Frame In, Frame Out: Do LLMs Generate More Biased News Headlines than Humans?
作者: Valeria Pastorino, Nafise Sadat Moosavi
分类: cs.CL
发布日期: 2025-05-08
💡 一句话要点
研究表明,大型语言模型比人类更易生成带有偏见的新闻标题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 新闻标题生成 框架效应 偏见分析 自然语言处理
📋 核心要点
- 媒体框架效应影响公众认知,自动化新闻创作中LLM可能引入或放大偏见。
- 研究对比分析了LLM与人类生成新闻标题的框架效应,尤其关注政治敏感内容。
- 实验发现LLM在特定情境下比人类更易产生框架偏见,且不同模型间存在差异。
📝 摘要(中文)
媒体中的框架效应通过选择性地强调某些细节而淡化其他细节,从而深刻地影响公众认知。随着大型语言模型在自动化新闻和内容创作中的兴起,人们越来越担心这些系统可能会引入甚至放大框架偏见,超过人类作者。本文探讨了框架效应如何在开箱即用和微调的LLM生成的新闻内容中体现。分析表明,特别是在政治和社会敏感的背景下,LLM倾向于表现出比人类更明显的框架效应。此外,我们观察到不同模型架构之间的框架倾向存在显著差异,一些模型表现出明显更高的偏差。这些发现表明,需要有效的后训练缓解策略和更严格的评估框架,以确保自动化新闻内容符合平衡报道的标准。
🔬 方法详解
问题定义:该论文旨在研究大型语言模型(LLM)在生成新闻标题时,是否会比人类作者产生更强的框架偏见。现有方法缺乏对LLM生成新闻内容中框架效应的系统性评估,并且没有充分考虑不同模型架构之间的差异。
核心思路:核心思路是通过对比分析LLM和人类生成的新闻标题,量化并比较它们在不同情境下的框架偏见程度。通过分析不同模型架构的输出,揭示模型特性与框架偏见之间的关系。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:收集人类撰写的新闻标题作为基准;2) LLM生成:使用不同的LLM(包括开箱即用和微调的模型)生成新闻标题;3) 框架效应量化:设计指标来量化新闻标题中的框架效应;4) 对比分析:比较LLM和人类生成标题的框架效应,并分析不同LLM之间的差异。
关键创新:该研究的关键创新在于系统性地评估了LLM在新闻标题生成中的框架效应,并揭示了LLM可能比人类作者产生更强偏见的风险。此外,该研究还关注了不同模型架构对框架效应的影响,为后续研究提供了有价值的参考。
关键设计:论文的关键设计包括:1) 选择具有政治和社会敏感性的新闻主题,以突出框架效应;2) 设计合适的指标来量化框架效应,例如情感倾向、关键词选择等;3) 使用多种LLM模型进行实验,以评估不同模型架构的影响;4) 采用统计方法进行显著性检验,以验证实验结果的可靠性。
🖼️ 关键图片
📊 实验亮点
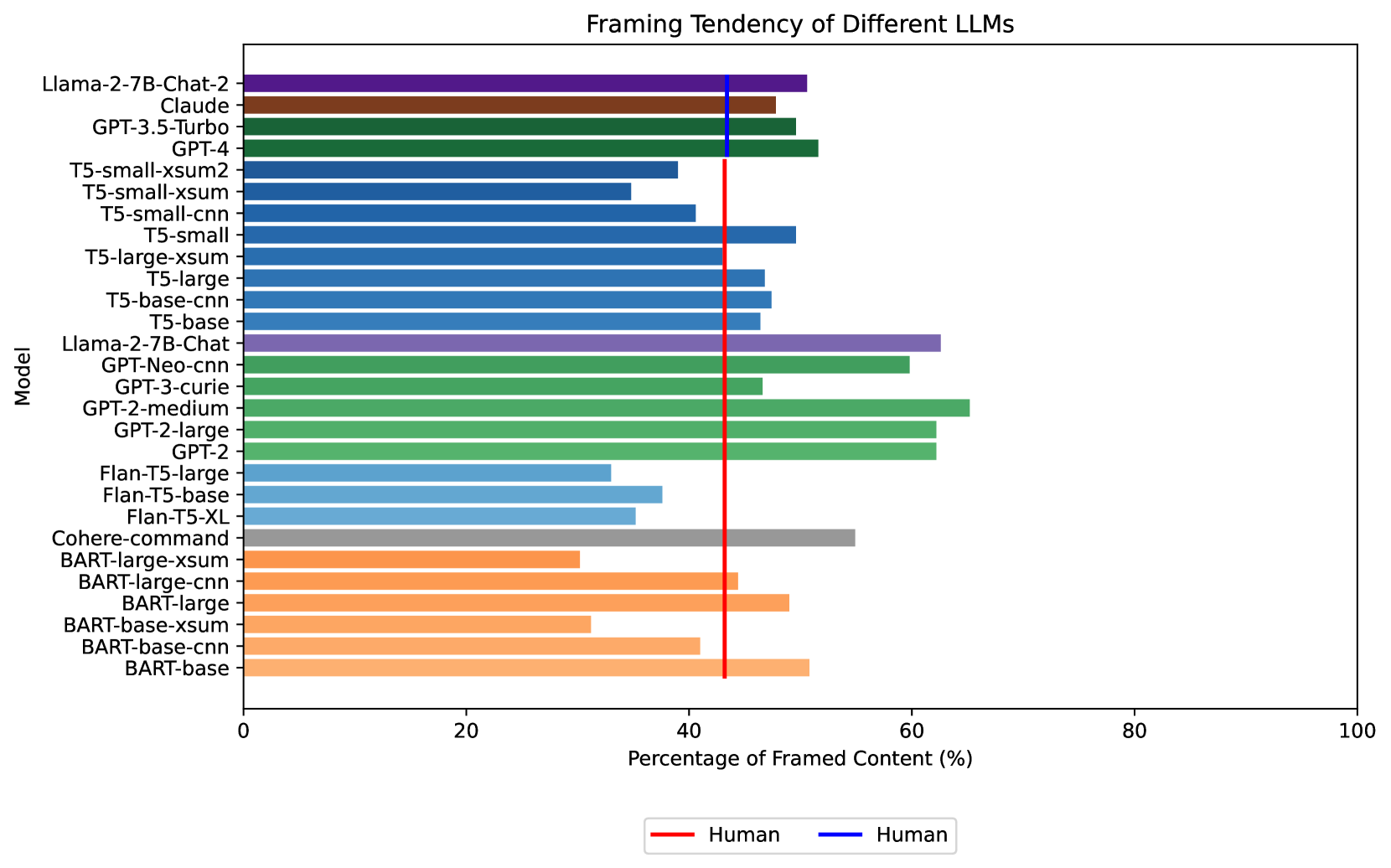
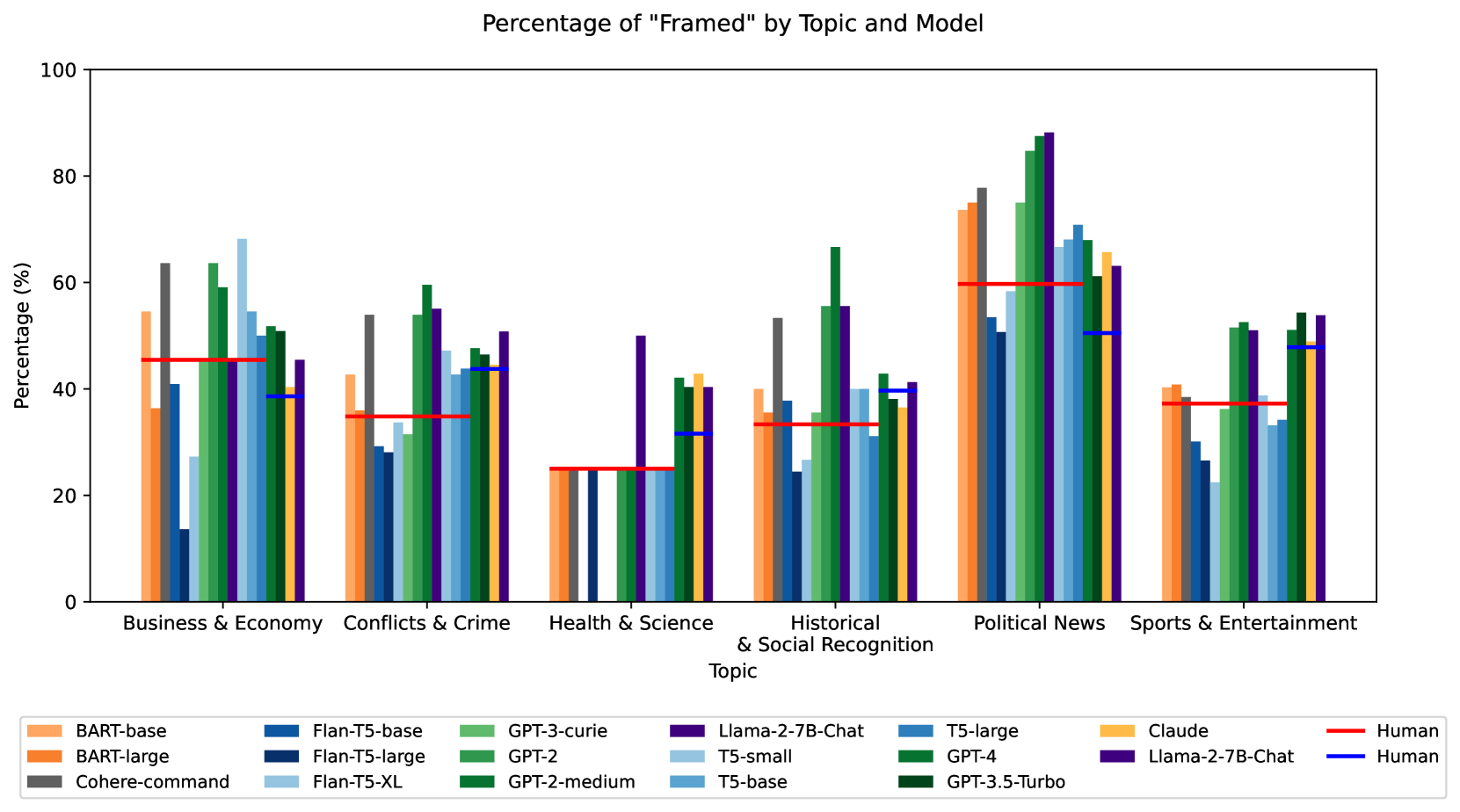
研究发现,在政治和社会敏感的背景下,LLM生成的新闻标题比人类作者更容易表现出框架偏见。不同模型架构之间存在显著差异,某些模型表现出明显更高的偏差。这些结果表明,需要针对LLM生成新闻内容的偏见进行有效的后训练缓解和更严格的评估。
🎯 应用场景
该研究成果可应用于新闻媒体、内容审核和AI伦理等领域。通过了解LLM生成新闻标题的潜在偏见,可以开发相应的缓解策略,例如后训练调整或更严格的评估框架,以确保自动化新闻内容符合客观、公正的报道标准。这有助于提升公众对AI生成内容的信任度,并促进负责任的AI应用。
📄 摘要(原文)
Framing in media critically shapes public perception by selectively emphasizing some details while downplaying others. With the rise of large language models in automated news and content creation, there is growing concern that these systems may introduce or even amplify framing biases compared to human authors. In this paper, we explore how framing manifests in both out-of-the-box and fine-tuned LLM-generated news content. Our analysis reveals that, particularly in politically and socially sensitive contexts, LLMs tend to exhibit more pronounced framing than their human counterparts. In addition, we observe significant variation in framing tendencies across different model architectures, with some models displaying notably higher biases. These findings point to the need for effective post-training mitigation strategies and tighter evaluation frameworks to ensure that automated news content upholds the standards of balanced reporting.