效性。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,数据质量已成为提升模型性能的关键因素。模型驱动的数据过滤已成为获取高质量数据的主要方法。然而,它仍然面临两个主要挑战:(1)缺乏高效的数据验证策略,难以提供关于数据质量的及时反馈;(2)用于训练分类器的种子数据的选择缺乏明确的标准,并且严重依赖于人类专业知识,引入了一定程度的主观性。为了解决第一个挑战,我们引入了一种高效的验证策略,能够以最小的计算成本快速评估数据对LLM训练的影响。为了解决第二个挑战,我们基于高质量种子数据有益于LLM训练的假设,通过整合所提出的验证策略,优化了正负样本的选择,并提出了一个高效的数据过滤流程。该流程不仅提高了过滤效率、分类器质量和鲁棒性,而且显著降低了实验和推理成本。此外,为了高效地过滤高质量数据,我们采用了一种基于fastText的轻量级分类器,并将过滤流程成功应用于两个广泛使用的预训练语料库,FineWeb和Chinese FineWeb数据集,从而创建了更高质量的Ultra-FineWeb数据集。Ultra-FineWeb包含大约1万亿个英语token和1200亿个中文token。经验结果表明,在Ultra-FineWeb上训练的LLM在多个基准任务上表现出显著的性能改进,验证了我们的流程在提高数据质量和训练效率方面的有效性。
🔬 方法详解
问题定义:当前大语言模型依赖高质量的训练数据,但模型驱动的数据过滤方法面临数据验证效率低和种子数据选择主观性强的问题。现有方法难以快速评估数据质量,且依赖人工经验选择种子数据,影响过滤效果和模型性能。
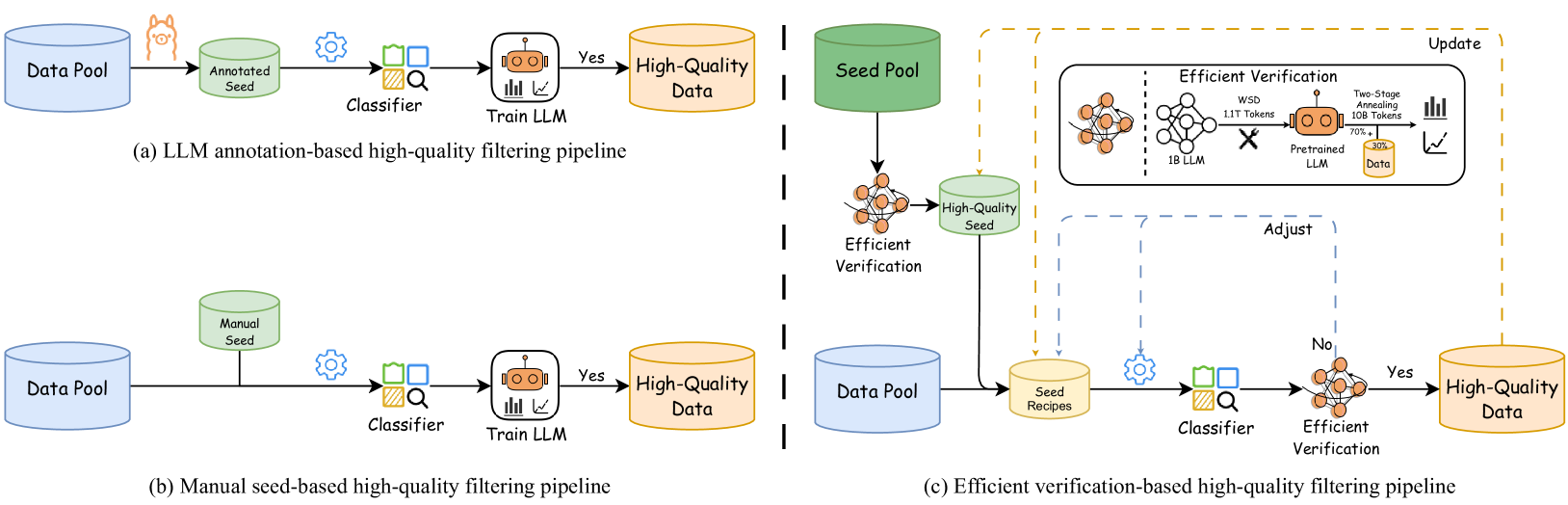
核心思路:论文的核心思路是构建一个高效的数据过滤和验证流程,通过高效的验证策略快速评估数据对LLM训练的影响,并优化种子数据的选择过程,减少人工干预,提高数据过滤的客观性和有效性。
技术框架:整体流程包括以下几个主要阶段:1) 数据收集:从FineWeb和Chinese FineWeb等语料库收集原始数据。2) 种子数据选择:利用提出的验证策略优化正负样本的选择。3) 分类器训练:使用fastText训练轻量级分类器。4) 数据过滤:使用训练好的分类器对原始数据进行过滤。5) 数据验证:使用高效的验证策略评估过滤后的数据质量。
关键创新:论文的关键创新在于提出了一种高效的数据验证策略,能够以最小的计算成本快速评估数据对LLM训练的影响。此外,通过整合该验证策略,优化了正负样本的选择,减少了对人工经验的依赖,提高了数据过滤的客观性和效率。
关键设计:论文采用fastText作为轻量级分类器,以提高过滤效率。在种子数据选择方面,通过验证策略评估不同种子数据对LLM训练的影响,选择对模型性能提升最大的种子数据。具体的损失函数和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文构建了Ultra-FineWeb数据集,包含1万亿个英语token和1200亿个中文token。实验结果表明,使用Ultra-FineWeb训练的LLM在多个基准测试中性能显著提升,验证了该数据过滤流程在提高数据质量和训练效率方面的有效性。具体的性能提升数据未在摘要中详细说明,属于未知信息。
🎯 应用场景
该研究成果可广泛应用于大语言模型的预训练数据构建,为各种自然语言处理任务提供更高质量的训练数据。通过提升数据质量,可以有效提高LLM的性能,降低训练成本,并促进LLM在各个领域的应用,例如智能客服、机器翻译、文本生成等。
📄 摘要(原文)
Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.