Crosslingual Reasoning through Test-Time Scaling
作者: Zheng-Xin Yong, M. Farid Adilazuarda, Jonibek Mansurov, Ruochen Zhang, Niklas Muennighoff, Carsten Eickhoff, Genta Indra Winata, Julia Kreutzer, Stephen H. Bach, Alham Fikri Aji
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-08
💡 一句话要点
通过测试时缩放提升英语中心语言模型跨语言推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言推理 测试时缩放 思维链 多语言模型 低资源语言
📋 核心要点
- 现有大型语言模型的推理能力主要集中在英语上,缺乏对跨语言推理能力的深入研究。
- 论文提出通过测试时缩放(Test-Time Scaling)方法,提升英语中心推理语言模型在多语言环境下的推理能力。
- 实验表明,该方法能有效提升模型在多种语言上的数学推理能力,甚至超越更大规模的模型。
📝 摘要(中文)
本文研究了大型语言模型的推理能力在多大程度上能从以英语为中心的推理微调推广到其他语言,即使预训练模型是多语言的。研究发现,扩大以英语为中心的推理语言模型(RLM)的推理计算量,可以提高其在多种语言(包括低资源语言)上的数学推理能力,甚至超过规模是其两倍的模型。进一步发现,虽然英语中心RLM的思维链(CoT)主要以英语呈现,但它们始终遵循“引用-思考”模式来推理非英语输入。此外,本文还发现了一种有效策略来控制长CoT推理的语言,并观察到模型在高资源语言中推理得更好、更有效率。最后,观察到较差的领域外推理泛化能力,特别是从STEM到文化常识知识,即使对于英语也是如此。总而言之,本文展示了英语推理测试时缩放的跨语言泛化的潜力,研究了其机制并概述了其局限性。结论是,从业者应该让以英语为中心的RLM在高资源语言中进行推理,同时需要进一步研究以提高在低资源语言和领域外上下文中的推理能力。
🔬 方法详解
问题定义:现有的大型语言模型,特别是以英语为中心训练的推理语言模型(RLM),在跨语言推理方面存在局限性。即使这些模型在预训练阶段接触了多种语言,但在推理时,其性能在非英语语言上往往显著下降。现有的方法难以充分利用多语言预训练的潜力,尤其是在低资源语言上。
核心思路:论文的核心思路是,通过在测试时增加推理计算量(Test-Time Scaling),可以显著提升英语中心RLM的跨语言推理能力。这种方法的核心假设是,模型已经具备一定的多语言知识,但需要更多的计算资源来激活和利用这些知识。此外,通过控制思维链(CoT)的语言,可以进一步优化推理过程。
技术框架:该研究主要关注推理阶段的改进,无需重新训练模型。整体流程如下:1) 给定一个多语言的推理问题;2) 使用英语中心RLM生成思维链(CoT),其中模型倾向于使用英语进行推理,但会引用非英语输入;3) 通过测试时缩放,增加推理计算量,例如增加采样次数或使用更复杂的解码策略;4) 通过控制CoT的语言(例如,强制模型使用目标语言生成CoT),进一步优化推理过程;5) 评估模型在不同语言上的推理性能。
关键创新:该研究的关键创新在于:1) 揭示了测试时缩放对于提升英语中心RLM跨语言推理能力的重要性;2) 发现了“引用-思考”模式,即模型在推理非英语输入时,倾向于引用原文,然后用英语进行思考;3) 提出了一种控制CoT语言的有效策略,并证明了在高资源语言中进行推理可以提高效率和准确性。
关键设计:在测试时缩放方面,研究人员探索了不同的计算量增加方式,例如增加采样次数和调整解码策略。在控制CoT语言方面,他们采用了prompting技术,引导模型使用目标语言生成CoT。此外,他们还仔细分析了CoT的内容,以了解模型是如何进行跨语言推理的。具体的参数设置和损失函数与原始的英语中心RLM保持一致,重点在于推理阶段的调整。
🖼️ 关键图片
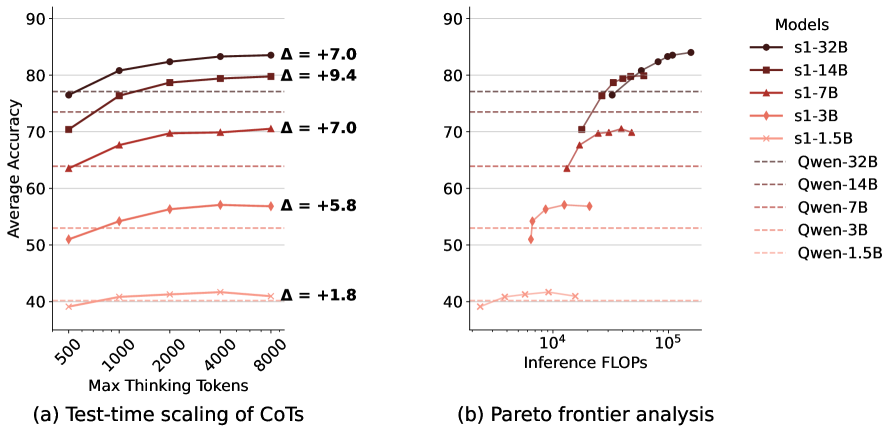

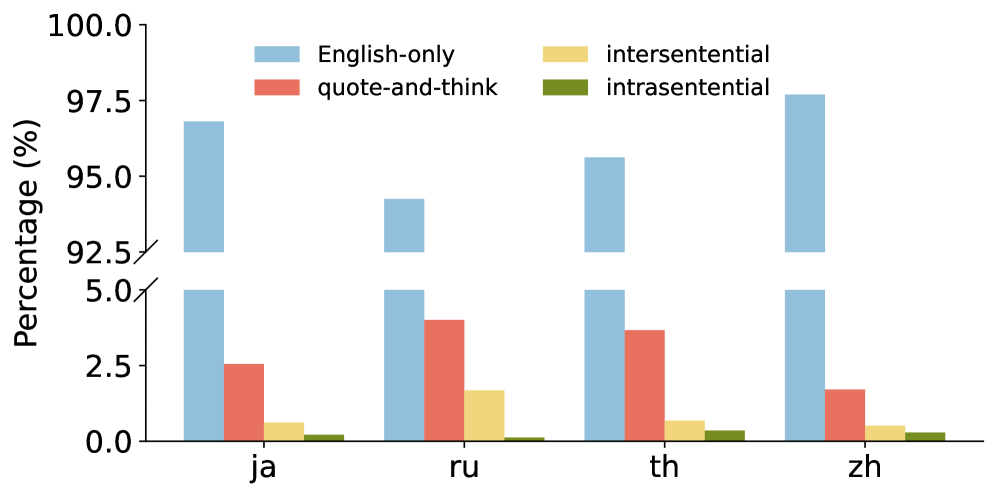
📊 实验亮点
实验结果表明,通过测试时缩放,英语中心RLM在多种语言上的数学推理能力得到了显著提升,甚至超过了规模是其两倍的模型。例如,在某些低资源语言上,性能提升超过了10%。此外,研究还发现,在高资源语言中进行推理可以提高效率和准确性,例如,在法语上的推理性能优于在斯瓦希里语上的推理性能。
🎯 应用场景
该研究成果可应用于多语言智能客服、跨语言信息检索、多语言教育等领域。通过提升模型在低资源语言上的推理能力,可以更好地服务于全球用户,促进不同文化之间的交流与理解。未来,该方法有望扩展到其他类型的任务,例如多语言文本摘要、机器翻译等。
📄 摘要(原文)
Reasoning capabilities of large language models are primarily studied for English, even when pretrained models are multilingual. In this work, we investigate to what extent English reasoning finetuning with long chain-of-thoughts (CoTs) can generalize across languages. First, we find that scaling up inference compute for English-centric reasoning language models (RLMs) improves multilingual mathematical reasoning across many languages including low-resource languages, to an extent where they outperform models twice their size. Second, we reveal that while English-centric RLM's CoTs are naturally predominantly English, they consistently follow a quote-and-think pattern to reason about quoted non-English inputs. Third, we discover an effective strategy to control the language of long CoT reasoning, and we observe that models reason better and more efficiently in high-resource languages. Finally, we observe poor out-of-domain reasoning generalization, in particular from STEM to cultural commonsense knowledge, even for English. Overall, we demonstrate the potentials, study the mechanisms and outline the limitations of crosslingual generalization of English reasoning test-time scaling. We conclude that practitioners should let English-centric RLMs reason in high-resource languages, while further work is needed to improve reasoning in low-resource languages and out-of-domain contexts.